아래의 글은 T아카데미 아파치 스파크 입문 강의를 듣고 정리한 내용입니다

3강. Spark 데이터처리 실습1
RDD
Spark의 기본 데이터구조
계속해서 가공을 하면 계속 변환되면서 새로운 RDD가 생긴다(Transformation)
DataFrame과 성능도 동일하다
예를 들어 log mining을 한다면
처음에 초기에 받아온 로그데이터들은 base RDD가 되고,
에러만 뽑아오는 Transform단계를 거치면 새로운 error RDD가 생성.
이제 그 에러메세지 중에서 원하는 Action을 수행하는 단계애선
필터에 대해서 count하고 싶다던지, spark dirver로 이벤트를 보낸다.
RDD V DataFrame
RDD : Spark의 low-level interface, 직접 데이터를 핸들링하는 api
DataFrame : 스키마를 가지고 있는 구조, 캐시도 되고, 최적화도 댐-> 언어에 상관없이 동일한 성능을 가짐

RDD Fault Tolerance
특정 노드에 리소스가 없거나, 문제가 발생하게 되면 맵리듀스는 다시 디스크를 읽고, 다시 re computing.
스파크에서는 RDD기준으로 다시 시작한다. (각각의 Transformation단계로 retry를 한다)
Java. Scala.Python
Spark자체는 JVM에서 돌아가기 떄문에 Java언어를 사용할 수 있지만,
Java보다 코드 간결성, 직관성을 목적으로 Scala기반으로 Spark가 개발 된거.
초기RDD프로그래밍을 할때는 python이랑 Scala랑 성능차이가 났다.
하지만 이제는 둘다 api기능이 많이 나왔어서 거의 차이가 없다.
python, pyspark 권장 , java는 코드양이 많아짐, spark 어플리케이션만든다면 scala도 가능
Scala의 기본
functional 언어
var : 변수선언 , read-only, 자동으로 타입전환
def : 함수선언 , 마지막줄이 return되는 구조
Spark Operations
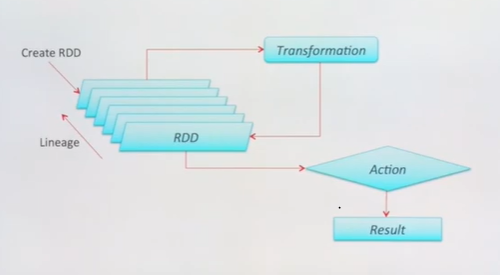
- Transformation : rawdata를 읽고 계속 변형(map,filter,groupby,join 등) 을 함 (새로운 rdd를 계속생성)
- Actions : Spark가 일을 하는 시점, spark dirver로 결과를 리턴하거나 저장 (count,collect,save 등)
참고
https://techblog-history-younghunjo1.tistory.com/151?category=964362
[PySpark] Apache Spark 와 RDD 자료구조
🔊 본 포스팅은 Apache Spark 3.0.1 공식 문서를 직접 해석하여 필자가 이해한 내용으로 재구성했습니다. 혹여나 컨텐츠 중 틀린 내용이 있다면 적극적인 피드백은 환영입니다! : ) 이번 포스팅에서
techblog-history-younghunjo1.tistory.com
'Book & Lesson' 카테고리의 다른 글
| [데엔스터디3] 데이터엔지니어를 위한 SQL 실습 (0) | 2021.08.25 |
|---|---|
| [Spark강의4-2] Spark 데이터처리 실습2 -DF Transformation (0) | 2021.08.23 |
| [Spark강의4-1] Spark 데이터처리 실습2-DAG개념 (0) | 2021.08.23 |
| [Spark강의3-1] Spark 데이터처리 실습1 (0) | 2021.08.22 |
| [Spark강의2] Spark의 실시간/배치 (0) | 2021.08.18 |
| [Spark강의1] Spark의 개념과 활용 (0) | 2021.08.18 |



