지난주 목요일 삼성동 코엑스에서 진행하는 AWS Industry Week 에 다녀왔습니다!

대부분 추상적인 기업사례만 소개할 것 같아서 사실 큰 기대는 안했지만, 기업에서 직접 나오셔서 설명해준 사례는 유익하더라구요.
그런데 개인적으로 여러가지 세션이 동시에 진행되다보니까, 그 이동하는 과정이 약간? 어수선했습니다.
타임 테이블에서도 이동하는 시간이 별도로 주어진게 없어서, 세션 진행중에 이동하시는 분들도 많았습니다ㅜㅜ
그리고 하나의 세션당 30분이라서 그런건지 너무 짧다고 느껴져서 아쉬웠습니다. 질문할 시간도 없고 뭔가 촉박한 느낌?
아래와 같이 여러가지 세션이 동시에 진행되는 컨퍼런스였는데, 저는 아래와 같은 세션을 선택해서 들었습니다.
다시 일하러 가봐야해서 마지막 세션은 패스.....하하..
이중에서 특히 마이리얼트립과 티빙에서 진행한 세션이 가장 기억에 남아서 후기를 남겨볼까 합니다!
https://aws.amazon.com/ko/events/industry-week/
AWS Industry Week
리테일 및 이커머스, 미디어 및 엔터테인먼트, 제조, 여행 및 관광, 금융 및 핀테크 및 게임 산업 분야에 계신 모든 분들이 참여 대상입니다. 클라우드에 대한 전문가가 아니어도 각 산업 분야 별
aws.amazon.com
마이리얼트립 - EKS 환경을 활용한 데이터서비스 플랫폼 구축사례
우선 후기에 앞서서 발표자이신 마이리얼트립 데이터플랫폼 팀장님께서 세션 진행을 아주 깔끔하고 명확하게 해주신 느낌을 받았습니다.
마이리얼트립 앱의 각각 아키텍쳐 기반으로 어떻게 구축했는지, 그리고 왜 이렇게 구축했는지를 말씀해주셨습니다.
마이리얼트립의 데이터서비스
마이리얼트립을 한마디로 표현하자면, "나다운 여행을 해주는 슈퍼여행 앱!" 이라고 한다. 안그래도 요즘 코로나가 풀리면서 해외여행을 알아보고 있던 상황이였는데도 불구하고 마이리얼트립이 이런 컨셉으로 서비스를 하고 있는지도 전혀 몰랐다;;;
덕분에 세션을 통해서 마이리얼트립이 데이터기반 서비스로 성장하고 있다는것도 이번 기회에 알게 되었다.
마이리얼트립 데이터 플랫폼 히스토리를 보면 초기에는 dw/mart 파이프라인을 구축하는게 우선시되서 안정적인 분석플랫폼 구축이 목표였다고 한다. 그 이후 로그플랫폼과 cdc를 구축하면서 작년까지만해도 EC2와 ECS를 기반으로 사용자 행동과 실시간 분석을 목표로 하였다. 올해부터 전반적인 인프라를 EKS로 전환하면서 본격적인 데이터기반 서비스를 개발할 수 있는 환경이 되었다고 한다.
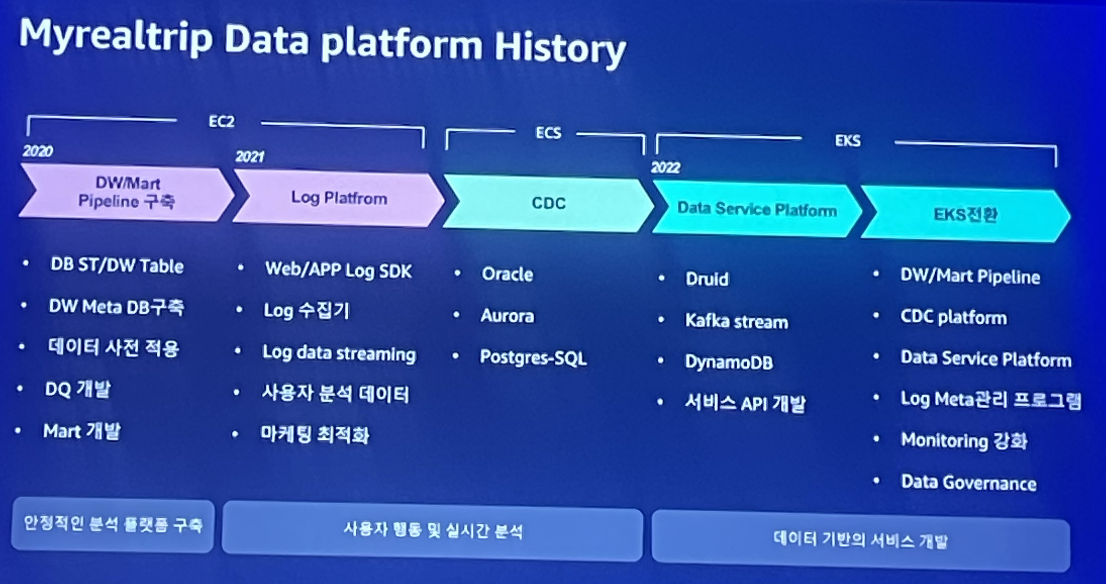
마이리얼트립 데이터플랫폼 아키텍쳐의 핵심은 AWS EKS에서 모든게 돌아가고 있다는게 핵심이다.
