
콘텐츠 기반 필터링(content based filtering)
사용자가 특정 아이템을 선호하는 경우, 그 아이템과 '비슷한' 콘텐츠를 가진 다른 아이템을 추천해주는 방식
굉장히 단순한 아이디어. 요즘엔 자주 사용하지 않는다.
예를 들어 사용자가 a가 itemA 영화에 높은평점을 주었을떄,
그 영화가 스릴러 영화고, 봉준호 감독이라면
이와 깉이 봉준호 감독의 다른 스릴러 영화를 추천해주는 것이다.
데이터셋 : https://www.kaggle.com/tmdb/tmdb-movie-metadata?select=tmdb_5000_movies.csv
목적 : 콘텐츠 기반 필터링으로 사용자에게 비슷한 영화를 추천해준다
1. 데이터준비

2. 데이터전처리
사용할 컬럼 정리
vote_averages(평점평균), vote_count(평점 카운트), popularity(인기도), title(영화제목) 등등

평점 전처리
현재 영화평점의 평균평점이 불공정하게 처리되어 있다.
그래서 데이터를 제공해준 imdb에서 제안한 weight rating으로 평점을 다시 처리한다.
아예 공식을 제공해주고 있어서 그 값을 적용해서 새로운 score컬럼 값을 생성한다.
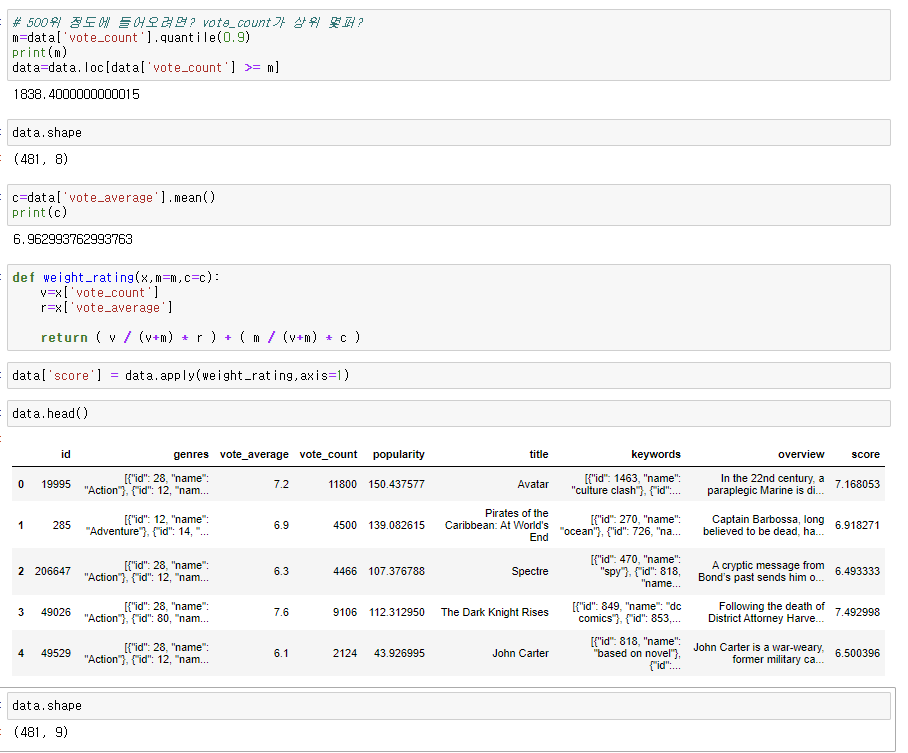
콘텐츠 기반 필터링을 위한 컬럼추출
사용자가 특정 아이템을 선호하는 경우, 그 아이템과 '비슷한' 콘텐츠를 가진 다른 아이템을 추천해주는 방식
이때 '비슷함'의 기준을 장르와 키워드로 분석할 수 있다.
그런데 장르와 키워드의 값은 list안에 dict이 포함된 구조이다.
근데 이걸 string으로 변환해주어야하기 떄문에 ast 패키지 안에 있는 literal_eval로 변환시킨다.
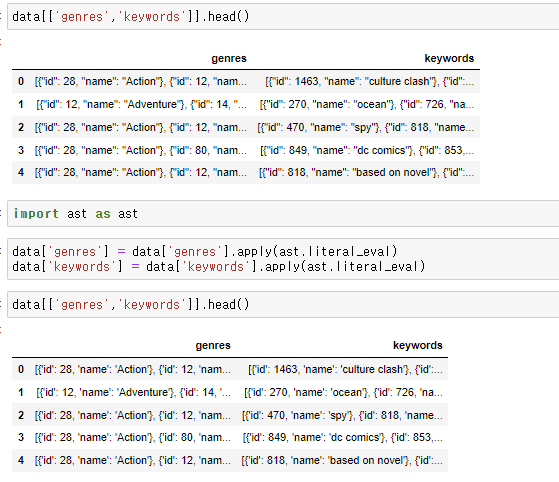
바뀐 내용이 없어보이지만, 이제 genres안에 있는 값들을 dict형식으로 되어 있어서 key를 가지고 뽑아올 수 있따.
그리고 그 값을 string으로 변환하는것 까지 lambda를 apply해서 장르와 키워드 값을 변형한다.

