지금까지 생성한 이미지를 도커허브에 배포한다.
마지막에 생성한 zeppelin 이미지가 전체적으로 java,ubuntu,spark,hadoop,zeppelin이 포함된 이미지가 된다.
그래서 이걸 도커허브에 올려보겠다.
그럼 다른사람들이랑 공유할 수 도 있고 내가 외부에 잇을떄 이걸로 가져올수도 있는것(깃처럼)
docker 로그인
이미지배포
도커계정의 id,pw입력

가장 마지막에 생성한 zeppelin 이미지를 배포해볼 것이다

docker tag [push할 image ID or name] [docker hub ID]/[image name]:[version]
docker push [docker hub ID]/[레파지토리]:[tag]
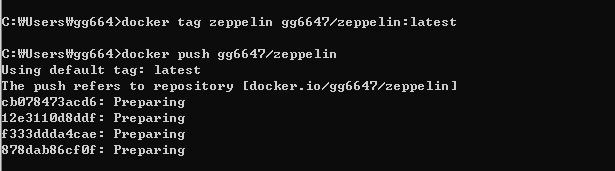
도커허브확인
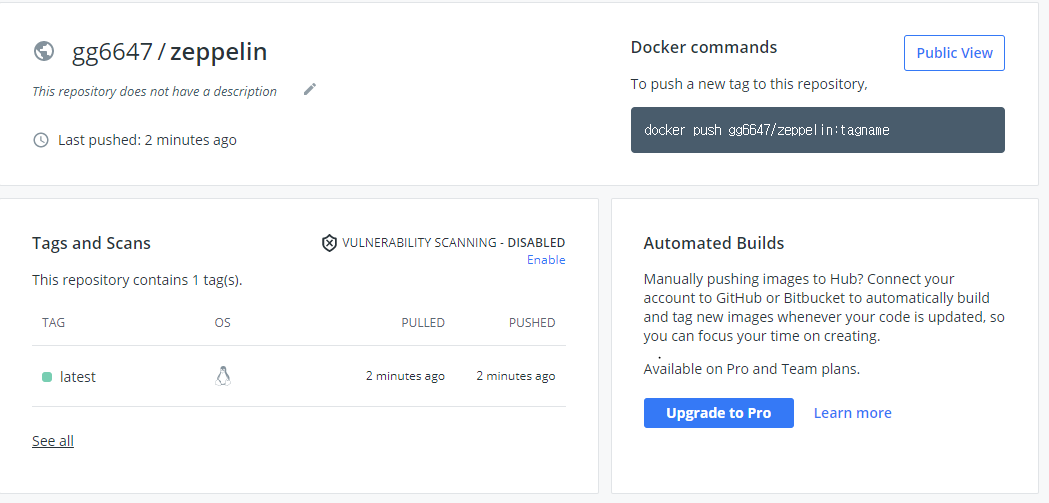
Troubleshooting
zeppelin에서 python이랑 연동이 되지 않는다.
org.apache.commons.exec.ExecuteException: Execution failed (Exit value: -559038737. Caused by java.io.IOException: Cannot run program "python" (in directory "."): error=2, No such file or directory)
또한 spark랑도 연동이 되지 않았다.
org.apache.zeppelin.interpreter.InterpreterException: java.io.IOException: Interpreter process is not running
원인 : zeppelin에서 spark와 python인터프리터를 찾지 못하는 것 같다.
스파크에서 running application이 없다.