Airflow같은 배치플랫폼, Prometheus나 Grafana같은 모니터링, DW나 데이터마트들이 모이는 데이터서비스플랫폼 그리고 CDC까지 관련된 데이터플랫폼을 모두 다 AWS EKS 위에 올렸다. 데이터허브 또한 EKS 위에서 돌아가며, 플랫폼들에서 돌아간 모든 정보들이 데이터허브로 메타정보가 쌓이게 된다.

자체 분석 플랫폼
이전에는 EC2에 직접 ariflow를 올려서 사용했나보다. 그러다보니 관리포인트가 용이하지도 않았고, 리소스가 부족하면 스케쥴러가 망가지기도 했다고 한다. 그래서 별도의 EKS 안에 airflow workspace를 만들고, DAG가 실행이 될때만 EKS에서 띄워지도록 구축했다.
Airflow 메타테이블 정보를 읽어서 자동으로 airflow job 생성 및 실행하는 것이다.

이 과정에서 데이터허브(datahub)를 도입한게 인상깊었다. 테이블의 정보를 모아둔 메타 디비가 따로 있는것이다.
덕분에 자동으로 job을 실행하면서 스키마가 맞는지(description), 어떤 경유로 이 데이터가 왔는지(lineage), 해당하는 레포트는 어떤것인지까지(glossary) 데이터의 퀄리티체크까지 할 수 있다고 한다.
마이리얼트립에선 이렇게 3년동안 진행을 하면서, 데이터 누락 등 이슈로 장애가 딱 한번 있었다고 했다.
메타데이터 설정값을 잘못 넣어서 돌렸던 딱 한번 그렇게 장애가 있었고, 지금까지 단 한번도 장애가 없었다고 자신했다.
안그래도 데이터허브에 관심 있었는데, 한번 이 사례를 레퍼런스 삼아 자체 데이터 분석플랫폼.. 해보고 싶다...!
자체 로그 플랫폼
마이리얼트립은 웹/앱을 통해 수집된 로그들을 Bizglog gateway를 통해 받고, aws kafka로 보내고 있다.
aws kafka가 실시간으로 nifi로 데이터를 보내면, 실시간으로 분석플랫폼에 데이터가 쌓이는 것이다.
