사실 요즘 세이즈메이커로 distributed training 를 해야하는 "챌린지" 가 주어졌다.
그래서 밤낮없이 troubleshooting을 하고 있는데.. (인생은 원래 혼자인법이지..🥲)
그전에 지금까지 우리팀에서 개발한 모델들과 알고리즘들을 어떻게 세이즈메이커로 학습해왔는지 한번 정리해보려고 한다.
Sagemaker란?

fully managed machine learning service.
개발한 머신러닝 모델을을 쉽고 빠르게 build하고, train해서, production까지 deploy해주는 머신러닝 서비스다.
그리고 여기 full managed 라는 "완전관리형"에는 "알아서"의 의미가 있는데 이게 장점이다 단점이다..ㅎㅎ
뿐만 아니라 같은 애플리케이션 환경에서 모델 build/train/deploy까지 해주는 Sagemaker Studio도 제공해주고,
Sagemaker Studio Lab은 싸이언티스트들이 AWS 컴퓨팅 리소스 위에서 개발할 수 있는 Jupyter Lab으로도 제공해주고 있다.
물론 우리팀에서는 이런 세이즈메이커의 다양한 기능은 제대로 쓰지 못하고, 대부분 training 하는용으로만 사용하고 있다.
참고로 요금은 사용하는 AWS 컴퓨팅 리소스 스펙별 사용시간으로 청구된다.
참고
- 기능: https://docs.aws.amazon.com/sagemaker/latest/dg/whatis-features-alpha.html
- 세이즈메이커 스튜디오 : https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html
- 세이즈메이커 스튜디오 랩 : https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lab.html
- 요금: https://aws.amazon.com/ko/sagemaker/pricing/
Sagemaker 작동방식
일반적인 머신러닝 모델을 생성하는 워크플로우는 아래와 같다.

1단계. 전처리되는 데이터 준비
In SageMaker, you preprocess example data in a Jupyter notebook on your notebook instance.
You use your notebook to fetch your dataset, explore it, and prepare it for model training.
개인적으로 세이즈메이커 스튜디오 랩으로 이 과정에서부터 서비스를 지원을 해주니까, 써먹어보면 좋을것 같다.
2단계. 모델 Train 및 Evaluate
우리팀에서는 대부분은 자체적으로 개발한 알고리즘을 사용해서 train을 한다.
그런데 세이즈메이커에서 built-in 알고리즘이나 pre-trained 모델을 제공해주고 있다.
you might be able to use one of the algorithms that SageMaker provides. For a list of algorithms provided by SageMaker and related considerations, see Use Amazon SageMaker Built-in Algorithms or Pre-trained Model
그리고 train할 수 있는 컴퓨팅 환경이 필요하다. 세이즈메이커로에선 단일 GPU부터 분산 GPU가 가능한 인스턴스까지 제공해준다.
you can use resources ranging from a single general-purpose instance to a distributed cluster of GPU instances.
3단계. 모델 Deploy
application이랑 통합하기 위해서 모델을 re-enginner하고, production으로 배포한다.
참고
- 세이즈메이커 동작방식: https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html
- 세이즈메이커에서 제공해주는 built-in 알고리즘, pre-trained 모델
https://docs.aws.amazon.com/sagemaker/latest/dg/algos.html
Model Train, Sagemaker Training Job
위의 워크플로우를 바탕으로 1단계는 ds쪽의 영역이다보니 패스하고, de인 나는 2단계 model train부터 살펴보면 아래와 같다.
그리고 우리팀에서는 sagemaker training만 사용하니까
sagemaker로 모델을 training하기 위해 create training job을 생성하는 구조를 이해해보았다.