3. 콘텐츠 기반 필터링추천
장르 벡터화
장르를 기준으로 필터링할 경우 (즉, 유사한 장르를 추천해주는 경우)
일단 장르 들은 띄어쓰기가 구분된 한 문자열로 저장이 되어 있는데
이 문자열을 숫자로 바꿔서 벡터화 시켜야한다.
python scikit learn에 있는 CountVectorizer를 사용한다.
pip install sklearn

유사도값 추출 (코사인유사도)
이제 장르를 기준으로 유사도값을 계산한다.
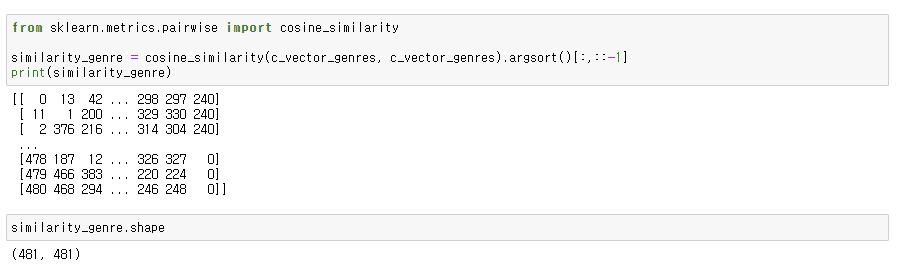
4. 영화추천 사용자 함수 생성
그리고 이 장르기반의 유사도를 기준으로 영화를 추천해주는 사용자 함수를 정의한다.
그래서 영화 제목을 검색(?)하면 유사한 장르의 영화를 추천해주게 된다.

실제로 avatar를 보았다고 했을때, 이와 유사한 영화에 대한 결과이다.
SF나 판타지, 액션어드벤처 장르으 영화들이 추천 된 걸 볼 수 있다.
출처
https://lsjsj92.tistory.com/565?category=853217
'🌿 Data Engineering > Data Analysis' 카테고리의 다른 글
| [텍스트분석] 01.텍스트 분석 수행 프로세스 (0) | 2021.09.04 |
|---|---|
| 추천시스템04. 잠재요인 협업필터링(latent factor collaborative filtering) 구현 (0) | 2021.08.27 |
| 추천시스템03. 아이템 기반 협업 필터링 (collaborative filtering) 구현 (1) | 2021.08.27 |
| 추천시스템01. 추천 시스템(Recommendation)이란? 유형 알아보기 (0) | 2021.08.26 |
| [Pandas] 가상 쇼핑몰 고객주문 데이터 전처리2 - 국가별,월별,요일별,t시간대별 매출 (0) | 2021.08.24 |
| [Pandas] 가상 쇼핑몰 고객주문 데이터 전처리1 - null처리 및 타입변경 (0) | 2021.08.24 |



