
Redshift 란?
AWS에서 완전관리형으로 제공해주는 클라우드 데이터웨어하우스.
클러스터(노드집합)를 생성하고, 클러스터가 사용할 준비가 되면(프로비저닝 완료) 데이터 적재 및 분석가능.PostgreSQL을 기반으로 해서 표준SQL을 이용한 데이터처리를 지원하고, BI도구로 분석할 수 있다.
>>데이터웨어하우스 관련글
데이터웨어하우스란? 수집한 여러가지 데이터를 추출 및 변환 과정(ETL)을 거쳐 적재하는 관계형 데이터베이스
2021.03.16 - 데이터웨어하우스(Data Warehouse)란?
2021.08.15 - [데엔스터디2] 데이터엔지니어링을 위한 데이터웨어하우스(RedShift)
Redshift 구성요소
클러스터 (Cluster) : 리더노드와 하나이상의 컴퓨팅 노드로 구성되어 있다.

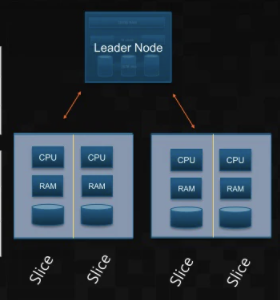
리더노드 (Leader Node)
SQL연결 엔드포인트, 외부 어플리케이션은 리더노드와 통신
노드간의 통신을 관리하는 노드로 메타데이터를 저장하고, 클러스터의 모든쿼리수행을 관리한다.
컴퓨팅 노드(Compute Node)
실제 작업을 수행하는 노드로 각 노드마다 여러개의 슬라이스를 보유하고 있다
병렬로 쿼리를 수행하고, S3기반으로 백업 및 복구를 수행할 수 있다.
슬라이스 (Slices)
각 노드는 여러개의 슬라이스로 구성되어 있다.
그 슬라이스는 별도의 메모리,cpu,디스크공간이 할당되어 있다.
슬라이스별로 독립적인 워크로드를 병렬적으로 실행한다.
Redshift 특징
여러가지 특징이 있지만, 그중에서 가장 중요한 메인특징(?) 2가지만 살펴보면 아래와 같다.
1. 대용량 '병렬'처리 : Massive Parallel Processing (MPP)
분산형(MPP) 시스템
클러스터를 리더노드 (Leader Node)와 컴퓨팅 노드(Compute Node) 로 구성되어 있고,
컴퓨팅 노드(Compute Node) 는 하나이상의 Slices로 구성되어 있다.
그리고 Slices에 데이터를 포함한다.
데이터를 병렬로 처리할 수 있도록 테이블의 행을 계산노드에 배포하고,
각 테이블마다 분산키를 선택하거나, All이나 Even방식 중 하나의 방법으로 슬라이스를 선택한다.
그리고 쿼리들은 모든 슬라이스들에 걸쳐 병렬수행을 한다.

- DISTKEY(Distribution key)
- 명시적으로 지정한 컬럼을 기준으로 각 레코드의 슬라이스 배치가 결정됨
- 컬럼 카디널리티에 따라 슬라이스간 상당한 편차가 발생 가능함
- 예) 여러 테이블에서 조인의 대상이 되는 경우 DISTKEY로 분산
- ALL
- 모든 레코드가 각 컴퓨팅 노드에 동일하게 복제함
- 예) 작은 테이블은 ALL(마스터 테이블)
- EVEN
- 각 레코드가 슬라이스에 라운드로빈 방식으로 분산, 균등하게 데이터 저장함.
- 예) 조인을 자주하지 않고 비정규화 된 테이블을 EVEN으로 분산
2. 컬럼기반 데이터스토리 : Columnar data storage
데이터베이스에 저장하는 테이블 정보를 행기반이 아닌 컬럼(열)기반으로 저장한다.
컬럼으로 압축함으로써 데이터를 읽는 크기를 줄여 디스크io를 줄이고, 쿼리성능을 향상시킬 수 있다.
압축기능의 자동적용을 위해 copy명령으로 redsfhift로 데이터를 로딩하면서 데이터분석할 수 있게 압축수행.
>>컬럼기반 포맷 관련 글
컬림기반으로 저장하면 뭐가 좋은가? 특정한 컬럼만 빨리 찾아낼 수 있어서 디스크io가 좋고 분석에 최적화
2021.06.26 - 🌲Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기
Redshift 기능
특징으로 분류하긴 좀 그렇지만, redshift를 사용함으로써 유용한기능? 클라우드 dw로서의 장점?이랄까.
1. COPY명령 : 데이터로딩
COPY명령을 통해 S3, DynamoDB,EMR에 있는 데이터들을 병렬적으로 로딩할 수 있다.
그러니까 보통 INSERT를 통해서 하나하나 데이터를 추가해야하는데 COPY명령으로 한번에 벌크업데이트식으로 로딩
2. 신속한 확장과 백업
클라우드기반이다보니 필요할때마다 설정을 변경해서 db를 확장하거나 축소 할 수 있다.
그리고 s3에 자동으로 백업 데이터가 저장이 된다. 필요에 따라 수동으로 스냅샷을 생성해서 백업을 할 수도 있다.
