
현재상황
s3에 parquet형태의 데이터가 저장되어 있다.
이제 이 데이터를 아테나로 가져와서 sql쿼리를 날려볼 것이다.
2021.06.26 - 🌲Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기
1. 데이터베이스 생성
앗, 데이터베이스를 생성하기 전에 S3쿼리 쿼리 결과의 출력 위치를 지정해야한다.
Amazon S3에서 쿼리 결과 버킷의 위치를 지정하는 경우는 위에 "set up a query result location in Amazon S3" 간다.
그렇지 않으면 아래와 같은 오류가 생긴다.. >>구글링
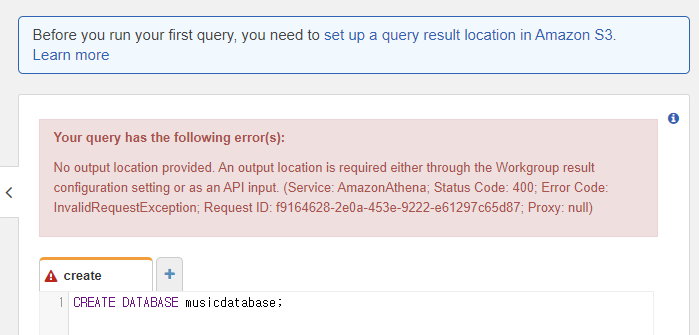
athena로 처리한 결과를 저장할 폴더를 s3에 따로 생성해두고, 그 위치를 지정한다.

2. 테이블생성
이미 s3에는 dt라는 날짜기준으로 파티셔닝을 해둔 상태.
그래서 아래와 같은 create문을 수행하면, s3의 top-tracks안에 저장된 parquet형식의 데이터를
snappy로 압축하여 top_tracks라는 이름의 테이블로 가져온다.
create external table if not exists top_tracks(
id string,
artist_id string,
name string,
album_name string,
popularity int,
image_url string
) partitioned by (dt string)
stored as parquet location 's3://musicdatalake/top-tracks'
tblproperties("parquet.compress" = "snappy")주의) 이떄 테이블의 컬럼명은 s3에 저장한 parquet형식으로 만든 데이터들의 컬럼과 같아야한다.
나는 parquet형식으로 만들땐 artist_id로 만들고, 테이블컬럼명을 id로 만드는 실수를 했다...
3. 데이터조회
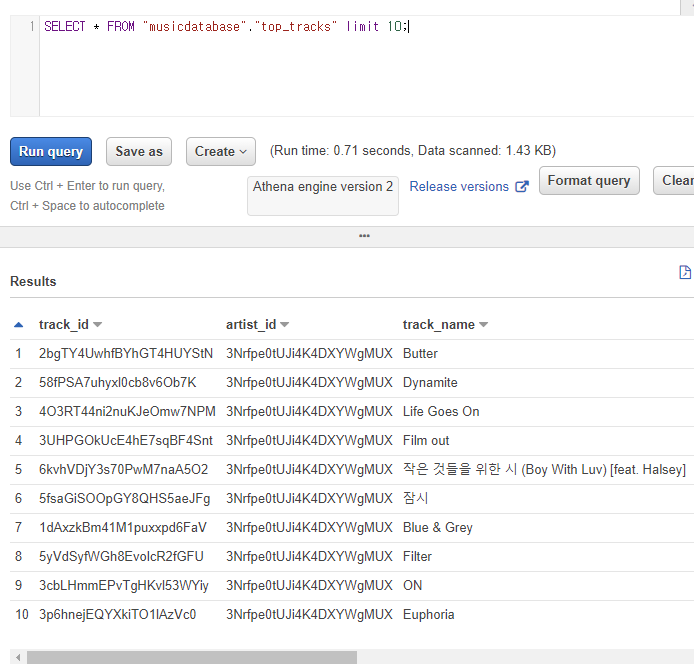
그리고 마지막에 아래의 쿼리를 실행해서 파티션이 적용된 형태의 데이터를 조회할 수 있다.
msck repair table top_tracks
그리고 preview table로 이러한 형태로 쿼리된 데이터를 확인할 수 있다.

