spotify API로 얻는 결과들을 AWS 데이터베이스에 저장하는 단계이다.
이번엔 top track 정보를 dynamodb에 저장해둘 것이다.
아 그리고 잊을뻔했는데 이번 프로젝트의 목표는 데이터파이프라인 구축이다.
그리고 스포티파이 API로 필요한 데이터들을 수집하고,
MYSQL, DynamoDB, S3까지 다양한 데이터저장소를 사용해서 저장하고, 사용해보는 것이다.

DynamoDB에 데이터 insert
- 테이블명 : artist_toptracks
- 파티션키 : track_id
스포티파이API를 통해 읽어온 데이터를 그냥 그대로 통째로 넣어도 되긴 하지만,
나는 뭔가 필요한 데이터들만 뽑아서 쓰고 싶었다.
그러다보니 item이 될 데이터 json형식을 만들고, 그대로 put_item했다.
데이터 insert하기 코드보기 >>
for track in artist_tr['tracks']:
data={
'artist_id':artist_id,
'artist_name':artist_name,
'track_id': track['id'],
'track_name': track['name'],
'track_url': track['external_urls']['spotify'],
'album':
{'album_id': track['album']['id'],
'album_name': track['album']['name'],
'album_type': track['album']['album_type'],
'album_image': track['album']['images'][0]['url'],
'release_date': track['album']['release_date'],
'total_tracks': track['album']['total_tracks']
}
}
#data.update(track)
table.put_item(Item=data)
print("insert dynamodb 성공")
DynamoDB에서 데이터 select
이미 한번 DB에 저장한 아티스트일경우, SELECT해서 노래정보를 SELECT해야한다.
특히 그 노래정보는 최근발매된 순으로 3개만 보여줄 예정이다.
select하는 과정에서 조금해맸다.
원래는 그냥 artist_id에 해당하는 것만 get로 가져오려고 했는데, 생각해보니 디비의 파티션키는 track_id였다.
항상 key를 가지고 가져와야하기 떄문에 get을 사용하지 못했다.
대신 query와 scan을 쓸 수 있었다. key가 아니라 속성을 가지고 필터링할 수 있기 때문이다.
2021.06.15 - [DynamoDB] 파티션키/정렬키, 쿼리/스캔/get_item
데이터 select하기 코드보기 >>
def get_toptracks_db(id):
#dynanoDB 파티션키 : track_id
#track_result=table.query(KeyConditionExpression=Key('artist_id').eq(id))
select_result = table.scan(FilterExpression = Attr('artist_id').eq(id))
#print(track_result)
#최근 발매된 앨범순으로 정렬
select_result['Items'].sort(key=lambda x: x['album']['release_date'], reverse=True)
items = []
#최근 발매된 3개만
for track in select_result['Items'][:3]:
# ListCard 형태에 맞게 리턴
temp_dic = {
"title": track['track_name'], #타이틀곡명
"description": track['album']['release_date'], #발매일
"imageUrl": track['album']['album_image'], #앨범커버이미지
"link": {
"web": track['track_url'] #스포티파이링크
}
}
items.append(temp_dic)
return items
이렇게 items로 리턴한 이유는 다름아닌 메세지 형식때 문이다.
저 item들은 각각 노래에 대한 내용들이고, 이걸 최종메세지 형식에 item으로 넣을 것이다
최종적으로 리스트카드형은 이런json타입으로 카카오톡 챗봇에 보내져서 메세지를 보낸다
챗봇 메세지 형식 코드보기 >>
#3.list 카드형
{
"listCard": {
"header": {
"title": name+"의 노래를 찾았습니다"
},
# ListCard 형태에 맞게 리턴
"items": track_result,
"buttons": [
{
"label": "Youtube에서 검색하기",
"action": "webLink",
"webLinkUrl": youtube_url
}
]
}
},
예를 들면 이런식이다.

