아래의 내용 및 이미지는 [데브원영] 아파치 카프카 for begineers 강의 요약 및 추가 공부한 내용입니다. 감사합니다.
카프카는 파티션 단위로 분산처리를 수행한다.
이때 분산처리의 핵심은 '복제' -> 카프카의 가용성을 보장하는 가장 좋은 방법
모든브로커에게 데이터를 동일하게 보내는 것이 아니라 master->slave방향으로 데이터를 복제하는 것처럼 수행
브로커(Broker)
카프카가 설치되어 있는 '서버'단위 즉, 브로커1개를 모아서 처리할 수 있는 서버1개라고 볼 수 있을듯하다.
3개이상의 브로커로 클러스터 구성으로 사용하는 것 장

파티션이 1개이고, replication이 1인 topic이 존재하고, 브로커가 3개라면
브로커 3대 중 1대에 해당 topic의 정보(데이터) 저장
replication, 파티션의복제
1이라면 파티션이1개
2라면 원본1개와 복제본1개
3이라면 원본1개와 복제본2 개
브로커의 개수에 따라 replicaiton개수 제한
브로커의 개수가 3이면 replication4가 될수 없다
이떄 원본 한개의 파티션을 leader 파티션
나머지 파티션들을 follower 파티션
즉, 이 파티션들을 합쳐서 ISR(IN SYNC Replication)
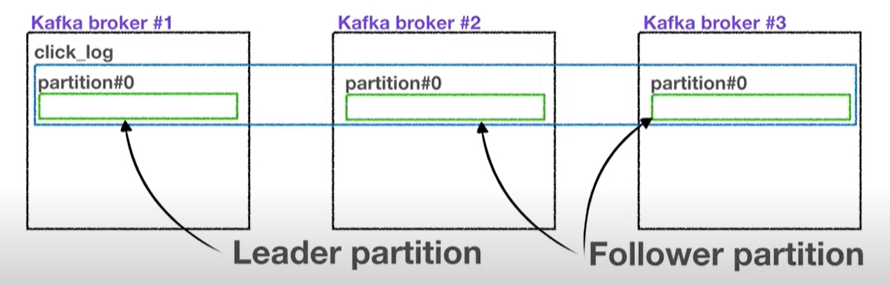
즉, 프로듀서가 리더파티션한테 메세지를 전송하고, 리더는 자신을 바라보는 팔로우 파티션에게 데이터를 복제한다.
왜 replication을 사용하는가?
고가용성을 위해 (장애대응 즉, 데이터의 유실을 막기 위해)
브로커가3개의 카프카에서 replication1이고, 파티션이1인 topic이 존재하는 경우
만약 브로커가 사용불가하게 된다면 더이상 해당 파티션은 복구불가
만약 replication이 2라면
브로커 한개가 죽더라도 복제본이 존재하므로 복구가능
복제본 파티션이 leader 파티션 역할을 승계하게 되는 것

리더파티션과 팔로워파티션의 역할
프로듀셔가 topic의 파티션에 데이터를 전달할때, 이떄 전달받는 주체가 리더파티션
ack : 프로듀셔의 상세옵션
0,1,all 중 하나를 골라서 사용가능, replication과 관계

ack가 0일 경우
리더파티션에 데이터를 전달하고, 응답값을 받지 않는다.
그래서 리더파티션에 데이터가 정상적으로 전송되었는지, 나머지 파티션에 정상적으로 복제되었는지 알수 없음
즉, 리터파티션을 전달되는 속도는 빠르지만
리더파티션의 브로커가 장애가 났을 경우 제대로 전송되었는지 확인하지 못해서 데이터유실 가능성이 있다
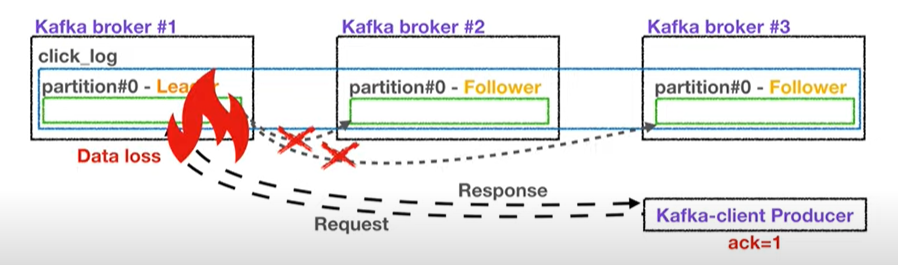
ack가 1일 경우
리더파티션에 데이터를 전달하고, 정상적으로 전달이 되었는지 응답값을 받는다.
다만 나마지 파티션에 정상적으로 복제되었는지는 알 수 없음
즉, 리더파티션이 데이터를 받은 즉시 브로커가 장애가 났을 경우
나머지파티션에 데이터가 미처 전송되지 못한 상태라 데이터 유실 가능성이 있다

ack가 all일 경우
리더파티션에 데이터를 전달하고, 정상적으로 전달이 되었는지 응답값을 받는다.
리터파티션에 데이터를 보낸후 나머지 팔로우 파티션에도 데이터가 저장 되는 것을 확인하는 절차를 거친다
즉, 데이터의 유실은 적지만 ack1과 ack0에 비해 확인하는 과정이 많아 데이터전달 속도가 현저히 느리다
그럼 replication이 많을수록 좋은게 아닌가? 많을수록 브로커의 리소스 사용량이 많아짐
즉, 카프카에 들어오는 데이터량과 retention date(저장시간)을 고려해서 replication개수를 정해야한다
3개이상의 브로커를 사용할땐 replication 3 권장

'Book & Lesson' 카테고리의 다른 글
| [책정리] 빅데이터를 지탱하는 기술 목차 (0) | 2021.06.16 |
|---|---|
| kafka강의6 | 카프카 버로우(Burrow) (0) | 2021.03.25 |
| kafka강의5 | 컨슈머 랙(Consumer Lag)이란? (0) | 2021.03.25 |
| kafka강의4 | 파티셔너(Partitioner)란? (0) | 2021.03.24 |
| kafka강의2 | Topic이란? Pub/Sub 구조 (0) | 2021.03.22 |
| kafka강의1 | 아파치 카프카(Apache Kafka)란? (0) | 2021.03.22 |