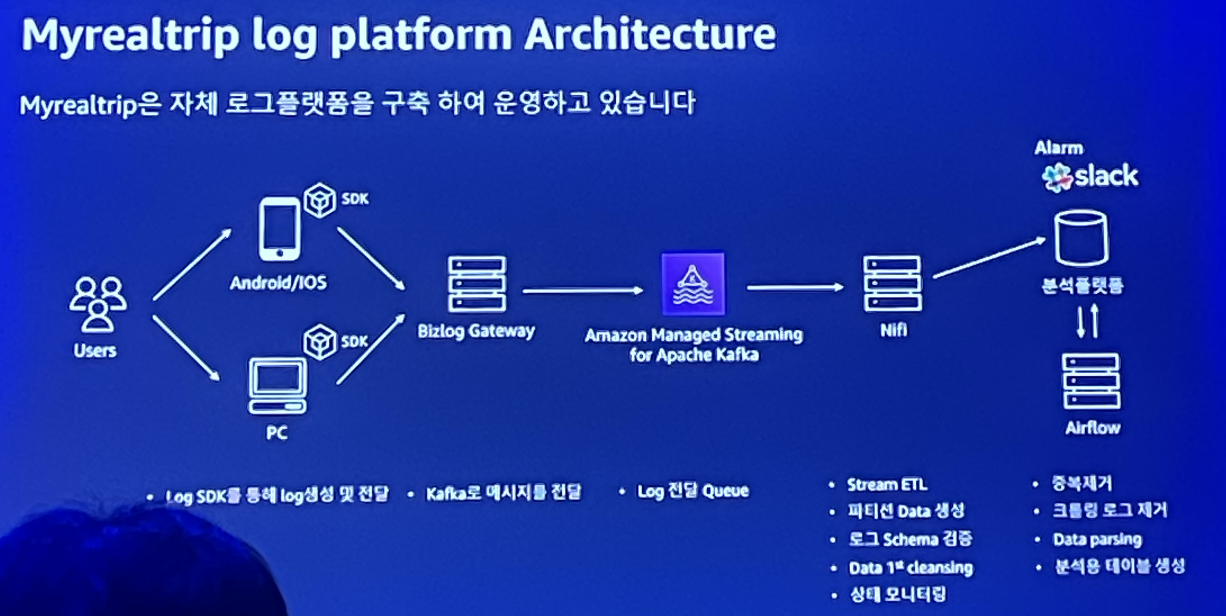
이 과정에서 로그 메타관리 프로그램 을 자체적으로 구축했다고 한다.
분석플랫폼에 모인 데이터들을 가지고 분석가들이 설계를 완료했는지 개발을 완료했는지 체크를 할 수 있고,
어떤 데이터를 가지고 있는지 필터링을 하기도 하고, 데이터가 잘 들어오고 있는지 그래프로도 볼 수 있는 툴? 같다.
정확히 어떤 컨셉인지 감이 안잡히지만 나름 뿌듯해하시면서 오픈소스로 내보낼까 생각중이라고 하니 기대가 된다.
자체 CDC
RDS에 모여 있는 데이터들은 kafak connect를 이용해서 AWS kafka로 보내고 있다.
카프카로 전송된 데이터가 sink connector를 통해 분석플랫폼에 데이터가 쌓이는 것이다.
