이제 거의 다 했다! 고지가 눈앞에 보인다
이번에 해야할 일은 다음과 같다.
1. 카카오톡 챗봇에 데이터 뿌려주기
related_artists 테이블에 있는 아티스트들의 top_track정보를 가져오는 것이다.
그리고 그걸 카카오 챗봇에서 carousel(케로셀) 타입으로 뿌려주기만 하면 된다.
2. 기능테스트
여기까지 테스트를 해보고, 데이터를 더 많이 넣어서 유사도를 확인해볼까 한다.
rds,dynamodb,athena,s3를 다 쓰니까 인프라 비용에 조금 부담되서 후딱 테스트하고 다 지웠다..
3. crontab 자동화처리
그다음에 s3와 athena를 돌려야하는데 이걸 ec2에 넣어서 crontab처리로 자동화를 한다.
carousel(케로셀)타입
이제 related_artists결과를 select해서 뿌려주면 유사한 아티스트의 노래를 알려줄수있게 된다.
그런데 이게 생각보다 오래걸렸다..(아니 카카오톡 챗봇 JSON타입 왜이렇게 헷갈리지 진짜ㅠ)
최종적으로 전달하는 케로셀 타입의 형식은 이렇다.
#Carousl 메세지
def response_carousl(name,listcard_item):
return {
"version": "2.0",
"template": {
"outputs": [
{
"simpleText": {
"text": name+"과 유사한 아티스트의 노래입니다."
}
},
{
"carousel": {
"type": "listCard",
"items": listcard_item
}
}
]
}
}여기에 들어가는 listcard_item은 listcard의 리스트이다.
유사아티스트들의 음악정보들을 리스트형식으로 만든 것이다.
# ListCard 메시지
def list_card(track_result,other_name,dist):
youtube_url = 'https://www.youtube.com/results?search_query={}'.format(other_name.replace(' ', '+'))
#3.list 카드형 : 아티스트의
return {
"listCard": {
"header": {
"title": other_name+ "(유사도: "+str(dist)+")"
},
# get_top_tracks는 아티스트의 id를 이용하여 DynamoDB나 API에서 해당 아티스트의 탑 트랙을 찾는 함수
# ListCard 형태에 맞게 리턴
"items": track_result,
"buttons": [
{
"label": "Youtube에서 검색하기",
"action": "webLink",
"webLinkUrl": youtube_url
}
]
}
}
그리고 여기에 들어가는 item은 음악정보들의 리스트이다.
음악정보들의 하나하나(앨범명, 발매일, 앨범커버 등) top_track정보를 리턴한 track_result의 리스트다..
def get_toptracks_db(id):
#dynanoDB 파티션키 : track_id
#track_result=table.query(KeyConditionExpression=Key('artist_id').eq(id))
select_result = table.scan(FilterExpression = Attr('artist_id').eq(id))
#print(track_result)
#최근 발매된 앨범순으로 정렬
select_result['Items'].sort(key=lambda x: x['album']['release_date'], reverse=True)
items = []
#최근 발매된 3개만
for track in select_result['Items'][:3]:
# ListCard 형태에 맞게 리턴
temp_dic = {
"title": track['track_name'], #타이틀곡명
"description": track['album']['release_date'], #발매일
"imageUrl": track['album']['album_image'], #앨범커버이미지
"link": {
"web": track['track_url'] #스포티파이링크
}
}
items.append(track['artist_name'])
items.append(temp_dic)
print("listcard에 넣는 아이템")
return items
artist, related_artist 조인을 했다.
근데 저렇게 카로셀 타입으로 카카오톡 챗봇으로 뿌려줄 형식을 만들면서 문제가 생겼다.
related_artists에는 비교하는 아티스트id, 유사한 아티스트이id, 거리 칼럼만 있다.
그러다보니까 related_artists을 단순 select하니까 유사한 아티스트의 이름을 알수가 없었다.
이런식으로..Name이 초기엔 없었다.

