삼성동 코엑스에서 진행하는 AWS Industry Week를 다녀오고 난 뒤 몇가지 세션들에 대한 후기를 작성하고 있습니다.

지난 마이리얼트립 EKS기반 데이터서비스 플랫폼 구축사례 후기 보러가기
2022.11.05 - AWS Industry Week 후기 1 - 마이리얼트립 데이터서비스 플랫폼 구축
AWS Industry Week 후기 1 - 마이리얼트립 데이터서비스 플랫폼 구축
지난주 목요일 삼성동 코엑스에서 진행하는 AWS Industry Week 에 다녀왔습니다! 대부분 추상적인 기업사례만 소개할 것 같아서 사실 큰 기대는 안했지만, 기업에서 직접 나오셔서 설명해준 사례는
pearlluck.tistory.com
AWS Industry Week는 여러가지 산업군들에 대해서 동시에 진행되었는데요, 참고로 저는 아래와 같은 세션을 선택해서 들었습니다!
그 중에서 티빙에서 진행한 세션이 인상깊어서 후기를 공유해볼까 합니다!
티빙 - Data Analytics 부터 개인화추천까지
우선 후기에 앞서서 발표 진행방식이 인상 깊었던 세션이였습니다.
AWS 솔루션 아키텍트 분이 전반적인 머신러닝 워크플로우를 설명해주시고, 이 흐름에 맞춰서 티빙의 데이터엔지니어와 사이언티스트분들이 어떻게 작업하고 협업하는지를 설명해주셨습니다. 덕분에 실무에서 일하고 있는 입장에서 더 와닿았고 이해하기 쉬웠습니다.
그리고 데이터사이언티스트와 엔지니어가 각각 이야기해주시면서 우리팀에서 R&R도 한번더 생각하게 되는 그런 세션이였습니다.
참고로 이때 핸드폰 배터리가 다 나가는 바람에..관련 사진들은 아무것도 없는 점 양해부탁드립니다..(아이폰 미니 진짜 버리자ㅠㅠ)
머신러닝 워크플로우
머신러닝 워크플로우는 일반적으로 아래와 같은 과정을 통해 진행이 됩니다.
데이터 탐색 및 준비 -> 모델 학습 및 튜닝 -> 모델 평가및 검증 -> 모델배포 -> 비즈니스 문제가 해결되었는지 확인 -> 다시 데이터탐색
이 플로우에 따라서 티빙의 데이터엔지니어와 데이터사이언티스들이 어떻게 일하는지를 알 수 있었다.
실제 현업에서 일하고 있어서 일할때 상황을 떠올리면서 우리는 잘하고 있나..? 를 생각해볼 수 있었다. 그래서 그런지 만약 데이터엔지니어나 데이터사이언티스트를 생각하고있는 분들에게는 업무에 대해서 미리 파악해볼수 있는 좋은 세션일 것 같다..!!
데이터탐색 및 준비
티빙은 (내가 유일하게 이용하는) OTT서비스로, 개인화 추천과제를 진행하고 있다.
개인화라고 하면, 사용자에게 무슨 콘텐츠를 추천할지? 누구한테 무엇을 개인화해야할지? 라는 과제를 담고 있다.

이 과정에서 데이터사이언티스트들은, 모델 일반화를 목표로 하는 데이터셋을 구성해야한다.
사실 티빙의 개인화 데이터들은 '가변적'이라는 특성을 가지고 있다고 한다.
개인의 취향 뿐만 아니라 최신 인기성향을 기반으로 변동적인 성향이 있다. (우리랑 꽤 비슷할지도?)
그러다보니 리서치를 통해 파악한 이론들이 실제 데이터를 가지고 적용될 수 있는지, 가능성이 타당한지 이런 실험이 지속되는 경우가 많다.
그래서 데이터사이언티스들에게는 데이터파악을 위한 비용이 계속 증대되며 병목지점이 되었다.
이때 데이터엔지니어와 협업하여 데이터를 추출한다.
