athena를 사용해서 s3에 있는 데이터를 가져온다.
2021.06.25 - [Athena] parquet형식 S3 데이터 가져오기
그런데 이렇게 콘솔로 쿼리를 수행 할 수 있지만, 우리는 그 쿼리의 결과를 가지고 유사도를 계산해야한다.
그래서 boto3를 사용해서 쿼리를 돌리고 그 결과를 가지고 유사도를 계산해볼 것이다.
1. Athena 쿼리수행
boto3로 아테나를 수행하기 위해 몇가지 함수를 쓴다. >> boto3에서 확인하기
start_query_execution : 쿼리를 수행하는 함수
-> if r['ResponseMetadata']['HTTPStatusCode'] == 200: 수행성공
-> r['QueryExecutionId'] : 쿼리id -> 매개변수로 get_query_execution함수 실행
get_query_execution : 쿼리수행결과를 리턴하는 함수


1) top_track 테이블 생성 쿼리
이후 파티셔닝을 위해 msk repair table top_track 쿼리도 수행한다.
테이블을 만들때 주의할게 앞서 s3에 저장하는 parquet형태와 같은 컬럼명이여야한다.

2) audio 테이블 생성 쿼리
이후 파티셔닝을 위해 msk repair table audio 쿼리도 수행한다.

음..데이터가없는 것 같은데..?
실제로 쿼리를 수행하고 난 result 확인해보면 {'Data': [{'VarCharValue': 'Partitions not in metastore:\ttop_tracks:dt=2021-06-25'}]
이렇다. 실제로 s3안에서도 이렇게 된 파일을 확인할 수 있다.

이 상태는 파티셔닝이 제대로 이루어지지 않는 것이라 한다...
clicks/2017/08/26/10/ 이상태가 아니라 clicks/year=2017/month=08/day=26/hour=10/
이렇게 매핑이 되어 있어야한다는 답변이다...
음 아니다! 그냥 이 메세지는 자동으로 파티션이 잘 조정된 결과라고 한다..!!
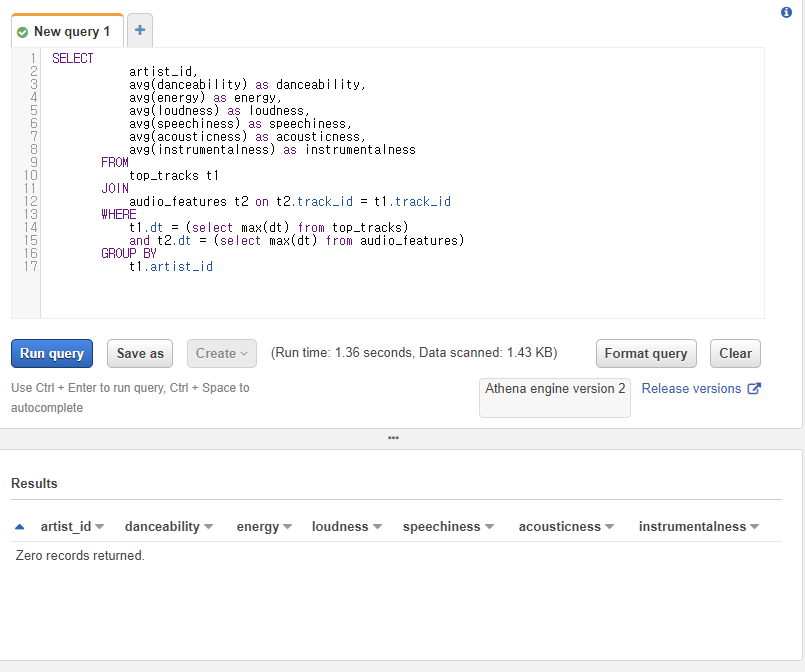
3) 아티스트별 audio 평균(Join) 수행 쿼리
아티스트별 평균 audio 수치를 가지고 유사도를 측정할것이다.
그래서 top_track 테이블과 audio 테이블을 track_id를 외래키로 하여 조인한다
쿼리를 수행한 결과는 아래와 같다. 이제 이 결과를 가지고 전처리 한 후 데이터를 가지고 유사도를 계산하면 된다.
join result 값 : key과 value가 따로따로 저장됨 >> 이를 데이터 프로세싱 해줘야한다.
{
"UpdateCount":0,
"ResultSet":{
"Rows":[
{
"Data":[
{"VarCharValue":"artist_id"},
{"VarCharValue":"danceability"},
{"VarCharValue":"energy"},
{"VarCharValue":"loudness"},
{"VarCharValue":"speechiness"},
{"VarCharValue":"acousticness"},
{ "VarCharValue":"instrumentalness"}
]
},
{
"Data":[
{"VarCharValue":"3Nrfpe0tUJi4K4DXYWgMUX"},
{ "VarCharValue":"0.6548"},
{ "VarCharValue":"0.7163"},
{"VarCharValue":"-5.243599999999999"},
{"VarCharValue":"0.07351999999999999"},
{"VarCharValue":"0.137286"},
{"VarCharValue":"0.0"}
]
}
],
{
"Data":[
{"VarCharValue":"3HqSLMAZ3g3d5poNaI7GOU"},
{ "VarCharValue":"0.6491"},
{ "VarCharValue":"0.6458999999999999"},
{"VarCharValue":"-4.1454"},
{"VarCharValue":"0.09942000000000001"},
{"VarCharValue":"0.347889"},
{"VarCharValue":"5.17E-7"}
]
},
{.. 생략..}
"ResultSetMetadata":{
"ColumnInfo":[
{
"CatalogName":"hive",
"SchemaName":"",
"TableName":"",
"Name":"artist_id",
"Label":"artist_id",
"Type":"varchar",
"Precision":2147483647,
"Scale":0,
"Nullable":"UNKNOWN",
"CaseSensitive":true
},
앗, 그리고 테이블의 컬럼명과 s3에서 가져온 데이터의 원본dict의 key가 일치하는지 확인해봐야한다.
그렇지 않으면 테이블 전체 result가 없거나, 또는 해당하는 컬럼의 값을 가져오지 못하는 경우도 있다.
내가 그랬다..................
트러블슈팅 히스토리
사실 중간에 컬럼만 나오고, 값이 없는 문제가 있었다. 이것때문에 잠깐 막혔었따..휴..
그래서 athena에서 직접 쿼리를 수행시켜 결과를 봤더니 역시나 없다. 띠로리..왜일까.....하