그래서 생각한 방법은 3가지였다.
1.dynamodb에서 데이터를 select할때 name도 가져온다.
그나마 가장 괜찮을것 같았다. 하지만 문제가 있었다.
get_toptrack_db()로 listcard에 들어갈 형식을 만드는데 그 아웃풋이 item전부다.
name은 item이 아리나 header에 들어가는 내용이기 때문에 파싱을 하거나 별도의 처리가 더 필요해서 번거로웠다.
2.artist 테이블에서 related_arist id로 name을 한번더 가져오려고 select를 또한다.
하지만 이 방법은 최후의 수단이였다. 너무 비효율적이기 때문이다.
related_artists를 select하고, 고작 이름을 가져오려고 또 artist 테이블을 한번더 스캔하는건 아닌것 같았다.
3.그러다 생각한게 조인이다.
테이블을 하나만 스캔(물론 조인이지만..) 하니까 왠지 덜 부하가 들것 같았고, 그리고 사용하기도 훨씬 간편했다.
심지어 유사도까지 select할 수 있으니까 뽑아낼 정보가 더 많았다.
#2.검색한 아티스트와 유사한 음악추천(음악정보가 Dynamodb에서 가져옴)
select_query="SELECT other_artist,artist_name,distance " \
"from related_artists join artists " \
"on related_artists.other_artist = artists.artist_id " \
"where mine_artist ='{}' order by distance desc limit 3".format(id)
cursor.execute(select_query)
related_result = cursor.fetchall()
print(related_result) #(('3HqSLMAZ3g3d5poNaI7GOU',), ('0XATRDCYuuGhk0oE7C0o5G',), ('5TnQc2N1iKlFjYD7CPGvFc',), ('4Kxlr1PRlDKEB0ekOCyHgX',), ('7f4ignuCJhLXfZ9giKT7rH',))
list_card_list=[]
for related in related_result:
other_id,other_name,dist = related[0],related[1],related[2] #추천아티스트id,이름,유사도
related_track_result = get_toptracks_db(other_id) #추천아티스트의 노래정보
list_card_item = list_card(related_track_result,other_name,dist) #listcard 리턴값 (이름추가)
list_card_list.append(list_card_item['listCard']) #음악추천결과 메세지
#print(list_card_list) #추천아티스트 전체의 노래정보
print("최종")
message = response_carousl(list_card_list)
테스트-국내아티스트
그래서 어느정도 완성했다. 검색한 아티스트와 유사한 아티스트들의 노래정보를 케로셀타입으로 나오게 했다.
근데 유사도값이 생각보다 너무 낮다.
디비에 아티스트들이 많이 없어서 그럴수도 있겠지만 느낌상 하나도 안비슷한 아티스들이 나왔넴..

이번엔 해외 아티스트들까지 데이터를 넣어서 테스트해보려고 했따.
처음엔 바로 유사한 아티스트들 정보가 안나와서 뭐가 문제인가 싶었다.
알고보니 s3랑 athena를 안돌렸기 때문이다. 그래서 raw데이터를 수집하고 처리해두는 작업이 자동화가 필요하다.


우선 배치처리를 자동화시키기전에 임의로 s3랑 athena작업이 가능하도록 진행하고 결과를 확인했다.
27일에 국내 아티스트 테스트해서 s3에 저장되어 있고,
하루가 넘어 28일에 해외아티스트를 테스트하려고 하니 객체가 하나더 생겼다.


테스트-해외아티스트
국내 아티스트버전보다 유사도들이 더 낮다.

