지금까지 스포티파이API를 통해 수집한 데이터들을 RDB(AWS RDS) 와 NoSQL(AWS DynamoDB)에 저장했다.
이번엔 AWS의 Obejct스토리지인 S3에 저장해볼 것이다.
엄밀히 말하면 DataLake를 구현하는 것이다. 모든 정형,비정형데이터들을 그대로 저장하는 것이다.
aws에서 S3를 이용해 DataLake를 구축하는 것은 aws공식블로그를 참고했다.
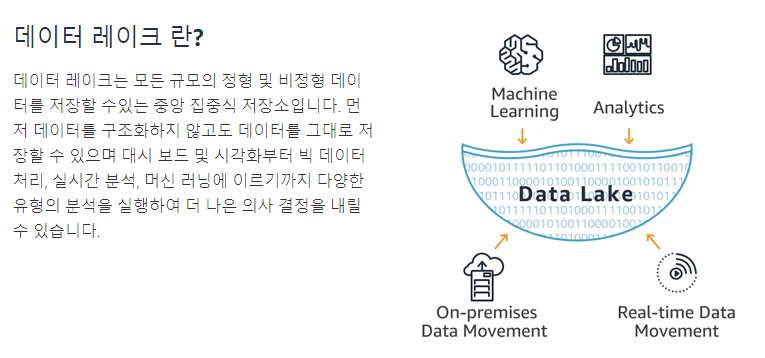
그리고 데이터레이크에 저장된 데이터들로 유사도를 계산해 음악을 추천하는 기능을 구현할 것이다.
유사도를 계산하는 방식은 이곳을 참고했다.
아티스트별 인기 트랙들(top_tracks)의 음원 정보(audio_features)를 이용하여 아티스트간 거리를 계산하고,
사용자가 입력한 아티스트와 유사도가 큰 (=거리가 가까운) 아티스트의 음악을 리턴하는 것이다.
아티스트 데이터가져오기
현재 챗봇을 통해 아티스트를 검색하면, 그때마다 mysql에 아티스트 정보를 저장한다.
이 배치처리시점에서의 데이터를 가져온다.

S3에 데이터 저장하기 : Top_Track 데이터
일반적인 RDS나 Dynamodb와 다르게 s3에 데이터를 저장하는 과정에는 몇가지 특징이 있다.
-API 쿼리결과가 json형태로 반환된다.
-S3에 저장할떄 JSON을 그대로 저장하는 대신 Parquet형식으로 저장한다.
Parquet(파케이) 형식
2021.06.26 - 🌲Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기
🌲Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기
어떻게 알게 되었나? 보통 수집한 데이터들은 정형데이터, 비정형데이터에 따라 RDB나 NoSQL로 저장했다. 그런데 데이터레이크를 만들면서 객체스토리지인 s3에 데이터를 저장해야했다. 사실 처음
pearlluck.tistory.com
컬럼기반 포맷으로, 압축률이 높고 일부 컬럼만 읽을수 있어서 처리량을 줄일 수 있다.
- S3에 저장한 데이터를 Athena라는 Presto기반 쿼리엔진으로 쿼리한다.
하지만 Athena는 파케이형태의 데이터에선 json처럼 계층구조를 가진 nested 필드를 지원하지 않는다.
그래서 계층구조를 가지고 있는 API데이터에서 필요한 컬럼만 추출한 형태로 변환하려고 jsonpath 라이브러리 사용
Parquet를 위한 데이터변형
toptrack의 raw데이터는 계층형 데이터이다.
아래의 데이터처럼 json의 value로 단순한 string이 아니라 또다시 json이 들어가는 구조인 것이다.
그래서 parqet형태의 데이터로 변경하기 위해 flat하게 만들어야한다.

