ETL이란?
Extract, Transform, Load 의 앞글자를 딴 용어인데,
여러가지 데이터소스에서 추출(Extract)하고,
데이터를 원하는 형태로 변형(Transform)하고,
DW로 적재(Load)하는 과정.
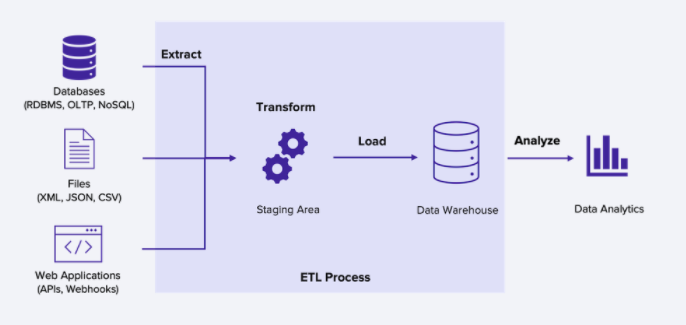
즉, 데이터소스에서 가져온 rawdata로 데이터웨어하우스에 바로 저장할 수 없으니 ETL과정이 필요하다.
핵심은 Tranform하는 단계.
비즈니스 또는 분석용도에 맞춰 데이터를 잘 정제해야한다.
당연히 데이터크기가 크면 클수록, Tranform하는 시간도 오래걸린다.
ETL파이프라인이 설계된 후에는 1일1회 등 방식으로 업데이트된 내용을 다시 가져와서 새로운 내용을 저장한다.
ELT란?
요즘에는 ETL에서 ELT방식으로 흐름이 바뀌고 있다. T와 L의 위치가 바뀐 ELT
기존의 ELT처럼 데이터를 적재하기전에 변형하는 것 대신에,
데이터를 추출(Extract)하고, 적재(Load)를 먼저 하고, 변형(Transform)하는 것이다.
모든 데이터 소스를 하나의 공간(DataLake)으로 적재를 한 뒤,
그 용도에 따라서 필요한 경우 툴이나 시스템이 직접 변형하게 하는 과정.
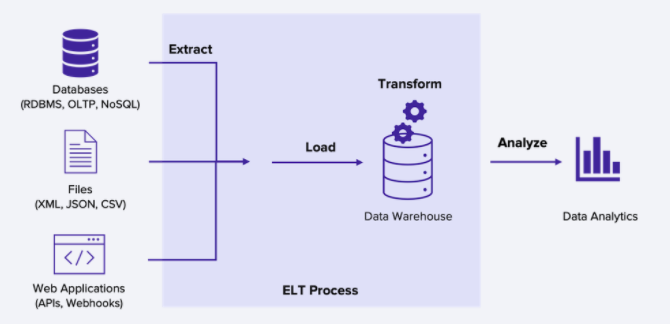
ETL에서 ELT로 왜 바뀌고 있나??
1. 대량의 데이터가 발생
ELT방식은 데이터가 커질수록 Transform하는데 시간이 걸린다.
그런데 이제 점점 데이터가 많아지다보니 ETL의 한계가 생긴 것.
tranform하는 시간 때문에 실시간 대규모 데이터를 감당할 하는데 어려워지고 있다.
그래서 "우선 데이터를 다 저장하고, 이 데이터를 어떻게 쓸지는 나중에 고민하자" 라는 컨셉이 생겨난게 DataLake.
마치 호수처럼 데이터웨어하우스 앞단에 모든 데이터를 다 저장해두고 (datalake),
그 중에 일부만 용도에 따라 데이터웨어하우스로 가져가서 쓴다는 컨셉이다.
결국 ELT는 대량의 데이터를 가진 환경에서 DataLake를 지원하기 위해 사용된다.
