아래의 카카오 블로그에서 소개한 내용을 바탕으로 작성된 글입니다.
자세한 내용은 카카오 기술블로그를 참고해주세요!
https://tech.kakao.com/2020/11/30/kakao-data-engineering/
데이터 엔지니어링이란
안녕하세요, 데이터정보플랫폼팀 kenny입니다.카카오는 매년 신입 개발자 공채와 인턴 프로그램을 진행합니다. 카카오 그리고 데이터 엔지니어링에 관심 있는 주니어 개발자 또는 예비 개발자분
tech.kakao.com
데이터엔지니어링이란?
사실 회사마다 정의하는 업무도 다르고 개인별로 상상하는 바도 다르다.
우선 위키피디아에서 검색해보면 information engineering과 Data Science가 나완다.
좀더 구제체적으로
James Furbush의 글 Data engineering: A quick and simple definition 에서 보면 아래와 같이 정의되어 있다.
As the data space has matured,
data engineering has emerged as a separate and related role that works in concert with data scientists.
데이터 분야가 발전함에 따라 분화가 되었고, 데이터 사이언티스트와 협업하는 업무라니..?
왜 생겨났는가? 빅데이터
조금더 구체적으로 데이터엔지니어링에 대해 알아보기 위해 빅데이터가 뜬 이야기부터 시작한다.
예전에는 사용자나 매출처럼 중요하다고 생각한 데이터 위주로 분석하고, 그 외의 데이터는 버려졌다.
필요없는 데이터까지 저장하거나 사용하면 저장비용이 많이 들었고,
저장을 하더라도 분석할 환경이 갖춰지지 않았고, 분석을 하더라고 그 가치를 인정받지 못했기 때문!
그러던 언제부턴가 저장하지 않거나 사용하지 않아서 버려지는 데이터를 가지고 돈을 벌기 시작했다.
서비스 개선에 활용하고, 광고와 마케팅으로 쓰일수 있다는게 알려지면서, 데이터에 대한 관심이 커졌따.
그래서 이런 데이터들이 많아 빅데이터라고 불리게 되었고,
빅데이터를 분석하려면 기존과 완전히 다른 접근을 해야해서 관련기술과 단어들이 점점 생겨나기 시작했따.
그런데 빅데이터는 어느정도 크기를 의미하는가?
사실 명확한 정의는 없지만 기존 RDB에서 처리할 수 없을 정도의 크기를 빅데이터라고 볼 수 있다.
대략 수십테라 이상의 데이터, 기존 RDB가 아닌 다른기술을 사용한다.
그래서 데이터엔지니어링은?
결국 데이터엔지니어링을 딱 떨어지게 정의할 순 없지만 대략 정리하면 이렇다.
빅데이터분석은 기존분석방법과 달라서 데이터엔지니어링과 데이터사이언스로 전문화 되어 있다.
그래서 데이터엔지니어링과 데이터사이언스가 협업을 하는 관계로 빅데이터분석을 할 수 있게 된다.
앞으로 데이터의 가치는 더더욱 중요해질 것이고, 데이터는 더 많이 생겨날 것이다.
그러니까 앞으로도 데이터엔지니어와 데이터사이언티스트는 많이 필요하다!
데이터엔지니어와 데이터사이언티스트
사실 이 둘은 종종 업무가 중첩되기도 한다.
아래의 그림에서 보는 것처럼 분석, 프로그래밍, 빅데이터는 겹치는 부분에 해당한다.
물론 해당 회사의 성격과 조직의 상황에 따라 달라질 수 도 있다. 심지어 따로 데이터조직이 없을 수도.
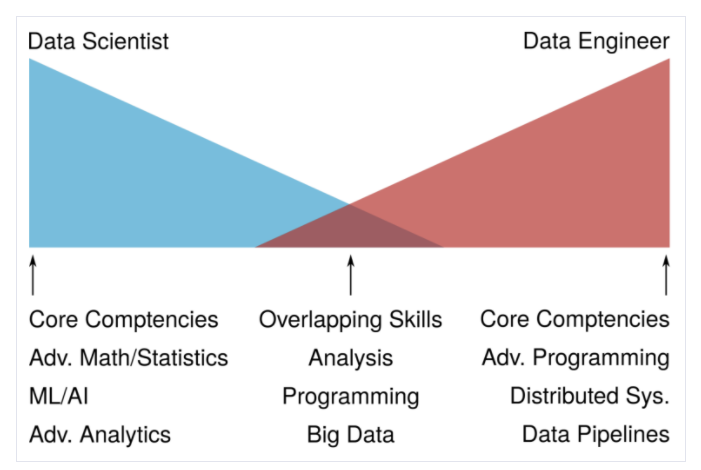
위 그림을 통해
본인이 데이터에 관심이 많은 프로그래머라면 데이터엔지니어가 적합하고,
본인이 데이터에 관심이 많은 분석가라면 데이터사이언티스트에 적합하다는 것을 알 수 있다.