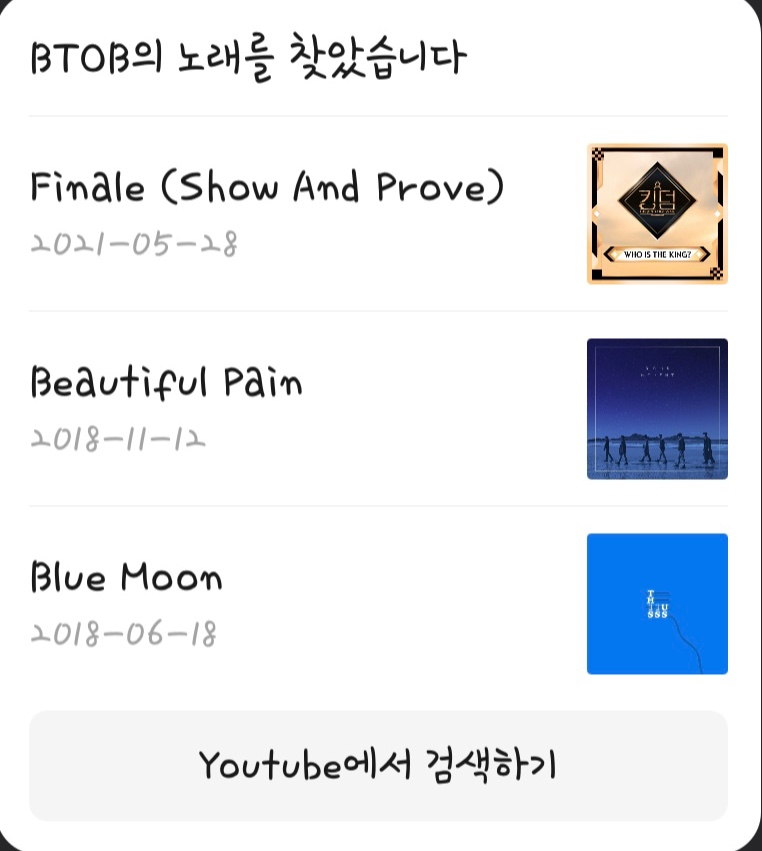
이제 최종적으로 완성되었다.
그래서 람다에서 넣어서 테스트해보았다.
오잉? 완성된 코드를 람다에서 zip으로 업로드가 안된다.

원인은 지금 내가 사용하고 있는 test라는 유저에게 UpdatelambdafunctionCode를 할 권한이 없는 것이다.
그래서 일단 root계정으로 로그인해서 수정했다...
테스트완료
처음에 디비에 없는 아티스트를 검색했을때.
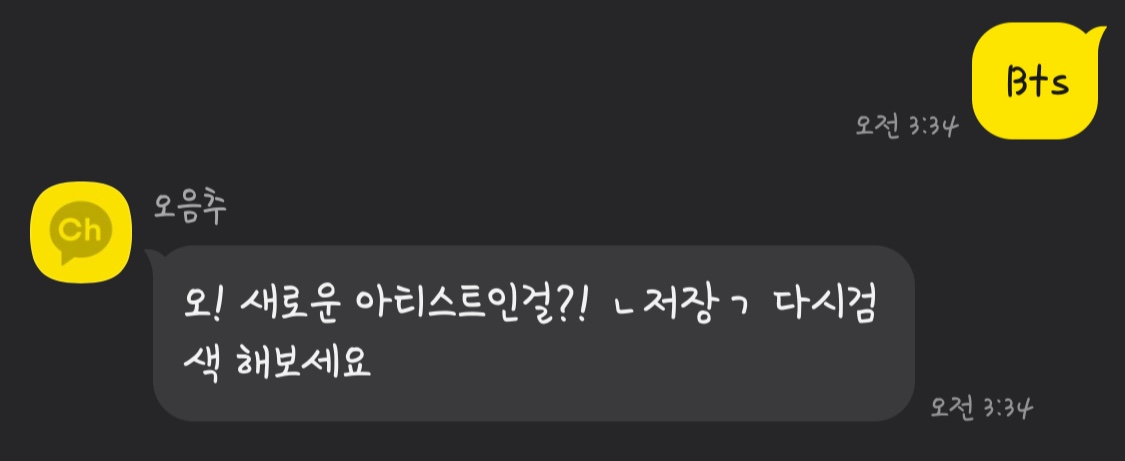
이후에 rds와 dynamodb에 아티스트정보와 음악정보가 저장된다.

