3.Spark
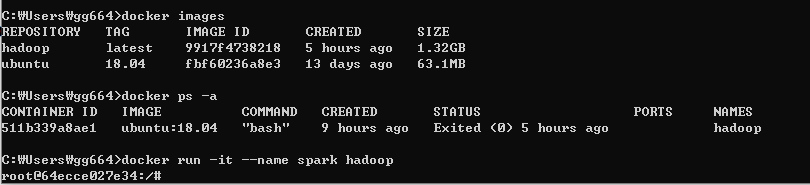
이어서 java,hadoop이 설치된 이미지를 사용해서 컨테이너를 생성한다.
1. 컨테이너 생성 (spark)
docker run -it --name 컨테이너이름 image이름
2. spark 설치 및 환경설정
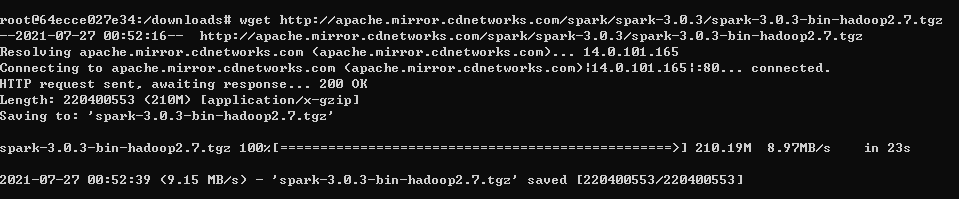
2-1. spark다운 및 압축해제
여기 에서 spark버전을 선택해서 다운받을 링크를 복사한다.
wget http://apache.mirror.cdnetworks.com/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz
tar xvfz spark-3.0.3.tgz

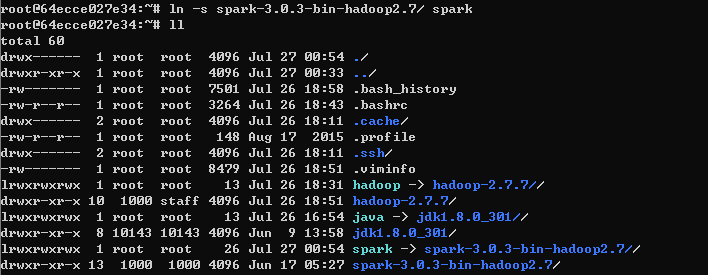
2-2. 파일이동 및 심볼링크(spark) 등록
압축을 푼 폴더를 홈디렉토리로 이동한다
mv spark-3.0.3-bin-hadoop2.7 /root
그리고 그 경로를 spark라고 심볼링크를 등록한다
ln -s spark-3.0.3/ spark

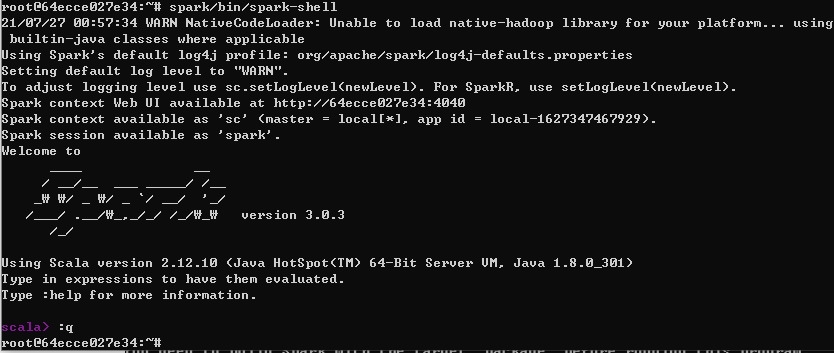
2-3.Spark 실행확인
spark/bin/spark-shell
정상적으로 실행이 되면 scala>로 접속이 된다.
:q 입력해서 스파크 쉘에서 나온다.
+추가.pyspark 실행확인
spark/bin/pyspark 는 아직 안된다. 그래서 python으로 spark를 쓰기 위해 pyspark를 연동해준다.

1) 패키지설치
apt-get update
apt-get install -y software-properties-common
add-apt-repository ppa:jonathonf/python-3.6
2) 파이썬 설치
apt-get install python 3.6
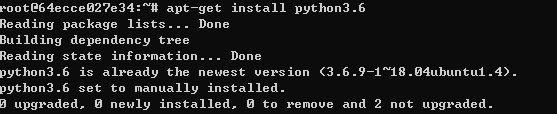

3) 파이썬 환경변수 설정
파이썬 환경변수를 등록한다
환경변수등록 파일 열기 vi ~/.bashrc
vi ~/.bashrc에서 아래와 같이 pyspark_python 패쓰를 추가한다.
환경변수등록 파일 저장 source ~/.bashrc
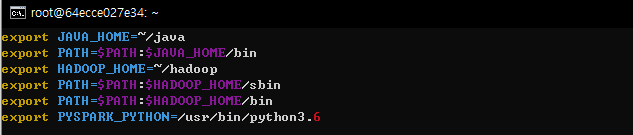
4) pyspark 테스트

2-4.환경변수 설정
spark안에 있는 spark-env.sh을 변경한다.
cp spark/conf/spark-env.sh.template spark/conf/spark-env.sh
vi spark/conf/spark-env.sh

3.Spark실행 및 정상동작 확인
3-1. ssh서비스 실행 : service ssh start
3-2. Spark 실행
mster 실행 : spark/sbin/start-master.sh
slave 실행 : spark/sbin/slave-master.sh


3-3. 정상동작 확인
자바프로세스 명령 jps
아래와 같다면 spark 정상동작 확인
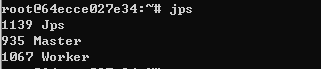
3-4.컨테이너 이미지화
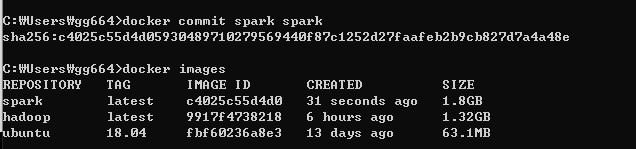
exit하고 컨테이너에서 나온다음, 지금까지 작업한 컨테이너를 spark 이미지로 생성
docker commit CONTAINER IMAGE_NAME
docker commit spark spark
이미지확인 docker images
맨처음 pull로 가져온 ubuntu가 있고,
java를 설치랑 hadoop을 설치한 이미지가 있고,
spark를 설치한 이미지까지 확인되었다.
'🌴 DevOps > Docker & K8s' 카테고리의 다른 글
| 🐘 [Docker] 빅데이터환경구성 (최종) - Hadoop&Spark 설치 (0) | 2021.09.07 |
|---|---|
| [Docker] (보류) 도커허브에 이미지 배포 +TroubleShooting (0) | 2021.07.27 |
| [Docker]빅데이터 분석환경 구성4-Zeppelin0.9 설치 (0) | 2021.07.27 |
| [Docker] 빅데이터 분석환경구성2-Hadoop 2.7.7 (0) | 2021.07.27 |
| [Docker] 빅데이터 분석환경 구성1-Ubuntu&Java설치 (1) | 2021.07.27 |
| [Docker] windows 10에 docker 설치하기 (1) | 2021.03.30 |