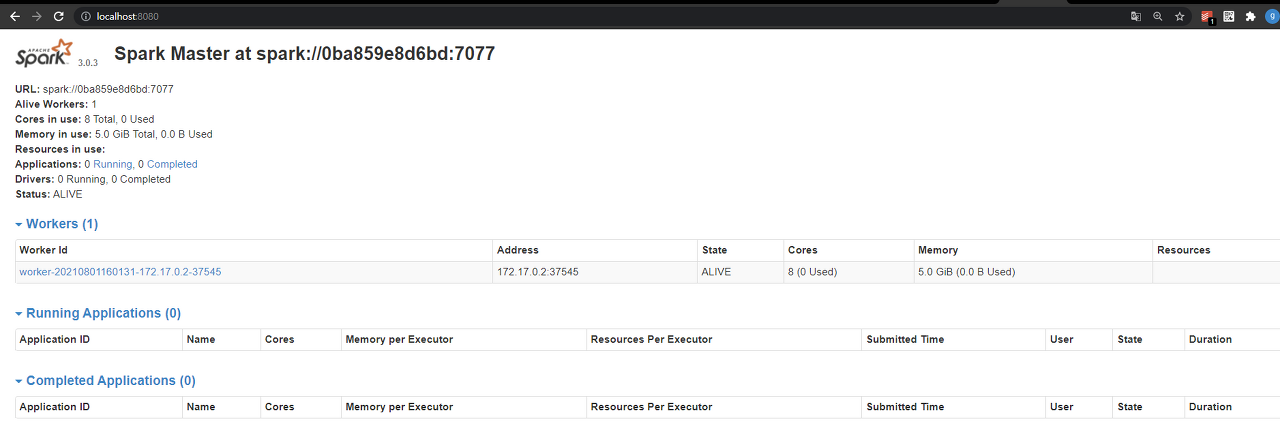
인터프리터 설정에서 경로를 spark 서버주소로 변경해줘야하는데,
컨테이너 안에서 실행되고 있어서 이 주소를 어떻게 설정해야하나 고민이 많았다.
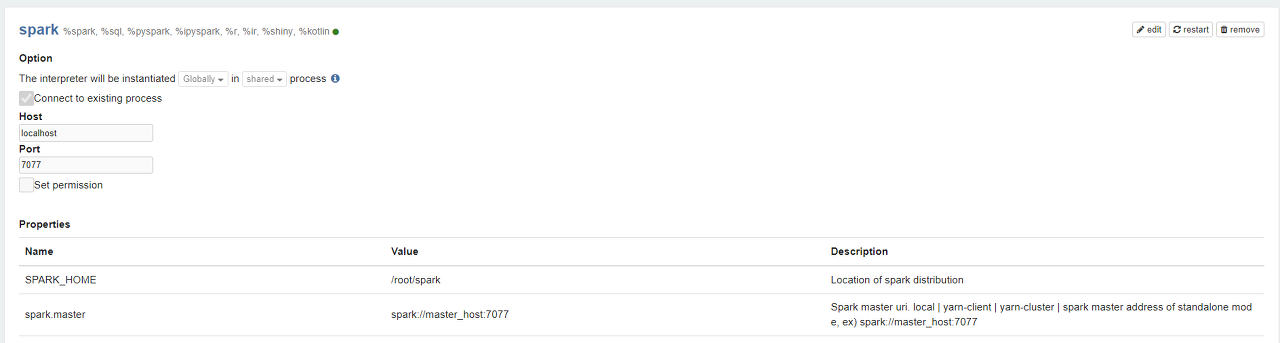
어차피 spark의 마스터host도 zeppelin이 실행되는 localhost가 아닐까
연결을 확인해봤는데, spark는 내부ip(172.17.0.2)를 가진다.흠

그리고 spark의 마스터노드 로그를 확인해보았다.
7077이 마스터spark서버의 포트번호가 맞고, 8080이 외부웹ui로 볼 수 있는 포트같은데

결론
사실 이전에 docker image로 hadop,spark,zeppelin으로 분석환경을 구축해보았지만
zeppeline에서 spark와 연결이 되지 않았다..
뭔가 제플린에서 spark인터프리터를 구성하는 주소가 잘못된거 같기도하고..
나중에 도커를 다시 공부해서 다시 연결해봐야겠다. 이렇게 말고 클러스터로해서 docker-compose써야할것 같기도..
아무튼...일단 spark를 사용해보는게 목적이였기 때문에
zeppelin 공식문서에 가서 docker로 제플린공식 image로 시작했다..