위의 그림을 바탕으로 세이즈메이커에서 training 되는 전체적인 플로우를 이해하자면 아래와 같다.
1. sagemaker안에 model train을 하기 위한 컴퓨팅 리소스 환경이 생긴다. (EC2와 별개로 세이즈메이커 자체적인 인스턴스)
2. sagemaker안에 training code 그러니까 개발한 알고리즘의 모든 소소들은 ECR 이미지로부터 만들어져있다.
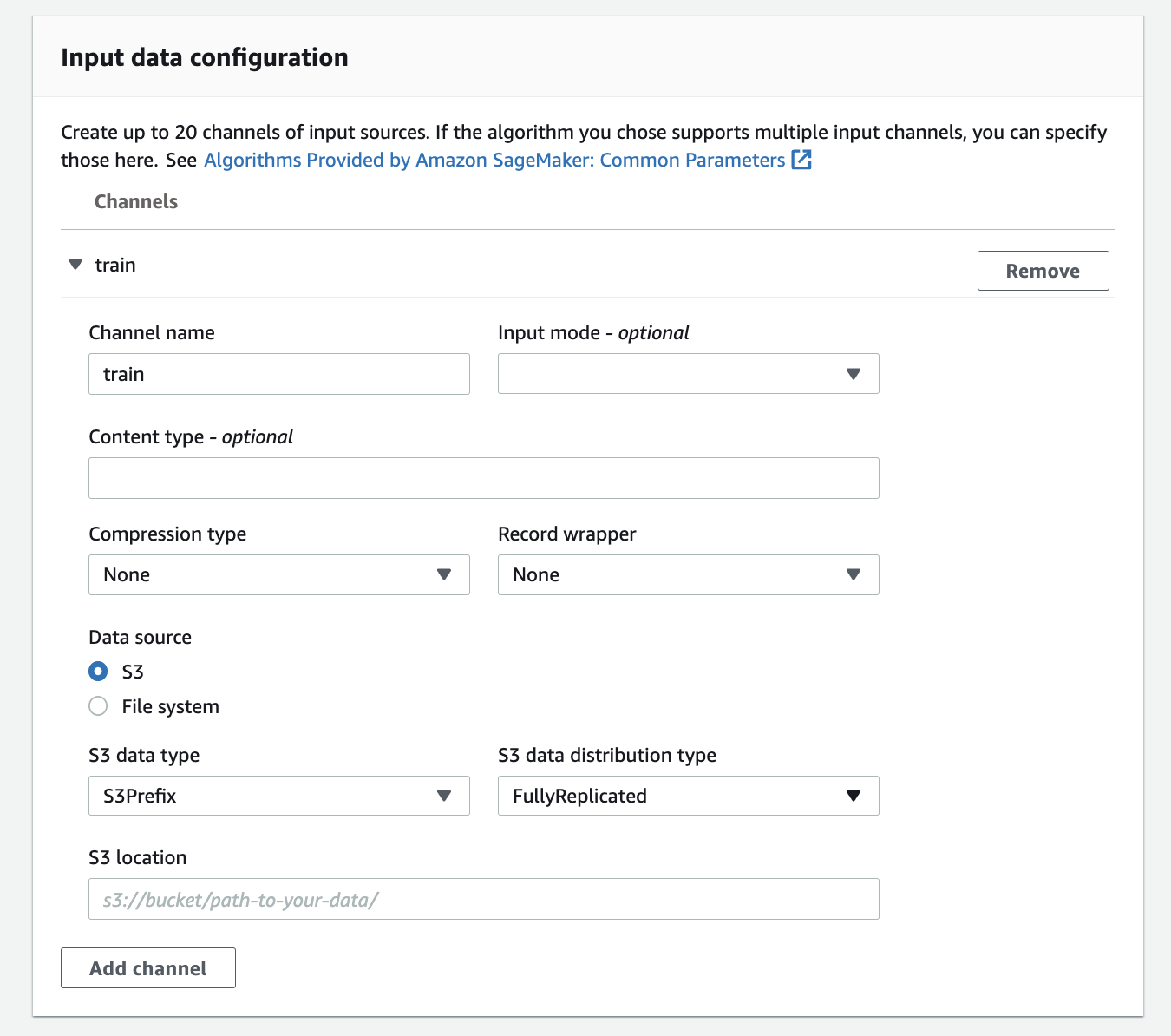
3. sagemaker안에서 train을 시작하기 위한 training data는 input s3 bucket에서 가지고 온다.
4.sagemaker안에서 train을 하고난 model artifacts는 output s3 bucket에 저장된다.
그래서 실제로 aws 콘솔을 살펴보면 아래와 같다.
job setting: 자체개발한 알고리즘을 쓰기 때문에 그 알고리즘 소스를 가지고 오기기 위한 ecr경로가 필요하다.
rescoure configuration : sagemaker안에 model train을 하기 위한 컴퓨팅 리소스 환경


hyperparameters : train을 할때 세팅할 하이퍼파라미터 옵션
우리팀에서는 이렇게 env,jobs, use_ssm_config 처럼 자체적인 key-value를 지정해서 넣고 있다.
그런데 이 hyperparameters안에서는 주로 batchsize나 epoch 등 train할때 조절할 값을 넣는것 같다.

