pandas의 기본적인 데이터구조인 Series와 DataFrame
데이터엔지니어링/데이터사이언티스트 교육을 통해 배운내용을 복습하고, 추가로 공부한 내용을 정리하였습니다.

아래의 주피터내용은 여기 깃허브에서 확인할 수 있습니다.
pandas를 사용하기에 앞서 numpy와 pandas 패키지를 모두 import해야한다.
import numpy as np
import pandas as pd
Series(시리즈)
1차원 배열의 값에 대응되는 인덱스를 부여할 수 있는 구조
1. 시리즈 정의 : pd.Series()
python의 list나 numpy가 array인자로 입력된다.
시리즈의 결과는 왼쪽에 index값, 오른쪽에 value가 동시에 확인된다.
왼쪽결과는 일반적인 series를 정의한 경우이고, 오른쪽은 index를 직접 명시해서 정의한 경우이다.
직접 명시할 경우 - 변수 = pd.Series([값1,값2..], index=[인덱스1,인덱스2])
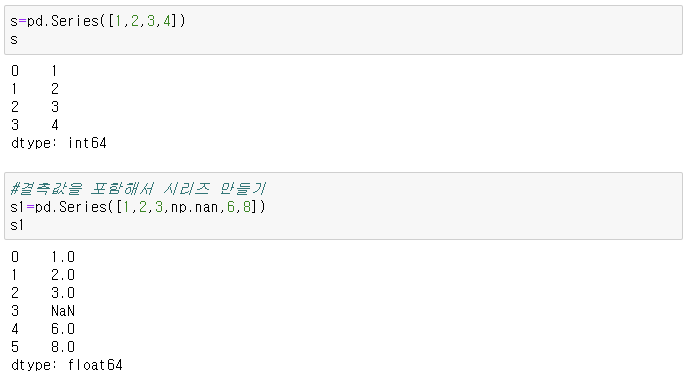

2. 시리즈 확인
index와 value가 동시에 확인된다. 리스트 성분의 개수 = index의 개수
왼쪽결과는 일반적인 series(s1)에 대한 index,value,데이터타입을 확인한 경우이고,
오른쪽은 index를 직접 명시해서 정의한 series(s2)에 대한 확인결과이다.


3.Series특징
1) pd.Series()의 인자에는 list, np.array() / dict가 가능하다
python dict의 key는 index, dict의 value는 value가 되기 떄문에 딕셔너리 그 자체가 series의 원소가 될 수 있다.
대신 순서를 보장하지 않으며, 순서가 중요한 경우는 인덱스를 직접 리스트로 지정해야한다.
왼쪽결과는 딕셔너리 그 자체로 series를 정의한 경우이고,
오른쪽은 index를 김/이/조 순서대로 직접 명시해서 정의한 series결과이다.