확인해보니 track_id로 조인한 쿼리결과가 없었따. 알고보니 audio 테이블에 track_id가 다 없었따!!! 헐
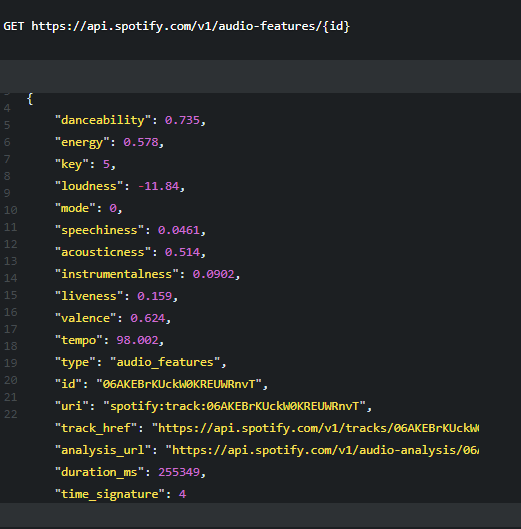
그래서 원인은 테이블의 컬럼명과 s3에서 가져온 데이터의 원본 dict의 key가 일치하지 않았기 떄문이다.
raw data를 바로 가져오는데 그 형식에서부터 track_id가 아니라 id로 되어 있었다.
그래서 해결하기 위해 테이블의 컬럼명을 이와 똑같이 다시 변경했다.

