어떻게 알게 되었나?
보통 수집한 데이터들은 정형데이터, 비정형데이터에 따라 RDB나 NoSQL로 저장했다.
그런데 데이터레이크를 만들면서 객체스토리지인 s3에 데이터를 저장해야했다.
사실 처음엔 조금 당황했다. 엥? 어떻게 저장해야하는거지? 다른형태로 저장하는건가?
그 기술에는 parquet 데이터 형식이 있었다.
Parquet (파케이)
데이터를 저장하는 방식 중 하나로 하둡생태계에서 많이 사용되는 파일 포맷이다.
빅데이터처리는 많은 시간과 비용이 들어가서
빠르게 읽어야하고, 압축률이 좋아야하고, 특정언어에 종속되지 않아야한다.
이러한 특징을 가진 포맷으로 Parquet(파케이), ORC파일, avro(에이브로) 가 있다.
파케이의 역사

실제로 parquet(파케이)는
나무조각을 붙여넣은 마룻바닥이라는 뜻을 가지고 있다.
데이터를 나무조각처럼 차곡차곡 정리해서 저장한다는 의도일지도 모른다.
트위터에서 개발했고,
소스코드를 공개한 이후 아파치에서 관리하고 있다.
출처 : https://engineering.vcnc.co.kr/2018/05/parquet-and-spark/
컬럼기반 저장포맷
앞서 이곳 에서 컬럼기반 스토리지에 의한 고속화를 배웠다. (빅데이터를 지탱하는 기술 책 최고!)
컬럼기반 (열지향) 데이터베이스의는 컬럼단위로 데이터가 저장이 되서,
그래서 데이터를 미리 컬럼단위로 압축시키고, 필요한 칼럼만 빠르게 읽고, 집계하는데 빠르다.



마찬가지로 컬럼기반 저장포맷인 파케이의 목적도
필요한 데이터만 디스크로부터 읽어 I/O를 최소화하고, 데이터 크기를 줄이는 것이다.
Parquet의 장점
- 압축률이 좋다. 칼럼단위로 구성하면 데이터가 균일하므로 압축률이 높아 파일의 크기도 작다.
- 디스크IO가 적다. 컬럼단위로 데이터가 저장되어 필요한 컬럼만 읽다.
선택하지 않은 칼럼의 데이터는 디스크에서 읽지 않기 때문에 디스크IO가 적다. - 컬럼별로 적합한 인코딩을 사용할 수 있다. 각 컬럼의 데이터들은 동일한 타입의 데이터를 저장한하기 때문에 컬럼마다 데이터타입에 유리한 인코딩을 사용할 수 있다.
출처 https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kgw1988&logNo=221227551307
Parquet의 파일구조
사실 parquet파일로 만들고, 한번도 열어보지 못했다. 그래서 개인적으로 어떻게 데이터들이 저장되는지 궁금했다.
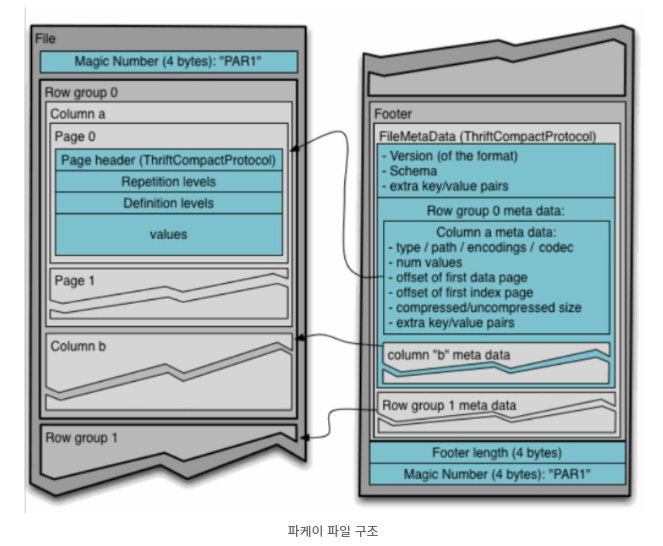
파케이 파일은 헤더, 하나의상의 블록, 꼬리말 순으로 구성된다.
헤더는 파케이 포맷의 파일임을 알려주는 4바이트 숫자. 매직숫자인 PART1만 포함하고 있다.
꼬리말에는 포맷버전, 스키마, 추가 KEY-VALUE 쌍, 파일의 모든블록에 대한 메타데이터를 저장하고 있다.
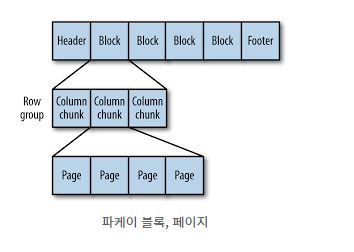
블록에는 행그룹을 저장한다.
행그룹은 행에 대한 컬럼데이터를 포함한 컬럼청크로 되어 있따.
각 컬럼청크는 페이지에 기록된다.
페이지에는 동일한 컬럼값만 포함하고 있다.
따라서 페이지에 있는 값들은 비슷한 경향이 있다.
이러한 구조때문에 압축할때 매우 유리한 것이다!
데이터의 최소단위인 페이지에는 동일컬럼의 데이터만 있다.
인코딩/압축할때 페이지단위로 수행한다.
출처 https://devidea.tistory.com/92
Parquet 파일 생성
나는 dict형태로 변환한 데이터를 dataframe형태로 만들고, parquet형태로 변환했다.
to_parquet(파일명, engine , compression) 함수를 사용했다.
#dict형태->dataframe형태 ->parquet형태
top_tracks = toptrack_s3(artist_result,headers)
track_ids = [track['track_id'] for track in top_tracks] # jsonpath 사용해 [0]형태로 이미 넣었다.
top_tracks = pd.DataFrame(top_tracks)
top_tracks.to_parquet('top-tracks.parquet', engine='pyarrow', compression='snappy') #top-tracks.parquet 파일 떨굼pyarrow는 뭐지?
대용량 파일을 읽을 수 있는 라이브러리
메모리 내 분석을 위한 개발 플랫폼인데, 빅데이터를 빠르게 처리할 수 있다.
pip instasll pyarrow 후 parquet파일을 생성하고 읽을 수 있다.
참고로, pandas처럼 csv를 읽을 떄도 사용할 수 있는데 pandas보다 훨씬 빠르다. from pyarrow import csv df = csv.read_csv("new_file.csv").to_pands() 이렇게 사용하기도 한다
snappy는 뭐지 ?
parquet형식에서 기본적으로 사용하는 압축라이브러리.
구글에서 자체 개발한 압축라이브러리로 최고의 압축률보다 '적당히 빠르고 적당히 압축/해제'가 목표
압축률이 좋지만 빌드관련 의존패키지를 설치해야하고, 때로 의존성 라이브러리 이슈가 종종 있어 사용하기 까다롭다.
그래서 snappy보다 압축속도는 느려도 압축률은 좋은 gipz을 사용하기도 한다.
출처 https://beomi.github.io/2020/01/29/Use-parquet-on-pandas/
Parquet 파일 읽기
처음에 parquet 파일을 접했을떄 조금당황스러웠다. 압축이 된 상태이기 때문에 압축을 풀어야 하기 때문이다.
gzip/snappy 등 어떤 압축방식이든 파일을 읽는 방식은 동일하다.
pandas를 활용해 read_parquet()를 사용하면 dataframe형태로 읽을 수 있다.

