일단 각각의 3개의 서버에 카프카와 주키퍼가 설치된 상태이다.
그리고 서버3은 주키퍼리더고, 나머지는 팔로워다.
이전까지 aws에 구성한 카프카 클러스터는 '서버'다.
즉 메세지를 처리하는 부분이긴 하지만 데이터를 주고받는 테스트를 위해서는 '클라이언트'가 필요하다.
그리고 python으로 컨슈머와 프로듀서를 구현해보도록 하자.
아, 그 전에 브로커의 클러스터를 생성했는데 이 각각의 브로커안에 데이터를 저장할 '토픽'이 필요하다
그래서 일단1개의 브로커 즉 하나의ec2 서버에서만 테스트를 해볼 것이다.
안에서 topic을 생성해보고, 프로듀셔/컨슈머끼리 메세지가 전송되는지 확인
*단일브로커(ec2)
1. kafka 서버 실행한 상태

[root@ip-172-31-11-151 kafka_2.11-2.1.0]# ./bin/kafka-server-start.sh ./config/server.properties
2. topic생성
서버3에서 topic을 생성해보았다.
난 3개가 묶여 있을 줄 알고 zookeeper 옵션에 3개의 서버를 다 넣고, replication-factor를 3으로 지정했다.

근데 생각해보니까, 지금 하나의 서버에 zookeeper과 카프카를 하나씩 연결해놓은 상태이지 않나?
그러니까 zookeeper에서 단일브로커로만 topic을 만들수 있는것인가?

근데 또 토픽조회할떈 zookeeper에 3개 서버 다 넣네?
그래서 replication-factor 1로 결국 topic하나만 만들었다.
[root@ip-172-31-11-151 kafka_2.11-2.1.0]# ./bin/kafka-topics.sh
--create --zookeeper test-broker01:2181,test-broker02:2181,test-broker03:2181/test
--replication-factor 1 --partitions 1 --topic mytopic

3.프로듀서에서 데이터전송
일단 kafak서버를 커둔 상태에서 새로운 터미널창에서 콘솔 프로듀서 실행
./bin/kafka-console-producer.sh
--broker-list test-broker01:9092,test-broker02:9092,test-broker03:9092 \
--topic test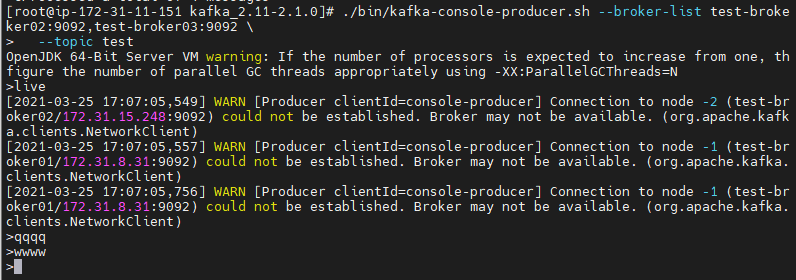
4.컨슈머가 데이터받음
동시에 다른 터미널창에서 콘솔 컨슈머 실행
./bin/kafka-console-consumer.sh
--bootstrap-server test-broker01:9092,test-broker02:9092,test-broker03:9092 \
--topic test --from-beginning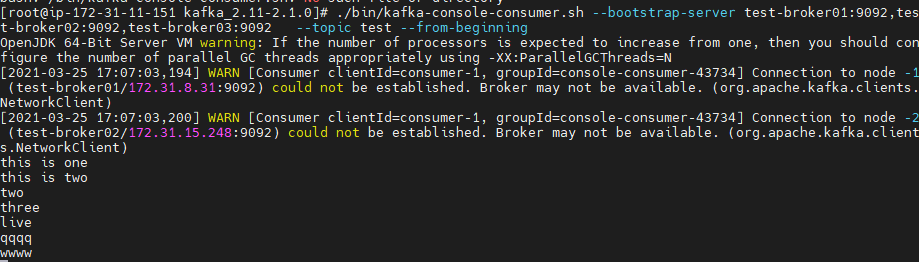
4. 결과
프로듀셔가 보낸 메세지(qqq)는 카프카서버(host: test-broker03)에 의해 실시간으로 컨슈머한테 메세지(qqq)전달
그래서 프로듀서가 메세지를 보낸 즉시 바로 컨슘서 창에서 메세지가 나옴(씬기)
'🌿 Data Engineering > Study' 카테고리의 다른 글
| [Spark] Apache Spark란? | 구조 및 동작방식 (0) | 2021.04.22 |
|---|---|
| [Spark] Apache Spark란? | 빅데이터 처리단계-분산처리/하둡/맵리듀스 (0) | 2021.04.22 |
| [Spark] Apache Spark란? | 빅데이터 처리단계 -수집과 저장/ETL/HBase (1) | 2021.04.21 |
| [Spark] Apache Spark란? | Spark정의를 알아보기까지 빅데이터흐름 (0) | 2021.04.21 |
| [kafka 기초] Spring boot웹 Producer->Kafka구현(Intellij 환경) (0) | 2021.03.28 |
| [kafka 기초] AWS에 카프카 클러스터(kafka,zookeeper) 구축하기 (0) | 2021.03.26 |