1) toptrack 데이터를 flat한 형태로 변환하기->dict형태
(변경) athena 트러블슈팅을 하며 이후에 변경된 사항인데 parquet형식안에 [] 같은 array타입이 있어서 오류가 났다.
그래서 초기에 dict형태로 변형할때, 각 컬럼에 대한 값을에 []형식이 아닌 string으로 변경하기 위해 value[0]으로 변경!
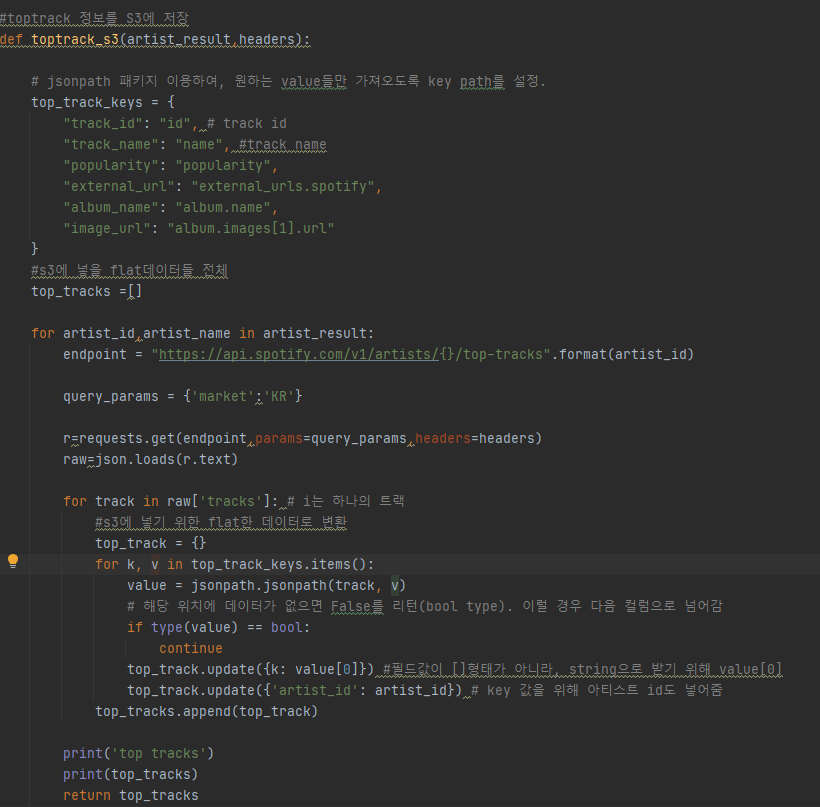
그럼 json으로 계층형이였던 데이터가 아래와 같이 flat한 타입으로 변환이 된다.
{
"track_id":["2bgTY4UwhfBYhGT4HUYStN"],
"artist_id":"3Nrfpe0tUJi4K4DXYWgMUX",
"track_name":["Butter"],
"popularity":[95],
"external_url":["https://open.spotify.com/track/2bgTY4UwhfBYhGT4HUYStN"],
"album_name":["Butter (Hotter, Sweeter, Cooler)"],
"image_url":["https://i.scdn.co/image/ab67616d00001e026bb2b8231817c8d205d07fb2"]
}
다시한번 변경된 사항이다! 위의 형식대로 flat한 타입일 경우 athena에서 오류가난다.
따라서 저렇게 된 형식이 아니라 이렇게 된 형식으로 변경해야한다.
[
{
"track_id":"2bgTY4UwhfBYhGT4HUYStN",
"artist_id":"3Nrfpe0tUJi4K4DXYWgMUX",
"track_name":"Butter",
"popularity":95,
"external_url":"https://open.spotify.com/track/2bgTY4UwhfBYhGT4HUYStN",
"album_name":"Butter (Hotter, Sweeter, Cooler)",
"image_url":"https://i.scdn.co/image/ab67616d00001e026bb2b8231817c8d205d07fb2"
},
{
2) dataframe형태로 변형후, parquet형태로 떨굼 -> top-tracks.parquet파일
(변경) 위에서 변경됨에 따라 dict형태를 만들때 [0]을 넣지 않고 그대로 track['track_id']를 가져오도록 수정했다.

3) s3에 저장
이때 dt로 파티션을 자동생성하여 저장할 수 있게
버킷의 경로가 audio-features/dt={}/audio_features.parquet 가 된다.
그러면 날짜를 기준으로 구분할 수 있게 되고, athena에서도 dt를 기준으로 쿼리할 수도 있게 된다.