Redshift vs 기존DW : 클라우드 vs 온프레미스
1. 확장성
기존 dw는 온프레미스 시스템이라 사전에 할당된 리소스만 사용해야해서 확장하기 어려움,
반면 레드시프트는 클라우드기반이라 확장성이 뛰어남
2. 데이터집합적
기존 dw는 데어티가 여러장소에 분산되어 있어서 어떤데이터가 원본인지 알기 어려움
반면 레드시프트는 모든 데이터를 s3하나에 저장.
3.가격
기존dw는 개발비용이 비싼데, 레드시프트는 온디맨드요금으로 사용하는 만큼 비용부과
4.다양한 데이터
기존dw는 정형화된 데이터만 분석할 수 있음.
반면 레드시프트는 정형데이터 뿐만 아니라 반정형,비정헝 데이터도 가능,
raw data를 그대로 저장하고, 레드시프트가 분석할때 필요한 형태로 가공한다.
Redshift vs RDS : OLAP vs OLTP
레드시프트는 OLAP, 일반 RDS는 OLTP 워크로드에 사용한다.
RDS는 주로 서비스운영에 활용되는 db로 row단위의 update와 insert를 같이 단지 트랜잭션을 수행하는데 목표
반면 레드시프트는 DW이기 때문에 일반 RDS보단 대용량 데이터를 가지고 있고 복잡한 쿼리로 데이터를 분석하는 목표,
>>OLAP와 OLTP관련글
2020.01.17 - OLAP/OLTP/DW/ETL 용어정리
Redshift vs EMR vs Athena : 사용목적
EMR은 rawdata를 정제하고 분석처리할 수 있는 빅데이터 플랫폼 서비스.
하둡(MapReduce), Spark, Hive, Zeppelin 등 오픈소스 프레임워크를 가지고 클러스터를 쉽게 구축해준다.
반면 Redshift는 이미 정제하고 적재된 데이터를 이용하여 분석하는 데이터웨하우스.
Athena는 S3에 있는 데이터셋을 가지고 바로 쿼리르 수행하게 해주는 쿼리엔진 서비스.
S3데이터에 Glue스키마만 생성해주고, 간편하게 ad-hoc목적, EDA(Exploratory Data Analysis) 목적으로 사용
반면 Redshift는 복잡한 쿼리를 빨리 수행해야하거나 정기적인 배치처리가 필요한 경우 사용
>>EMR 또는 Athena관련글
2021.08.08 - [EMR] EMR이란? Elastic MapReduce 마스터노드 접속해보기
2021.06.17 - [Athena] S3에 저장된 데이터활용하기 | 데이터파티셔닝과 압축
참고
[aws] 아마존 레드쉬프트(Amazon Redshift), EMR과 의 차이
EMR EMR(Elastic MapReduce)는 하둡 프레임워크입니다. HDFS를 이용한 데이터 저장, 맵리듀스 작업을 통한 데이터 처리 작업을 할 수 있습니다. EMR에는 mapreduce, hive, spark를 이용한 데이터 처리를 지원합니
118k.tistory.com
https://jaemunbro.medium.com/aws-redshift-%EA%B8%B0%EC%B4%88%EC%A7%80%EC%8B%9D-987aedcb2830
[AWS] Redshift의 특징들. 다른 DB와 뭐가 다른가?
Redshift는 AWS의 MPP(Massive Parallel Processing) Database이다.
jaemunbro.medium.com
https://semode.tistory.com/324#recentEntries
AWS Redshift 기본 구조 및 설명
1. Amazon Redshift Cluster Architecture Leader node SQL endpoint Store metadata Coordinates parallel SQL processing Compute nodes Local, columnar storage Executes queries in parallel Load, backup,..
semode.tistory.com
[ AWS ] AWS RedShift 정리
AWS RedShift 란? 레드시프트란? AWS가 서비스하는 클라우드 데이터 웨어하우스 DB입니다. 2012년에 베타서비스를 시작하여 2015년에 정식 서비스를 시작하였지만 뛰어난 기능으로 많은 기업들이 사용
itjava.tistory.com
https://aws-hyoh.tistory.com/46
SAA #30, Redshift
필요 개념 Data Warehouse(DW) : 하나의 통합된 데이터 저장공간으로서, 다양한 운영 환경의 시스템들로부터 데이터를 추출, 변환, 통합해서 요약한 데이터베이스 - 데이터베이스가 관련 있는 업무
aws-hyoh.tistory.com
'🌴 DevOps > Cloud' 카테고리의 다른 글
| 📖[Kinesis] 직접 알아보는 Kinesis Data Stream (0) | 2023.07.01 |
|---|---|
| [Sagemaker] 직접 알아보는 AWS Sagemaker, 우리팀은 잘 사용하고 있는가? (0) | 2023.02.26 |
| Amazon Corretto로 java설치하기 (OpenJDK 다운로드) (0) | 2021.09.06 |
| 🎯[Lambda] 람다의 장점과 단점 | 콜드스타트와 동시성제한 (0) | 2021.08.09 |
| [EMR] EMR이란? Elastic MapReduce 마스터노드 접속해보기 (2) | 2021.08.08 |
| [Athena] parquet형식 S3 데이터 가져오기 (0) | 2021.06.25 |