Data Lake vs DataWarehouse
데이터웨어하우스
어느 정도 가치가 있고,구조화된 데이터들이 모여있는 곳
다만, 공간이 제약이 있어서, 필요한 모든 데이터를 저장하지 않고 어느정도 최근데이터만 저장
BI툴이랑 연결해서 시각화해서 지표계산을 하는게 일반적
데이터레이크
데이터웨어하우스기반 파이프라인보다 훨씬 더 큰 개념
구조화된 데이터도 있지만, 비구조화된 데이터들이 존재
DW보다 용량도 크고 비용이 저렴해서 처음부터 지금까지 모든 데이터를 다 저장
데이터레이크는 어떻게 관리하는가?
대표적인 AWS의 S3같은 경우, 적어도 '키'를 기준으로 파티셔닝해서 데이터를 관리한다.
데이터가 중복될 수 도 있다.

데이터레이크 중에서 의미가 있고 최근 데이터만 transform해서 dw에 load된다.
보통 데이터레이크에 있는 데이터가 너무 많아서 일반적인 pandas가지고는 처리하기 어렵다
그래서 분산컴퓨팅환경(spark,redshift specturm,athena)를 통해서 data transform을 한다.
그리고 이렇게 처리된 데이터들은 dw나 데이터마트데 저장되는 것이다.
데이터레이크가 있으면 좋은점
데이터레이크에는 다양한 종류의 raw data가 시간의 제약에 없이 들어있다.
데이터모델링을 하는 사람 관점에서는 원하는 features들이 데이터웨어하우스에 없는 경우도 있다.
이럴때, 데이터웨하우스가 아니라 데이터레이크에서 찾아 사용할수도 있다.
2. 리소스들의 가격인하
기존엔 저장공간이 부족해서 분석을 위한 cpu성능도 부족해 미리 변환/정제를 해야했는데,
이젠 cpu,메모리,ssd,hdd 등 리소스가격이 싸졌을 뿐만 아니라 클라우드사용료도 인하가 되고 있다.
그래서 차라리 이정도 가격이면 전부 다 저장해버리는게 낫겠다는 컨셉에서 데이터를 먼저 저장하게 되었다.
물론 아직까지 ETL방식을 많이 사용하고 있다.
하지만 기존의 방식을 깨부수고 ELT방식으로 변화하는 기업은
BI,분석팀이 더 빠르고 유연하게 움직일 수 있는 환경을 제공해준다.
출처
https://artist-developer.tistory.com/m/37
ETL ELT 차이 (Feat. 데이터 엔지니어링의 변화)
안녕하세요. 개발자 김모씨입니다. 오늘의 이야기는 ETL, ELT에 관한 이야기입니다. ETL. 데이터와 밀접한 분야에서 일하고 계신 분들은 많이 들어보셨을 겁니다. 최근엔 'ETL 시대의 종말'이라고 할
artist-developer.tistory.com
https://blog.panoply.io/etl-vs-elt-the-difference-is-in-the-how
ETL vs ELT: The Difference is in the How
In this post, we take a look at the differences between ETL and ELT and explore which process will be the most suitable for your data integration.
blog.panoply.io
https://woongsin94.tistory.com/336
데이터 레이크(Data Lake)
개념 데이터 레이크는 대규모 Raw 데이터(가공되지 않은)를 한 곳에 모아 저장하는 리포지토리이다. "데이터 레이크"라는 용어는 Pentaho의 CTO(최고 기술 책임자)인 James Dixon이 처음으로 소개했다.
woongsin94.tistory.com
'🌿 Data Engineering > Data Processing' 카테고리의 다른 글
| 🧾대용량데이터 읽기 속도비교(read file, pandas, pyarrow) (1) | 2021.09.02 |
|---|---|
| 대용량데이터 빠르게 DB에 넣기(bulk insert) (0) | 2021.08.29 |
| 애자일(Agile) 방법론- 스크럼(Scrum) VS 칸반(Kanban) 데이터팀은? (1) | 2021.08.16 |
| [예정] 객체스토리지와 NoSQL스토리지의 차이점 /CAP정리 (0) | 2021.06.27 |
| 🌲Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기 (1) | 2021.06.26 |
| JSONPath 라이브러리와JSON파싱(load/dump/loads/dumps) (0) | 2021.06.26 |