테스트를 하면서 버그(?)를 찾았다.
아티스트를 입력할때 무조건 Spotify에서 지정한 이름으로 검색해야하는 것이다.
심지어 대소문자 띄어쓰기까지 다 맞아야한다. (망할)
예를들어 Justin Bieber도 bieber로 하면 찾지 못하고, justinbieber도 안되고 무조건 Justin Bieber로 검색해야했다.
물론 국내아티스들도 마찬가지였다.
디비에 항상 스포티파이api로 긁어온 아티스트이름으로 저장되기 때문에 그랬따.
아무튼 그래서 영어이름으로 된 아티스트들을 주로 테스트했다(BTS,BTOB,IU,APINK,ITZY,DAY6)
이걸 수정할 수 있을것 같은데...
배치처리자동화
s3와 Athena를 처리하기 위해 지금은 내가 임의로 코드를 실행시킨다.
그런데 만약에 챗봇서비스를 운영하게 되면 내가 일일이 실행할 수 없게 될 것이다.
Cloudwatch event 크론
그래서 자동으로 스크립트를 돌리기 위해 EC2서버안에 스크립트를 넣어두려고 했으나..! EC2 비용이 걱정됐따.
아무것도 안돌리고 크론만 돌리는데 굳이 ec2를 계속 실행해두는게 낭비라고 생각했다.
그래서 Cloudwatch Event로 규칙을 생성해서 크론을 돌리기로 했다.
s3_datalake 스크립트는 KST기준 오전8시
athena_datamart 스크립트는 s3가 모두완료 된걸 고려해서 KST기준 오전 8시 5분으로 정했다.
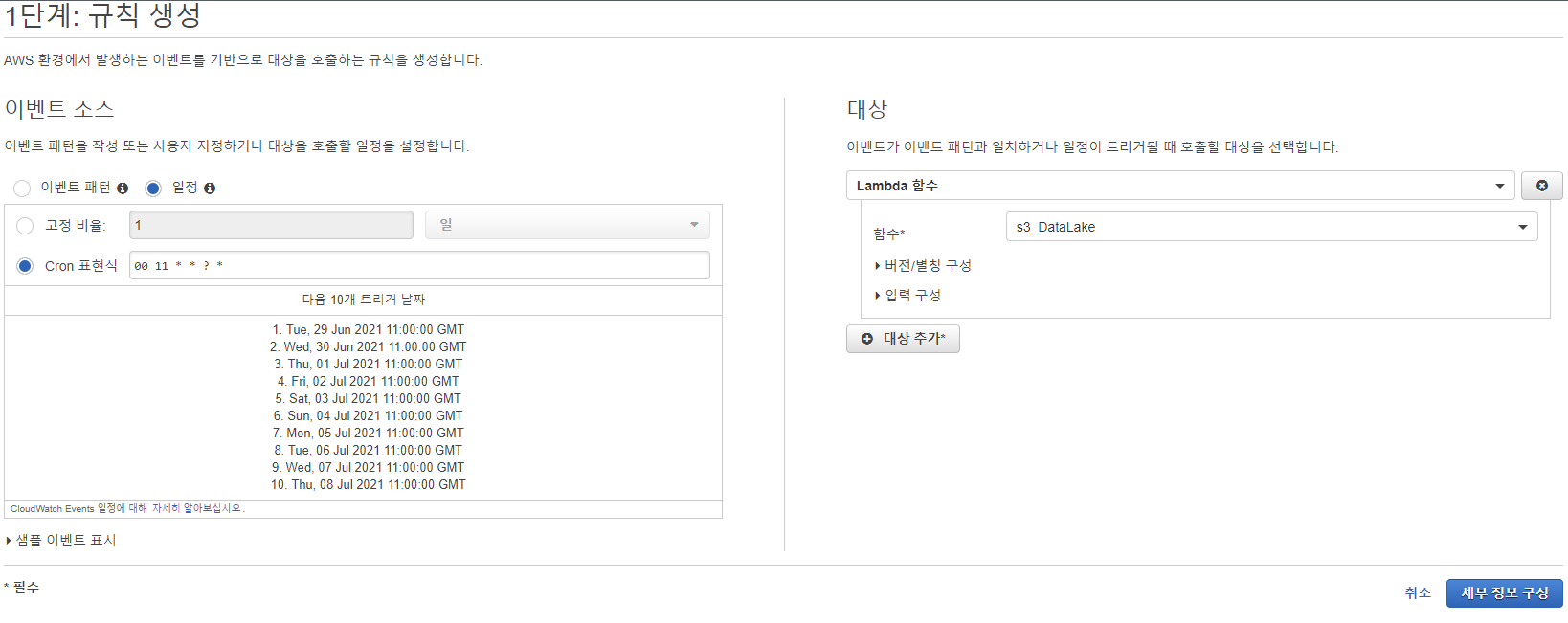
크론규칙은 맨날 찾아본다.. AWS Cloudwatch Event 규칙
참고로 AWS안에서 시간을 걸때는 다 UTC기준이니까 그걸 고려해야한다. >> UTC TO KST
예를 들어 KST기준 오전8시에 크론을 걸고 싶다면 9시간 더 늦은 UTC시간인 오후11시로 바꿔야한다.
물론 기존 python 스크립트에서 lambda_function으로 변형을 해야하기 한다.
근데 뭐 기존 main함수가 lambda_function으로 보면 된다.
라이브러리들도 layer로 추가해줘야하고..추가다하가 이렇게 패키지 의존성문제를 만날수도 있꼬...
pandas와 numpy라이브러리가 너무 커서 layer에도 한번에다 안된다...그리고 넣었다가 numpy가 람다에서 안됐따..

결국 EC2안에 Crontab
아무래도 람다로 돌리기엔 너무 큰 스크립트인것 같다.
그래서 저번에 what's new 크론을 돌리는 것처럼 같은 ec2안에서 crontab설정을 했다.
그리고 생각해보면 parquet 파일도 떨궈야하니까 서버안에서 돌리는게 나을것 같다.
보완할점
이렇게 크론말고, 데이터파이프라인 자동화관리 툴인 airflow를 써보고 싶다.
'사이드 프로젝트 > 음악추천 챗봇 서비스' 카테고리의 다른 글
| 음악추천챗봇10. S3데이터 PySpark처리 및 시각화 (Zeppelin) (0) | 2021.08.09 |
|---|---|
| 음악추천챗봇9. AWS EMR 클러스터구축(Hadoop+Spark+Zeppelin) (0) | 2021.08.07 |
| 음악추천챗봇8. 아티스트 유사도 테스트 수행 및 예외처리 (3) | 2021.07.02 |
| 음악추천챗봇6. Athena 쿼리수행 및 음악 유사도 저장 | 데이터마트 (0) | 2021.06.26 |
| 음악추천챗봇 5.S3에 parquet 형태로 데이터저장 | 데이터레이크 구성 (0) | 2021.06.23 |
| 음악추천챗봇 4.2 DynamoDB 데이터저장 및 1차 테스트 완료 (0) | 2021.06.19 |