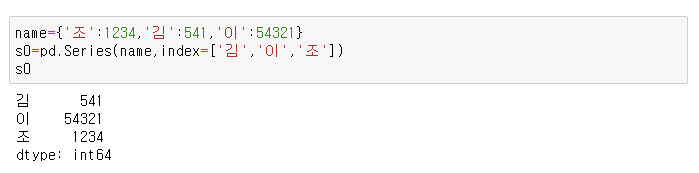
2 ) Series의 이름과 index에 이름을 지정해 줄 수 있다
- series변수.name = "시리즈이름"
- series변수.index.name = "인덱스이름"
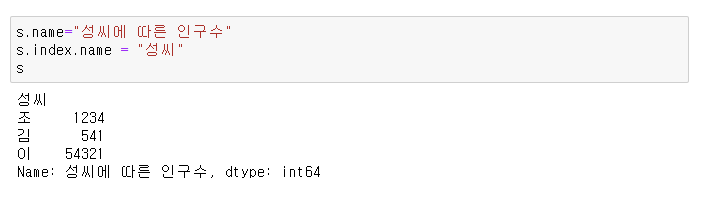
3) 직접 입력한 index를 나중에 바꿀 수도 있다.
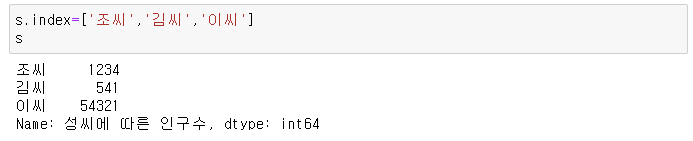
4) 조작도 가능하다 (조회, 변경, 추가, 삭제, 확인)
- 조회 : s[조건]
- 변경 : s[index] = 바꿀value
- 추가 : s['새로운index'] = 새로운 value
- 삭제 : del s[index]
- 확인 : value in s
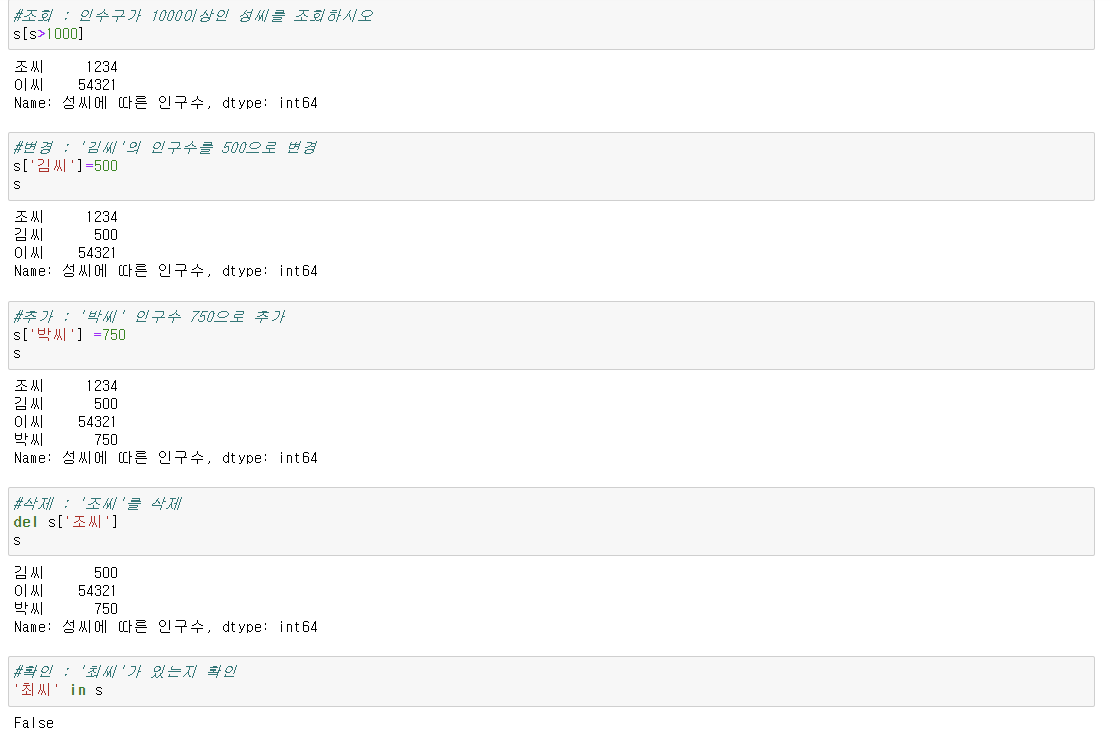
참고
https://nittaku.tistory.com/110
10. pandas의 자료구조 Series와 DataFrame 살펴보기
pandas는 핵심라이브러리로, 고유한 자료구조인 Series와 DataFrame으로 빅데이터 분석에 높은 수준의 퍼포먼스를 발휘한다. Series와 DataFrame는 앞서 공부한 numpy의 1차원과 2차원 array과 매우 유사하다.
nittaku.tistory.com
'🌿 Data Engineering > Data Analysis' 카테고리의 다른 글
| [Pandas 데이터전처리] 3-2.Dataframe 조작함수2 apply,cut,set_index (0) | 2021.07.15 |
|---|---|
| [Pandas 데이터전처리] 3-1.Dataframe 조작함수1. value_counts(), 정렬 (0) | 2021.07.15 |
| [Pandas 데이터전처리] 2-2.Pandas 데이터구조(Dataframe 인덱싱) (0) | 2021.07.15 |
| [Pandas 데이터전처리] 2-2.Pandas 데이터구조 (DataFrame) (0) | 2021.07.15 |
| [Pandas 데이터전처리] 1. Numpy,Pandas 라이브러리 알아보기 (0) | 2021.07.15 |
| [Python] Pandas 사용법 (0) | 2021.04.28 |