또는 parquet-tools를 사용할 수 있다.
pip3 install parquet-tools 후 parquet-tools show [파일명.parquet]
parquet-tools은 parquet 모듈에 포함되어 cli를 통해 파일의 스키마, 메타데이터, 데이터를 확인할 수 있다.
parquet-tools를 이용하는 방법은 공식문서에 잘 나와있다.
parquet-tools show test.parquet
parquet-tools show s3://bucket-name/prefix/* (오 s3로 가능하네!)
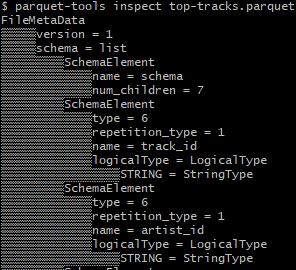
parquet-tools inspect /path/to/parquet
등등 명령어를 사용해서 parquet 파일을 확인할 수 있따.
대표적으로 show 명령어를 사용해 테이블형식으로 볼 수 있었따.
inspect명령어는 메타데이터를 확인하는 것 같다..! 메타데이터를 따로 확인해볼 필요가 있나보구나..!

'🌿 Data Engineering > Data Processing' 카테고리의 다른 글
| 애자일(Agile) 방법론- 스크럼(Scrum) VS 칸반(Kanban) 데이터팀은? (0) | 2021.08.16 |
|---|---|
| ETL ELT 차이 | 요즘엔 ETL에서 ELT로 흐름이 바뀌고 있다?@! (0) | 2021.08.16 |
| [예정] 객체스토리지와 NoSQL스토리지의 차이점 /CAP정리 (0) | 2021.06.27 |
| JSONPath 라이브러리와JSON파싱(load/dump/loads/dumps) (0) | 2021.06.26 |
| 데이터웨어하우스(Data Warehouse)란? (0) | 2021.03.16 |
| 데이터엔지니어, 돌고 돌아 다시 확신을 갖게 되다 (0) | 2021.03.10 |