input data configuartion : train data를 넣을 s3경로, s3뿐만 아니라 직접 파일로 넣을수도 있다.
output data configuartion : train이 완료되고 최종모델결과가 저장될 s3경로

- 모델 train : https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-training.html
Model Deploy, Airflow DAG에서 배치 job 생성
위의 워크플로우를 바탕으로 3단계 model deploy를 위해 우리 팀에서는 airflow dag로 배치 job을 생성한다.
이때 배치 job들은 sagemaker training job을 생성하는 일을 하는데,
위에 보이는 콘솔로 하나씩 생성하는게 아니라 create training job API를 사용해서 job을 만들도록 코드를 작성한다.
저런 세팅들을 전부 코드에서 작성을 해두고, 이걸 주기적으로 생성하기 위한 airflow DAG (사실MWAA) 를 작성하는 것이다.
그러면 배치주기에 따라서 해당 airflow job이 주기적으로 돌아가고,
각 airflow job들은 위의 코드에서 작성한 세팅대로 sagemaker job을 생성하는 일을 한다.
그래서 결국 주기적으로 모델이 deploy되서 배치결과를 만들면, 이를 바탕으로 API개발을 통해 어플리케이션에 적용을 한다.
DS와 DE, 우리 데이터팀의 머신러닝 모델 워크플로우
위의 워크플로우 기준으로 1단계는 DS가 작업을 하고, 2단계와 3단계는 DE가 진행한다.
그런데 DS가 1단계 작업을 할때 자체 로컬환경 주피터로 개발을 한다.
그러다보니 train하는 작업까지 DS의 로컬 환경에서 테스트를 해보고, 2단계를 위해 DE에게 코드를 넘겨준다.
그러면 DE가 이 코드를 엔지니어적인 측면으로 리팩토링을 한번 진행한 뒤, 모델러 코드를 ECR로 이미지를 배포한다.
그리고 로컬환경과 비슷한 또는 조금 더 컴퓨팅 스펙이 좋은 세이즈메이커 환경으로 sagemaker training job을 만들고,
이 job을 주기적으로 돌릴 airflow DAG를 작성하고, 모니터링하는 작업을 한다.
그러나, DS와 DE의 환경적 차이
지금까지 개발해온 알고리즘들은 CPU 컴퓨팅 환경을 요구하는터라
DS에서 train해본 로컬환경과 DE에서 sagemaker job으로 train 하는 환경적인 차이가 크지 않았다.
하지만 이번에 진행하는 프로젝트에서 개발하는 머신러닝 모델은 GPU 환경이다.
DS에서 train해본 로컬환경은 Single GPU 환경이였고,
DE에서 sagemaker job으로 train하는 환경은 Multi GPU 환경이였다.
여기까지는 단지 sagemaker를 띄우는 컴퓨팅 리소스를 변경하면 되기 때문에 큰 문제가 없다.
그러나 문제는 분산학습이다.
DS에서도 분산학습 환경으로 테스트를 해보지 않았고,
DE에서 sagemaker job으로는 분산학습을 진행해본 경험이 없다.
그러다보니 누가 코드를 만졌냐, 누구의 문제인가, 여기랑 일 못하겠다, 서로를 탓하면서 서로 좋지 않은 말이 오고가게 되었다.
사실 이 역할은 공식적으론 mlops의 역할이기에 따지고 보면 누구의 역할도 아니다.
하지만 개인적으로 어느정도 de가 조금 더 잘할 수 있는 영역이라고 생각이 들었다.
그런데 나는 이제 갓 1년차가 조금 넘은 된 주니어de..
주니어ds랑 같이 리드하는 사람도 없이 둘이서 머리를 싸매고 앉았지만 답답하고 계속된 자괴감에 빠져들 뿐...ㅠㅠ