휴 이제 해결되었다..
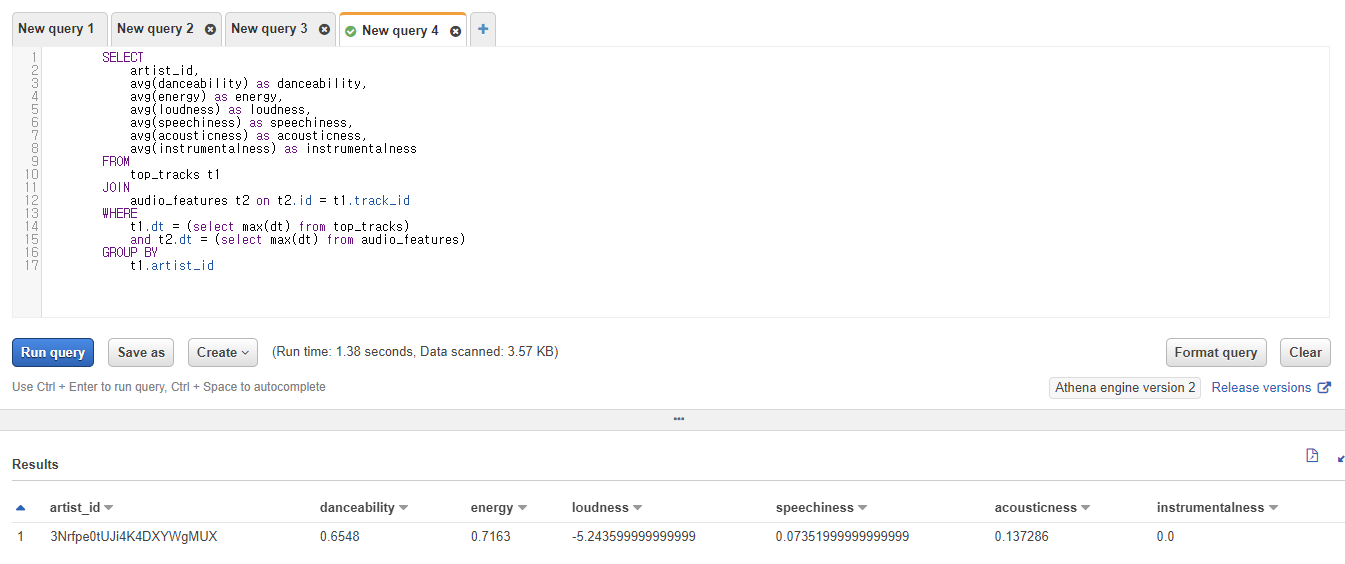
4) 정규화를 위한 수치별 최대,최소 수행쿼리
위에 수행결과는 아티스트별로 그룹화해서 오디오 정보를 계산해둔 것이라면
아래의 결과는 비교를 위해 최대,최소 저장해둔 테이블이다.