데이터엔지니어는 사이언티스트들이 원하는 데이터가 어디에 있는지 더 잘 알기 때문이다.
그래서 데이터허브를 통해 모델에 적합한 데이터가 있는지 쉽게 찾아주고, 해당 데이터를 함께 추출한다.
또한 데이터사이언티스트가 필요한 데이터를 전처리하거나, 추출한 데이터를 s3에 적재하기도 한다.
데이터사이언티스트들이 데이터셋을 구성하기 위한 요구사항을 알고 있고,
데이터엔지니어들이 데이터들이 어디에 어떻게 있는지 잘 알고 있기 때문에
데이터탐색 및 준비과정에서 이 둘의 협업으로 진행한다.
모델 학습 및 개발
이렇게 필요한 데이터가 준비가 되면 데이터사이언티스트들은, 모델을 학습하고 개발하는 과정에 들어간다.
이때 티빙의 데이터사이언티스들에게 co-workspace가 필요했다고 한다.
이 부분이 우리팀의 상황과 너무 유사해서 굉장히 공감이 갔다!
티빙에서 또한 다양한 모델과 다양한 요구사항 때문에 사이언티스트들마다 개발환경이 통일되지 않았다고 한다. 그러다보니 사이언티스트들간에 피드백도 어려웠다고 하는데 이를 위해 문서작성에 많은 시간을 투자했다고 한다. 즉, 보고를 위한 보고를 진행한 셈이다.
티빙에서는 sagemaker studio를 통해 기본적으로 데이터사이언티스들간의 모델 개발환경을 통일시켰다.
사이언티스트들마다 다른 환경을 패키지 코드로 통합시켰고, 공통적인 주피터랩을 사용하는 방향으로 진행했다.
또한 기존에 사이언티스트들이 실험을 기초로 모델을 개발하다보니 배포버전과 디팬던시가 맞지 않는 문제도 많았는데
컨테이너 이미지 기반으로 개발환경을 통일시켜서 이러한 부분들이 개선이 되었다고 한다.
뿐만 아니라 studio에서 제공해주는 ml 파이프라인과 모니터링 툴을 사용해서 내가 담당한 모델이 아니여도 다른 팀원의 모델장애 대응까지 대처할수 있게 되었고, 심지어 sagemaker experiments를 통해 사이언티스트들간의 커뮤니케이션에도 도움이 되었다고 한다.


이렇게 사이언티스트들이 여러 모델을 개발하면, 데이터 엔지니어들은 모델을 관리한다.
이때 티빙의 데이터엔지니어들은 다양한 모델을 하나의 패키지에서 관리했다고 한다.
아무래도 여러명의 사이언티스들이 모델을 개발하면서 모델간에 데이터셋을 공유하거나, 중복되는 코드들도 많을 수 밖에 없다.
그리고 공통기능이 필요한 경우는 각자의 작업자들이 하나씩 모델에 각각 적용해야하는 번거로움이 있었다.
이러한 문제점 또한 sagemaker를 사용하면서 하나의 패키지에서 여러 모델을 관리할 수 있도록 하면서
사이언티스트들은 모델개발에, 엔지니어는 모델관리에 집중하도록 R&R이 나름 구분되었다.
티빙에서는 로그데이터를 전환하는데 Amazon MSK 서비스를 사용한다고 한다.
managed kafka서비스로 실시간 시청로그를 받고 있고, nifi로 스파크 배치를 돌리면서, dw에 저장하고 있다고 한다.
사실 msk는 처음들어봤는데 생각보다 aws기반의 카프카를 많이 쓰는구나..!
모델배포
AWS CodeCommit 서비스를 사용해서 코드푸쉬를 하고, 코드병합이 되면 젠킨스로 자동빌드를 해서 AWS ECR에 이미지를 적재한다.
그리고 airflow에서 task별로 적절한 이미지를 선택해서 task를 수행하도록 한다.
(즉 이미 학습한 결과를 이미지로 만들어두고, 주기적으로 배치를 돌린다는 뜻이다!)