이때 schema registry를 통해 약속된 규약만 받도록 정했고, 카프카 웹 UI인 redpanda를 사용한다.
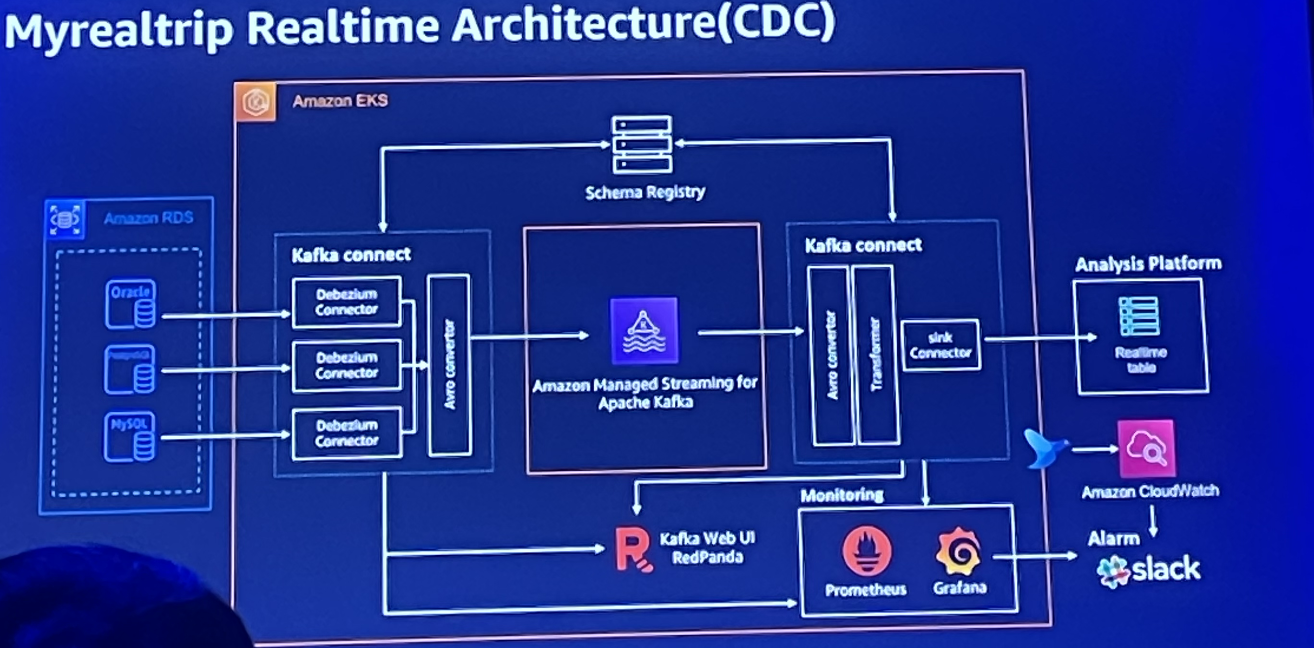
전반적으로 흘러 들어오는 실시간 데이터를 받거나, 카프카 스트림으로 조작하거나, 최근 1년동안 상품 구매자 같은 데이터들을 저장해서
결국에 API 게이트웨이를 통해 사용자에게 서비스화된다. 예를 들어 방금 예약이 발생했어요! 같은 신규 예약 상품이나, 이게 현재 얼마나 팔리고 있는지, 항공권 가격이 적절한지 등 데이터를 조작하여 사용자에게 노출한다.
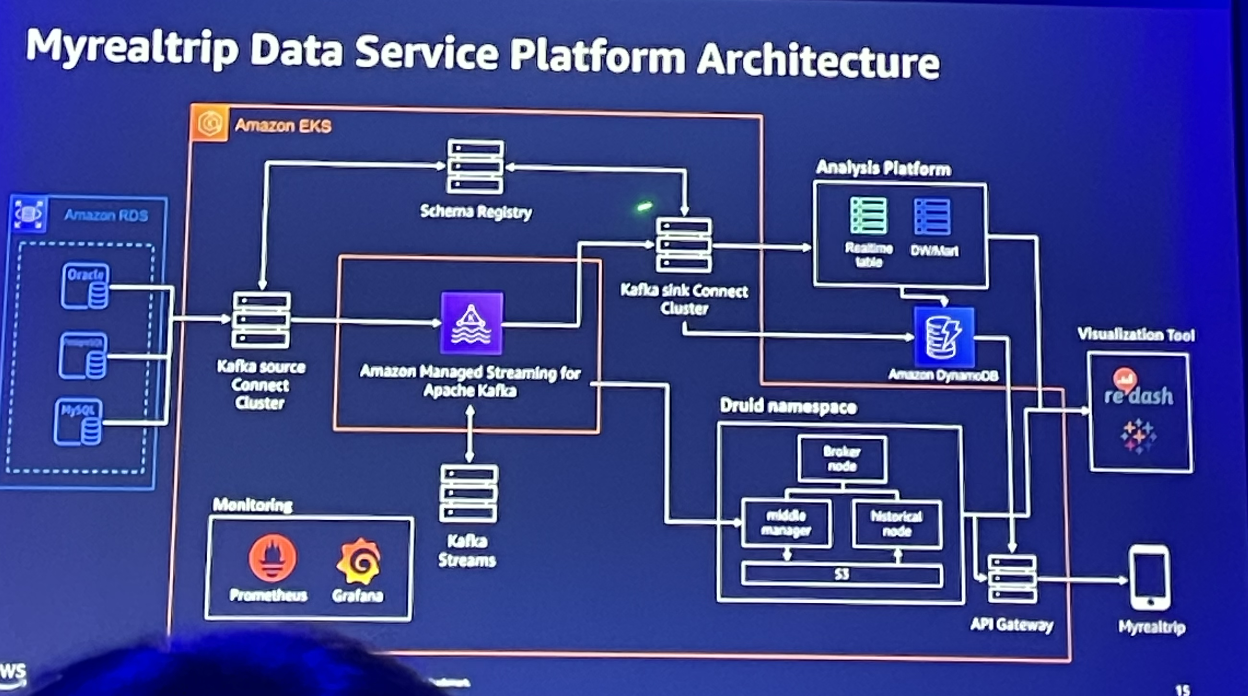
왜 EKS인가? EKS 배포환경
이들이 이렇게 자체 플랫폼들을 모두 EKS에 올린 이유는 아래와 같다.