카카오에서 데이터엔지니어가 하는일
카카오의 수많은 서비스들의 데이터는 데이터파이프라인으로 모인다.
그리고 이렇게 모인 데이터는 쓰기 편하고 안전한 형태로 가공이 되어 저장이 된다.
그래서 이 빅데이터를 활용해 서비스에서 의사결정을 할 수 있는 분석시스템을 만든다. 까지 데엔이 한다.
그 이후 이 데이터사이언티스트가 이 데이터를 고도화하여 분석하고, AI/ML같은 업무를 수행한다.
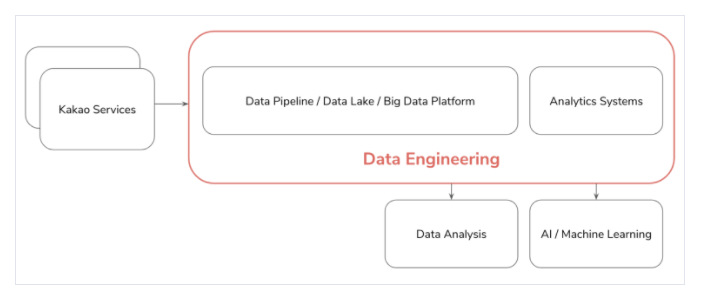
카카오 데이터엔지니어에게 필요한 능력과 업무
수집/가공/저장
수많은 서비스에서 생산된 수많은 데이터를 모을 수 있도록 데이터파이프라인을 설계/구축한다.
모두가 쉽고 안전하게 다룰 수 있도록 가공/처리하여, 데이터성격에 따라 스트리밍 혹은 배치처리를 한다.
스트리밍 데이터를 모으기 위해서는 Logstash, fluentd 같은 수집기, kafka와 rabbitMQ같은 MQ를 사용한다
스트리밍 데이터를 가공하기 위해서는 storm, flink, spark streaming을 사용한다.
배치처리를 위해서는 주로 hadoop MR, hive, Spark를 사용하고 용도에 따라 다르다.
프로그래밍이 필요할 경우는 python ,scala, java같은 언어를 주로 사용한다.
분석
저장된 데이터에서 hive 등의 쿼리로 일회성 분석을 하기도 한다.
그래서 데이터엔지니어는 쿼리에 대한 이해가 필요하다.
시각화툴을 사용하여 self service BI환경(직원 누구나 접속하여 분석할 수 있는 환경)을 개발하기도 한다.
협업
심화된 분석, ML, AI 를 하는 데이터사이언티스트와 협업도 필요하다.
어떤 데이터를 쓰고 있꼬, 어떤 데이터가 필요한지를 알아야하기 때문이다.
결국 일이 원활하게 진행된다면 서비스는 점점 사용자가 원하는 콘텐츠를 추천하게 될 것이다.
이게 바로 데이터의 힘.
또한 서비스조직과 협업도 필요하다.
예를 들어 서비스에서 개편을 위해 A/B 테스트를 한다면 여러 가서을 세우고, 실험/분석을 같이 한다.
이후 서비스 개편 후 성과분석 지표를 분석시스템에 나오도록 해서 데이터를 더 수집해야는지 고려해본다.
그래서 성과분석을 할 수 있도록 데이터를 설계하고, 개발을 진행한다.
'🪴 Product Thinking > UX 개념노트' 카테고리의 다른 글
| 결정을 도와주는 '힉의 법칙'이 적용된 UX사례 (0) | 2024.05.11 |
|---|---|
| 🙈 AWS Industry Week 후기 2: 티빙, data 분석부터 개인화 추천까지 (0) | 2022.11.06 |
| 🙊 AWS Industry Week 후기 1: 마이리얼트립, 데이터서비스 플랫폼 구축 (0) | 2022.11.06 |
| 쏘카 데이터엔지니어가 하는 일- 4.데이터그룹의 인프라/리소스 관리 (0) | 2021.05.22 |
| 쏘카 데이터엔지니어가 하는 일- 3.데이터기반 백엔드 서비스 개발 운영 (0) | 2021.05.21 |
| 쏘카 데이터엔지니어가 하는 일- 2.데이터지표와 보고서만들기 (0) | 2021.05.21 |