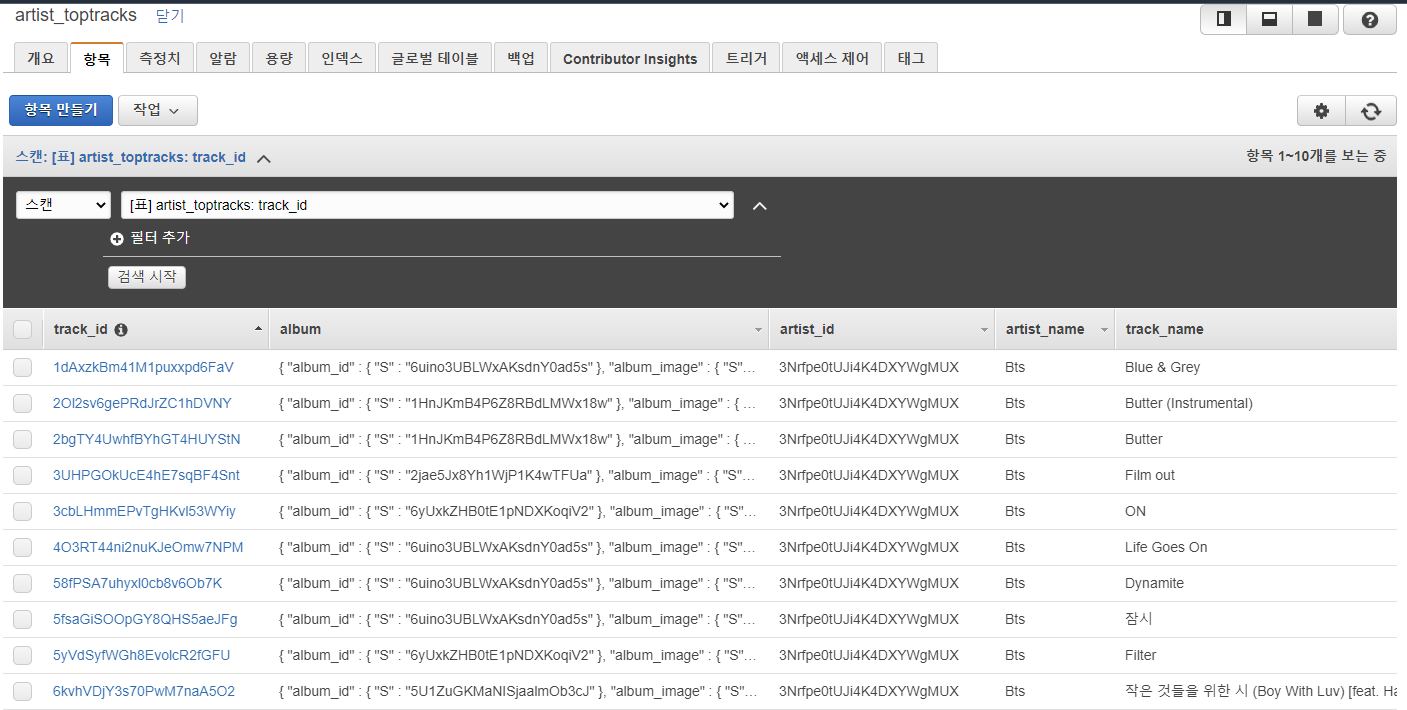
이제 디비에 저장되었으니, 다시한번 검색을 해서 결과를 확인한다.
아티스트정보내용과, 음악정보내용에 대한 메세지를 볼 수 있다.

앗, 테스트중 로직에서 수정할 부분을 찾았따...
mysql에서 select할때 조건을 내가 입력한 아티스트명에 따라서 검색을 하다보니 문제가 생긴것.
예를 들어, IU라고 검색을 했다면 DB에 IU가 그대로 들어간다.
그래서 아티스트가 있는지 검색을 확인을 할때 '아이유'도 아니고 'IU'라고 들어가야 검색이 된다.
원인은 입력한 아티스트명과 스포티파이에서 가져오는 아티스트명이 다르기 떄문이다.
예를 들면, 입력한 아티스트명은 방탄, 방탄소년단, bts가 될 수 있는
반면 스포티파이에서 검색하는 아티스트명은 항상 BTS이다.
이걸 해결하기 위해선 어떻게 해야하지?
항상 사용자가 스포티파이에 저장된 아티스트명으로 검색할리가 없는데...........
아예 입력시 조건을 주거나,, 아니면 중간에 한번더 사용자한테 확인하는 작업을 추가하거나..?
'사이드 프로젝트 > 음악추천 챗봇 서비스' 카테고리의 다른 글
| 음악추천챗봇7. crontab 스케쥴링 및 최종 메세지 확인 (0) | 2021.06.29 |
|---|---|
| 음악추천챗봇6. Athena 쿼리수행 및 음악 유사도 저장 | 데이터마트 (0) | 2021.06.26 |
| 음악추천챗봇 5.S3에 parquet 형태로 데이터저장 | 데이터레이크 구성 (0) | 2021.06.23 |
| 음악추천챗봇4.1 RDS 데이터저장 및 lambda배포 (0) | 2021.06.08 |
| 음악추천챗봇1. Serverless아키텍쳐 구성하기 (0) | 2021.06.07 |
| 음악추천챗봇0. 왜 Serverless아키텍쳐인가? Lambda의 장단점-동시성 (0) | 2021.06.05 |