- 쿠버네티트 환경 구축/운영에 대한 부담을 줄이기 위해
- 분산처리 시스템 특성상 하나의 서비스가 서로다른 N개의 서버에 설치 및 배포 운영에 대한 리소스 절감
- helm을 이용한 IAC(infra as code) 적용으로 인한 서비스 운영비용 절감
- 운영 안정성 확보
- EC2 서버비용 축소
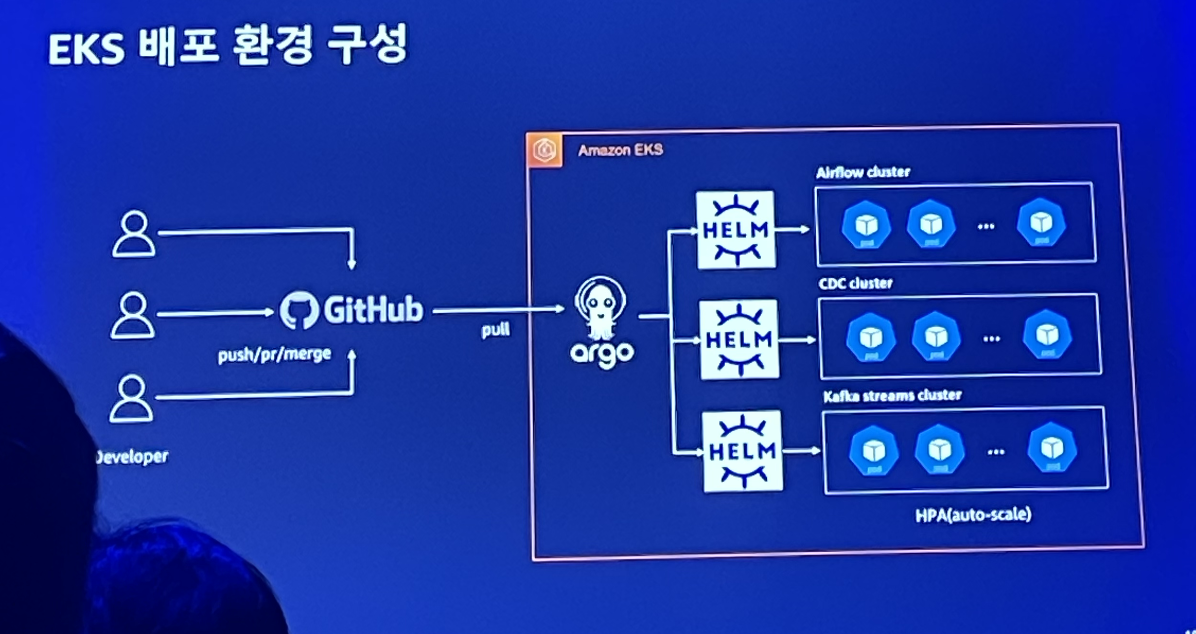
그리고 argo를 통해 깃 씽크를 맞추면, helm을 통해 각 플랫폼에 해당하는 pod를 띄우면서 배포를 한다.
또한 모니터링은 프로메테우스가 지표를 모으고, 그라파타나를 통해 확인한다.
'🪴 UI UX > InterViews' 카테고리의 다른 글
| 🙈 AWS Industry Week 후기 2: 티빙, data 분석부터 개인화 추천까지 (0) | 2022.11.06 |
|---|---|
| 무신사 크림 가품 논란 총정리, 무신사도 피해자다? (1) | 2022.04.04 |
| 카카오가 소개하는 데이터엔지니어링(DatatEngineering) (0) | 2021.07.14 |
| [대표인터뷰] 카카오페이, '핀테크 플랫폼' 자신감의 근거 (0) | 2021.07.06 |
| [대표인터뷰] 플로(FLO)드림어스컴퍼니 5년만에 흑자전환 | 개인화 맞춤 서비스 (0) | 2021.06.03 |
| 쏘카 데이터엔지니어가 하는 일- 4.데이터그룹의 인프라/리소스 관리 (0) | 2021.05.22 |