근데 넘 쉽게 잘댐..어이x
docker run -p 8080:8080 --rm --name zeppelin apache/zeppelin:0.9.0
localhost:8080접속
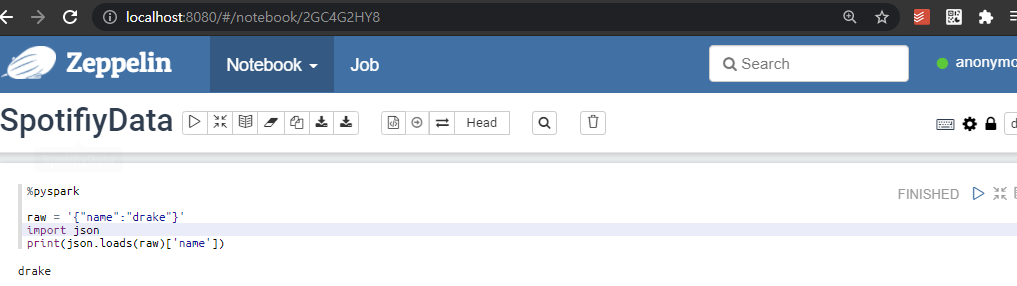
그래서 s3에 있는 데이터를 가지고 오려고 했는데 아직해결하지 못했다..
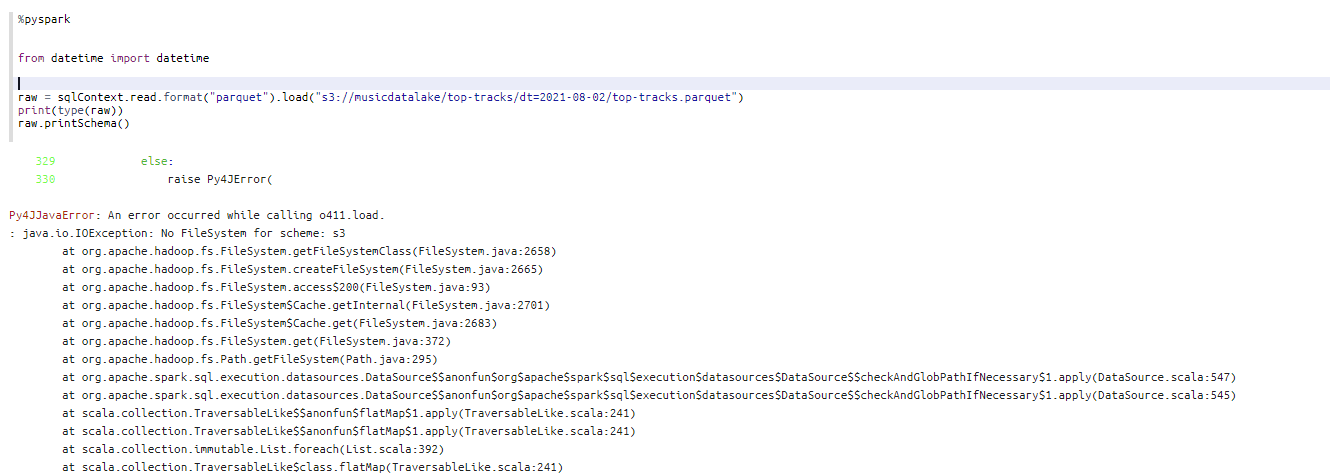
여기처럼 해보고싶었는데.....
https://stophyun.tistory.com/224
[Spotify Data Analysis/스포티파이 데이터 분석] Zeppelin을 활용한 스파크(Spark), AWS S3, SQL (7)
제플린(Zeppelin)을 활용해서 Spark의 대한 기능들을 살펴보도록 하겠습니다. 기본적인 적들은 아래와 같은 구문을 통해서 활용할 수 있습니다. 스파크는 rdd라는 개념을 사용합니다. AWS S3에 있는 par
stophyun.tistory.com
'🌴 DevOps > Docker & K8s' 카테고리의 다른 글
| [유데미 강의 정리 1] docker 개념 및 도커 네트워킹 통신 (0) | 2024.03.31 |
|---|---|
| [docker] Mac M1 이미지 빌드 오류 : qemu: uncaught target signal 6 (Aborted) - core dumped (1) | 2022.03.28 |
| 🐘 [Docker] 빅데이터환경구성 (최종) - Hadoop&Spark 설치 (0) | 2021.09.07 |
| [Docker]빅데이터 분석환경 구성4-Zeppelin0.9 설치 (0) | 2021.07.27 |
| [Docker] 빅데이터 분석환경구성3-Spark 3.0설치 (0) | 2021.07.27 |
| [Docker] 빅데이터 분석환경구성2-Hadoop 2.7.7 (0) | 2021.07.27 |