4. TroubleShooting
1) Select하려는데 발생한 문제1
HIVE_BAD_DATA: Field instrumentalness's type INT64 in parquet file s3://musicdatalake/audio-features/dt=2021-06-25/audio_features.parquet is incompatible with type double defined in table schema
원인은 parquet에 있는 필드의 타입이 table의 스키마와 일치하지 않는다는 것
해결하기 위해 흠 instrunmetalness 필드가 있는 audio 테이블의 raw data을 확인했다.
audio raw data는 이렇다.
{
"audio_features":[
{
"danceability":0.759,
"energy":0.459,
"key":8,
"loudness":-5.187,
"mode":1,
"speechiness":0.0948,
"acousticness":0.00323,
"instrumentalness":0,
"liveness":0.0906,
"valence":0.695,
"tempo":109.997,
"type":"audio_features",
"id":"2bgTY4UwhfBYhGT4HUYStN",
"uri":"spotify:track:2bgTY4UwhfBYhGT4HUYStN",
"track_href":"https://api.spotify.com/v1/tracks/2bgTY4UwhfBYhGT4HUYStN",
"analysis_url":"https://api.spotify.com/v1/audio-analysis/2bgTY4UwhfBYhGT4HUYStN",
"duration_ms":164442,
"time_signature":4
},
instrunmetalness필드는 대부분 0이라 create할때 타입을 int형으로 변경했더니 해결되었따.
아놔. 다시 처음부터 테스트를 하려고 여러개의 데이터를 입력했더니 비슷하면서 다른 문제가 발생했다.
이번엔 double..?도대체 왜이러는건가ㅠㅠㅠ
HIVE_BAD_DATA: Field instrumentalness's type DOUBLE in parquet file s3://musicdatalake/audio-features/dt=2021-06-26/audio_features.parquet is incompatible with type integer defined in table schema
같은상황인 사례도 있지만 답변이 없다ㅠㅠ도대체 왜일까
parquet파일을 까보니, 문제가 있는 instrumentalness 컬럼에 이런 값이 있었다.
'instrumentalness': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 1.23e-05, 8: 0, 9: 0},'
이들의 타입을 확인해봤을때 이렇게 나왔다. 그래서 테이블로 정의할때 계속 문제가 생긴것!
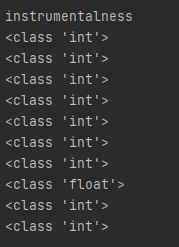
처음테스트할때는 모든 앨범의 instrumentalness이 다 0 이였다. 그래서 int로 지정해서 테이블을 정의할 수 있었는데 지금은 그럴수가 없다. 흠. 그렇다면 어떻게 해야하나.. int타입의 0을 float로 변경하는게 나을것 같다.
그래서 다시 raw data로 돌아가 처음에 받아온 데이터들을 float타입으로 다 변경했다.
'instrumentalness': {0: 0.0, 1: 0.0, 2: 0.0, 3: 0.0, 4: 0.0, 5: 0.0, 6: 0.0, 7: 1.23e-05, 8: 0.0, 9: 0.0},'

그래서 다시 테이블형식도 float타입으로 변경하니까 잘 됐다. 휴..
2) Select하려는데 발생한 문제2
HIVE_CANNOT_OPEN_SPLIT:
Error opening Hive split s3://musicdatalake/top-tracks/dt=2021-06-25/top_tracks.parquet (offset=0, length=8045): org.apache.parquet.io.GroupColumnIO cannot be cast to org.apache.parquet.io.PrimitiveColumnIO
다행히도 aws 공식 troubleshooting에 있었서 참고했다.
array같은 non-primitive type이 string같은 primitive type으로 선언되어 있을 수 있다고 스키마 필드를 확인해보라고..?
원인은 select하려고하는 parquet형식에 array같은 타입이 있다는 것이다.

해결하기 위해 top_track의 raw data를 확인해보았따.
top_track raw data는 이렇다. 이렇게 각각 값들이 []로 씌워져있었다.
[
{
"track_id":[ "2bgTY4UwhfBYhGT4HUYStN" ],
"artist_id":"3Nrfpe0tUJi4K4DXYWgMUX",
"track_name":[ "Butter" ],
"popularity":[ 95 ],
"external_url":[ "https://open.spotify.com/track/2bgTY4UwhfBYhGT4HUYStN" ],
"album_name":[ "Butter (Hotter, Sweeter, Cooler)" ],
"image_url":[ "https://i.scdn.co/image/ab67616d00001e026bb2b8231817c8d205d07fb2" ]
},
{
"track_id":[ "58fPSA7uhyxl0cb8v6Ob7K" ],
"artist_id":"3Nrfpe0tUJi4K4DXYWgMUX",
"track_name":[ "Dynamite" ],
"popularity":[ 52 ],
"external_url":[ "https://open.spotify.com/track/58fPSA7uhyxl0cb8v6Ob7K" ],
"album_name":[ "BE" ],
"image_url":[ "https://i.scdn.co/image/ab67616d00001e02e3169ec40cb4215a523865e2" ]
},
아예 처음에 s3에 저장하기 위해 dict형태를 만드는 로직부터 다시 찬찬히 살펴보았다.
그래서 []가 아니라 [0]으로 각 아이템을 넣는 방식으로 데이터형태를 변환했다.
그리고 기존과 같이 Dataframe으로 바꾸고, parquet형태로 바꿔서 다시 s3에 넣었더니 해결되었다.
어떻게 변경했는지, 그리고 코드의 수정된 사항들은 여기에서 확인할 수 있다.
'🌴 DevOps > Cloud' 카테고리의 다른 글
| 🚩[Redshift] Redshift 란? 다른DB들과 의 차이점은? (0) | 2021.08.21 |
|---|---|
| 🎯[Lambda] 람다의 장점과 단점 | 콜드스타트와 동시성제한 (0) | 2021.08.09 |
| [EMR] EMR이란? Elastic MapReduce 마스터노드 접속해보기 (2) | 2021.08.08 |
| ⚡[Athena] S3에 저장된 데이터활용하기 | 데이터파티셔닝과 압축 (0) | 2021.06.17 |
| [DynamoDB] DynamoDB란? 파티션키와 정렬키 (1) | 2021.06.15 |
| [AWS] 람다에서 Python 패키지 사용하기 | Layer(계층)란? (0) | 2021.06.10 |