date_time = datetime.utcnow().strftime('%Y-%m-%d') # UTC 기준 현재 시간으로. "2020-08-01" 형태
s3_object = S3.Object(Buket_name, 'top-tracks/{}/top_tracks.parquet'.format(date_time)) # 새로운 폴더(파티션)가 생성이 되는 것
data = open('top-tracks.parquet', 'rb')
s3_object.put(Body=data)
print("top track s3에 저장 ")
S3에 데이터 저장하기 : Audio 데이터
audio 데이터는 스포티파이 API에 의한 RAW 데이터가 FLAT한 형태이다.
그래서 굳이 따로 변경해주는 작업은 필요없고 바로 사용하면 된다.
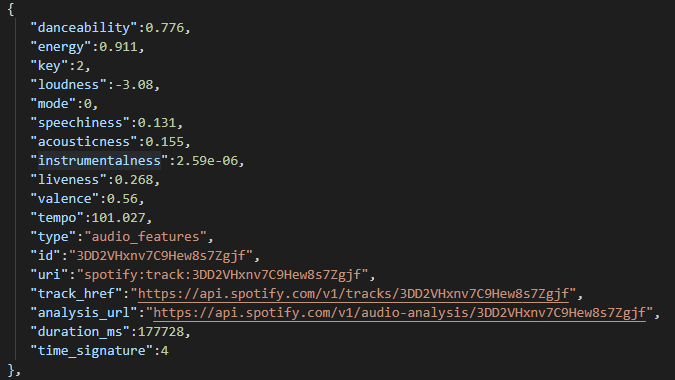
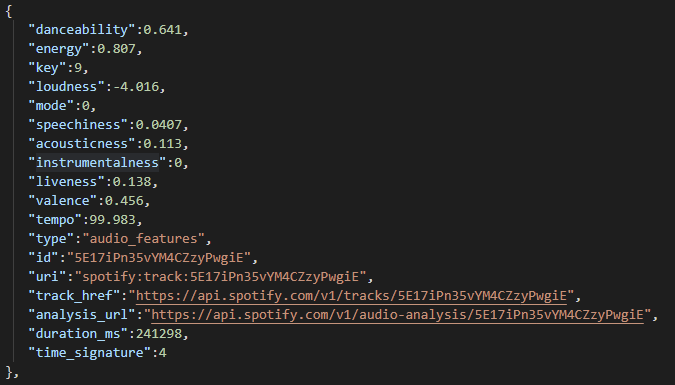
1) toptrack 데이터를 flat한 형태로 변환하기->dict형태
1) 타입을 통일한 dict형태로 변환하기
대신 key중에 instrumentalness 이라는 녀석이 나중에 타입 떄문에 아테나로 쿼리할때 조금 문제가 있었다.
그래서 float타입으로 통일시키고 raw 데이터를 그대로 s3에 저장하도록 했다.

2) track id를 100개씩 묶어서 처리한다.
실제로 데이터를 확인해보니 아티스트당 최소 10개의 노래정보를 가지고 있었다.
만약 5명의 아티스트가 저장되어 있을 경우 track_id는 50개 되는 것이다.
그런데 문제는 스포티파이 API에서 음악메타데이터에 필요한 파라미터가 track_id이다.
그러다보니 일일이 track_id에 대하여 api호출이 필요하게 되어 100개씩 쪼개서 수행하도록 했따.

그래서 100개를 넘어갈 경우를 고려해 100개씩 쪼갠 하나의 묶음을 track_batch로 만든다.
그러니까 예를 들어 track_ids가 120개일 경우 100개단위로 쪼개다보니 len(track_batch)가 2개가 되는 것이다.
3) top_track 데이터와 마찬가지로 dataframe형태로 변형후, parquet형태로 떨굼 -> s3에 저장

s3에 저장한 결과
버킷에 audio_features와 top_Track을 접두사로 나뉘어졌고

audio데이터의 경우 날짜로 자동파티셔닝 되어 있다.
그래서 배치처리를 수행하여 생성된 parquet 형식을 날짜별로 저장하게 된다.


raw데이터를 실제로 보고 엄청나게 커서 까마득했는데 이렇게 압축되서 저장된걸 보니 좀 신기하다
다음엔 s3에 있는 데이터를 가지고 athena에서 쿼리를 수행할 것이다.
'사이드 프로젝트 > 음악추천 챗봇 서비스' 카테고리의 다른 글
| 음악추천챗봇8. 아티스트 유사도 테스트 수행 및 예외처리 (3) | 2021.07.02 |
|---|---|
| 음악추천챗봇7. crontab 스케쥴링 및 최종 메세지 확인 (0) | 2021.06.29 |
| 음악추천챗봇6. Athena 쿼리수행 및 음악 유사도 저장 | 데이터마트 (0) | 2021.06.26 |
| 음악추천챗봇 4.2 DynamoDB 데이터저장 및 1차 테스트 완료 (0) | 2021.06.19 |
| 음악추천챗봇4.1 RDS 데이터저장 및 lambda배포 (0) | 2021.06.08 |
| 음악추천챗봇1. Serverless아키텍쳐 구성하기 (0) | 2021.06.07 |