AWS sagemaker의 training job 을 사용해서 실제 모델 학습을 돌리고, 전반적인 로깅은 전부 AWS에서 확인하는 듯했다.
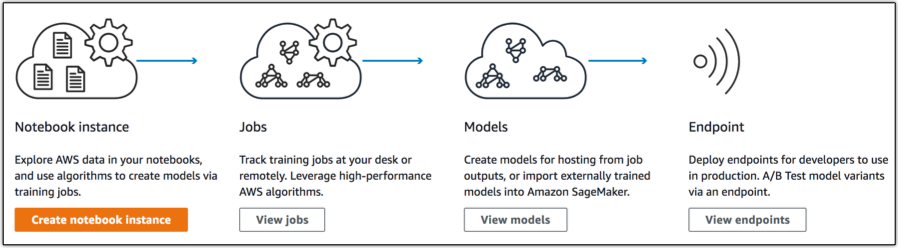
이렇게 모델 배포까지 끝내면, A/B 테스트를 통해서 적합한 모델을 선택한다. 그리고 aws의 quicksight로 성과지표까지 추적할 수 있따.
굳이 aws 코드커밋이랑 quicksight까지 사용하는걸 보고,, 이 회사..돈 많을지도..? 라고 잠시 생각했다..ㅎㅎ
성과 및 한계
이렇게 모델개발 프로세스를 확립하고, 초기에 7개월이 걸렸던 모델배포 사이클이 지금은 1~2개월로 단축이 되었다고 한다.
하지만 여전히 몇가지 한계점도 있다고 한다.
그중에서 사이언티스트분이 말씀해주신 ipython과 cypthon의 환경차이로 인한 한계점을 말씀해주셨는데 이것도 공감이 됐다.
주피터 노트북 환경의 ipython으로 사이언티스트들이 문제없다고 개발했다고 하지만, production 수준의 코드를 배포하려고 cpython 환경에서 작업하는 데이터엔지니어들에게는 문제가 발생할 수 도 있다는 점이다.
느낀점
일반적인 머신러닝 워크플로우에 맞춰서 데이터엔지니어와 사이언티스트들간의 역할에 대해서 잘 설명해주셨다.
그러다보니 우리팀의 엔지니어와 사이언티스들은 잘 하고 있는가? 앞으로 어떻게 협업해야하는가?에 대해서 되돌아볼 수 있었다.
특히 우리팀은 데이터탐색 및 준비 과정에서 엔지니어 개입이 전혀 없다. 그러다보니 어느정도 사이언티스트들에게 부담이 되는게 사실인데, 티빙처럼 이렇게 협업하는 방식으로 진행하는것도 괜찮아보인다...!
그리고 사이언티스트들간의 협업이 어려운 부분이 개발환경이 통합되지 않아서 그런게 아닐까 싶은 생각도 든다. 그래서 티빙처럼 모델개발 과정에서부터 개발환경 통일이 되면 생각보다 편리할 것 같다. 물론 세이즈메이커 스튜디오를 사용하는데 돈이 쬐금 들지도..?ㅎㅎ
'🪴 UI UX > InterViews' 카테고리의 다른 글
| 🙊 AWS Industry Week 후기 1: 마이리얼트립, 데이터서비스 플랫폼 구축 (0) | 2022.11.06 |
|---|---|
| 무신사 크림 가품 논란 총정리, 무신사도 피해자다? (1) | 2022.04.04 |
| 카카오가 소개하는 데이터엔지니어링(DatatEngineering) (0) | 2021.07.14 |
| [대표인터뷰] 카카오페이, '핀테크 플랫폼' 자신감의 근거 (0) | 2021.07.06 |
| [대표인터뷰] 플로(FLO)드림어스컴퍼니 5년만에 흑자전환 | 개인화 맞춤 서비스 (0) | 2021.06.03 |
| 쏘카 데이터엔지니어가 하는 일- 4.데이터그룹의 인프라/리소스 관리 (0) | 2021.05.22 |