보면 컬럼을 기준으로 데이터들이 나열되어 있다.
첫번쨰 data는 컬럼명들만 varCharValue에 있고, 다음 data는 컬럼에 대한 값이 varCharValue에 있다.
그래서 이들을 처리해서 우리가 알고 있는 json타입으로 변환시켜줘야한다.
mix,min result 값 : key과 value가 따로따로 저장됨 >> 이를 데이터 프로세싱 해줘야한다.
{
"UpdateCount":0,
"ResultSet":{
"Rows":[
{
"Data":[
{ "VarCharValue":"danceability_min"},
{"VarCharValue":"danceability_max"},
{"VarCharValue":"energy_min"},
{"VarCharValue":"energy_max"},
{"VarCharValue":"loudness_min"},
{ "VarCharValue":"loudness_max"},
{"VarCharValue":"speechiness_min"},
{ "VarCharValue":"speechiness_max"},
{"VarCharValue":"acousticness_min"},
{"VarCharValue":"acousticness_max"},
{"VarCharValue":"instrumentalness_min"},
{ "VarCharValue":"instrumentalness_max"}
]
},
{
"Data":[
{ "VarCharValue":"0.499"},
{ "VarCharValue":"0.787"},
{"VarCharValue":"0.459"},
{"VarCharValue":"0.862"},
{"VarCharValue":"-6.755"},
{"VarCharValue":"-4.333"},
{"VarCharValue":"0.0338"},
{ "VarCharValue":"0.134"},
{ "VarCharValue":"0.0032"},
{"VarCharValue":"0.42"},
{"VarCharValue":"0"},
{"VarCharValue":"0"}
]
}
],
"ResultSetMetadata":{
"ColumnInfo":[
{
"CatalogName":"hive",
"SchemaName":"",
"TableName":"",
"Name":"danceability_min",
"Label":"danceability_min",
"Type":"double",
"Precision":17,
"Scale":0,
"Nullable":"UNKNOWN",
"CaseSensitive":false
},
2. 데이터 처리
컬럼명, 컬럼값들이 따로따로 저장되어 있는 컬럼기준 데이터를 처리하는 부분이다.
처음에 ['Row'][0]['Data']를 통해 컬럼명들만 우선 뽑아낸다.
그리고 다음 ['Row'][1:] 이후의 값들은 컬럼값이다. 이들을 다시 행기준으로 변환한다.
그렇게 나온 값들은 컬럼값들이다.
마지막으로 이렇게 따로따로 나온값들을 zip으로 묶어 dict형태로 변환해서 최종 결과를 []에 넣는다.
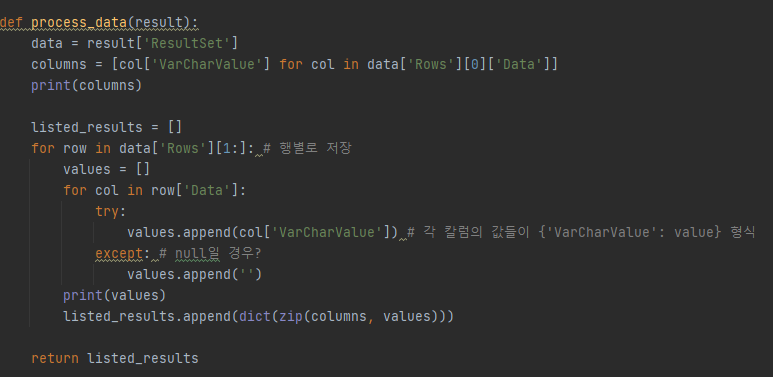
이렇게 까알끔하게 데이터를 정리한다!~!
1) 아티스트별 평균 음악수치데이터 데이터처리 결과
아티스트별로 인기 트랙의
danceability 평균, acousticness 평균, instrumentalness 평균 등 audio_features에 있는 음악수치별 평균값이다.
columns :['artist_id', 'danceability', 'energy', 'loudness', 'speechiness', 'acousticness', 'instrumentalness']
values :
['3Nrfpe0tUJi4K4DXYWgMUX', '0.6548', '0.7163', '-5.243599999999999', '0.07351999999999999', '0.137286', '0.0']
artists :
[
{
"artist_id":"3Nrfpe0tUJi4K4DXYWgMUX",
"danceability":"0.6548",
"energy":"0.7163",
"loudness":"-5.243599999999999",
"speechiness":"0.07351999999999999",
"acousticness":"0.137286",
"instrumentalness":"0.0"
}
]
2) 정규화를 위한 음악수치데이터의 최소,최대 데이터처리 결과
음악수치데이터들에 대한 정보이다.
column :
['danceability_min', 'danceability_max', 'energy_min', 'energy_max', 'loudness_min', 'loudness_max', 'speechiness_min', 'speechiness_max', 'acousticness_min', 'acousticness_max', 'instrumentalness_min', 'instrumentalness_max']
values :
['0.499', '0.787', '0.459', '0.862', '-6.755', '-4.333', '0.0338', '0.134', '0.0032', '0.42', '0', '0']
avgs :
{
"danceability_min":"0.499",
"danceability_max":"0.787",
"energy_min":"0.459",
"energy_max":"0.862",
"loudness_min":"-6.755",
"loudness_max":"-4.333",
"speechiness_min":"0.0338",
"speechiness_max":"0.134",
"acousticness_min":"0.0032",
"acousticness_max":"0.42",
"instrumentalness_min":"0",
"instrumentalness_max":"0"
}
3. 유사도계산
이제 쿼리를 통해 뽑아낸 aritst 와 avgs 데이터들을 가지고 유사도를 계산한다.
여기에서 유사도를 측정하는 알고리즘은 Euclidean Distance이다.
비교해서 거리를 계산하는 방법이라고 한다. 각 요소에 대하여 차이의 제곱들을 더해준 후 제곱근을 씌운값이 거리다.
찾아보니 '코사인 유사도'라고도 있지만 나는 DS전공이 아니니까...
그래서 솔직히 추천알고리즘에 대해서는 잘 모르겠어서 이분을 거의 따라했다.
얼마나 가까운지 거리를 측정하기 위해선 나 자신과 비교대상간의 거리를 구하는 것이다.