DS와 DE 갈등원인과 해결방법
사실 개인적으로는 지금 이런 갈등의 '원인'은 2가지라고 생각이 들었다.
첫번째, 물리적인 환경적 차이
Single GPU 환경에서 분산했을때는 잘됐는데,
Multi GPU환경 (EC2)에서 분산했을때는 잘됐는데,
Multi GPU환경 (SageMaker)에서 분산했을때는 왜 안되는거야..? 이게 맞아..?
결국 각각의 환경이 모두 다른 상태이기 때문에 안되는건데,
그걸 니탓내탓, ds영역de영역으로 떠밀고 있으니 눈앞에 놓인 문제 상황이 보일리가 있나ㅎㅎ
두번째, 서로의 환경적 차이를 이해하지 못한 의사소통의 오류
내가 할때는 잘됐는데, 왜 너가 할때는 안되는거야? 너가 못해서 그런거네~~ 너가 안된거 내가 했어~~
이런 생각을 가지고 대화를 한다면 미안한 쪽이 생기면서 사람의 관계에서 한쪽으로 기울어질수밖에 없다.
그리고 특히나 이부분은 mlops의 영역이기 때문에 ds만 잘알고 있는 부분이 있고, de만 잘 알고 있는 부분이 있다.
그러니까 한쪽이 우위를 가져가는게 아니라 둘다 공평하게 서로 알고있는 부분을 같이 공유해나가면서 같이 진행해나가야했다.

결국 해결방법은..?
첫번째로, 물리적인 환경을 통일시켜야한다.
ds에서 주피터를 통해 잘 돌아가는 코드를 de한테 전달한다고 한들 환경적인 차이로 인한건 어쩔수가 없다..
그래서 세이즈메이커 스튜디오 랩(?)을 통해서 ds가 작성한 주피터의 환경이랑 동일한 환경에서 de도 작업을 해야한다.
사실 애초에 처음부터 ds가 개발을 할때 분산환경을 테스트할 수 있는 세팅부터 되어있었다면 이런 지식공유와 오해가 없었을것 같기도..
하지만 그 누구도 이런 환경적 차이가 다르다는걸 이해하지 못해서
이 차이가 다르다는걸 증명하기 위한 불필요한 테스트 리소스가 많이 들었다. 그래서 다르다고요!!
두번째로, ds와 de의 지식공유가 잘되어야 한다.
이제 이런 환경차이가 서로 이해가 됐다면, 이제 Multi GPU환경 (SageMaker)에서 분산이 되도록 되게 만들어야한다.
그러다보니 이제 de의 영역이 더 커지게 된다. 하지만 어느정도 ml관련 지식도 필요하기 때문에 de혼자서는 할수가 없다.
그래서 서로 어느정도 알고있는 부분을 같이 공유하고 같이 이해를 했어야 했다.
이말은 그냥 내가 이렇게 해봤어. 라고 여기에서 끝나는게 아니라
왜 이런 옵션을 조절해서 이렇게 수정을 해서 테스트를 했는지 그 자기 생각에 대한 근거를 명확하게 공유를 해야한다는 뜻이다.
이런게 없으니까 서로 신뢰가 부족한 상태에서는 단순히 너의 능력부족때문이다 라는 생각이 먼저 앞서게 된 것이다.
하지만 이런 지식공유가 많이 부족했다.
ds에서 이렇게 저렇게 해봤다곤 해서 그걸 믿고 진행했지만, 이제서야 근거를 찾아보면 막상 이렇게 할 필요가 없던 테스트도 있었다.
그래서 왜 해봤는지, 이렇게 저렇게 테스트를 해봤을때는 어떤 결과가 있었는지 이런 과정들을 좀 자세하게 공유하고 같이 논의했다면 좋았을것 같다. (하지만 물론 현실적으로 이렇게 진행하게 되면 일정을 맞출수가 없는 문제가 생길지도..ㅎㅎ)
아무튼간 앞으로도 이렇게 mlops의 영역이 많이 생길것이고,ds와 같이 협의하는 일이 많아질텐데
그럴때마다 이 글을 보면서 다시한번 같은 문제가 발생하지 않게 노력해야겠당..ㅎㅎ
그리고 개인적으로 조금더 적극적이고 주도적으로 일을 해야겠다고도 느꼈다.
결론 내가 더 잘해야지..! 다 죽었다. 세이즈메이커. 분산. 마스터한다.

'🌴 DevOps > Cloud' 카테고리의 다른 글
| LocalStack으로 AWS local Kinesis 환경 만들기 (0) | 2023.12.10 |
|---|---|
| 📖[Kinesis] 직접 알아보는 Kinesis Data Stream (0) | 2023.07.01 |
| Amazon Corretto로 java설치하기 (OpenJDK 다운로드) (0) | 2021.09.06 |
| 🚩[Redshift] Redshift 란? 다른DB들과 의 차이점은? (0) | 2021.08.21 |
| 🎯[Lambda] 람다의 장점과 단점 | 콜드스타트와 동시성제한 (0) | 2021.08.09 |
| [EMR] EMR이란? Elastic MapReduce 마스터노드 접속해보기 (2) | 2021.08.08 |