아무튼 이렇게 내가 검색한 아티스트(min_artist), 비교대상 아티스트(other_artist), 유사도를 위한 거리(distance)를
아래와 같은 related_artists이라는 테이블에 저장하려고 한다.
그전에 테이블을 생성해야한다. DDL은 이렇다.
create table related_artists(
mine_artist VARCHAR(255),
other_artist VARCHAR(255),
distance FLOAT,
date DATETIME DEFAULT CURRENT_TIMESTAMP,
primary key (mine_artist,other_artist)
);
그리고 잘 정리된 데이터들을 테이블에 insert해주면 된다.
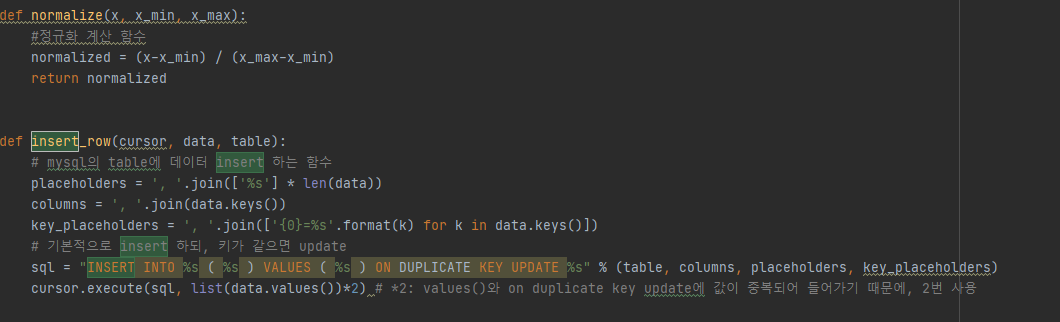
related_artists의 PK는 지금 검색한 아티스트(min_artist), 비교대상 아티스트(other_artist) 둘다이다.
그리고 현재 업데이트된 날짜를 디폴트로 적용하기 위해 date DATETIME DEFAULT CURRENT_TIMESTAMP 적용.

실제로 계산한 결과는 이렇다. 아직 아티스트가 두개밖에 없기 때문에 이렇지만 조금더 테스트해봐야겠따.

앞으로..
이로서 데이터를 저장하고, 데이터레이크를 만들어서, 유사도를 계산 할 수 있는 데이터분석환경까지 만들어보았다.
거의 90%는 완료된 것 같다. 해보려고 헀던 데이터파이프라인 구축과 백엔드단의 로직은 끝났으니까,
이제 코드도 조금 정리하면서, 프론트단이랑 연결시키고, 실제로 챗봇에서 테스트하는 작업이 남았다.
s3에 저장하거나, athena를 수행하는 파일을 따로 만들었는데 이들을 배치처리해야하는 작업도 남았다.
마지막까지 힘을 내봅시다!
'사이드 프로젝트 > 음악추천 챗봇 서비스' 카테고리의 다른 글
| 음악추천챗봇9. AWS EMR 클러스터구축(Hadoop+Spark+Zeppelin) (0) | 2021.08.07 |
|---|---|
| 음악추천챗봇8. 아티스트 유사도 테스트 수행 및 예외처리 (3) | 2021.07.02 |
| 음악추천챗봇7. crontab 스케쥴링 및 최종 메세지 확인 (0) | 2021.06.29 |
| 음악추천챗봇 5.S3에 parquet 형태로 데이터저장 | 데이터레이크 구성 (0) | 2021.06.23 |
| 음악추천챗봇 4.2 DynamoDB 데이터저장 및 1차 테스트 완료 (0) | 2021.06.19 |
| 음악추천챗봇4.1 RDS 데이터저장 및 lambda배포 (0) | 2021.06.08 |



