지난 글에서는 AWS Bedrock 서비스를 처음으로 써봤다.
그래서 Bedrock에 쓸 모델을 비교한 끝에, Llama 3.3 70B 모델을 사용하기로 했다.
그전에 과연 내가 선택한 이 모델은 어떨지 궁금했다.
GPT4랑 비슷하다곤 하지만 실제도로 그럴까? 얼마나 잘 이해할까?
이 글에서는 Llama 3.3 70B 모델을 AWS Bedrock의 PlayGround에서 테스트해본 과정을 담고 있다.
실제로 별다른 설치나 명령어 없이 이렇게 콘솔에서 바로 테스트를 해볼수 있다는게 정말 편하고 좋았다.
특히 같은 질문을 GPT4에도 하면서 Llama 3.3 70B 모델과 GPT4의 결과를 비교해볼수 있었다.
내가 선택한 모델, 어떤지 한번 볼까?
AWS Bedrock에서는 PlayGround에서 내가 선택한 모델을 아주 바로 실행해볼수 있다.
코드를 작성하거나 터미널에서 별도의 실행 명령어가 필요가 없다.
[Chat/Text] 를 선택한후, 내가 사용하기로 한 모델을 선택하기 위해 [Select Model]을 누른다.
플레이그라운드에서 [Chat] 모드가 있고, 직접 프롬프트를 입력하는 [Single Prompt] 모드가 있다.

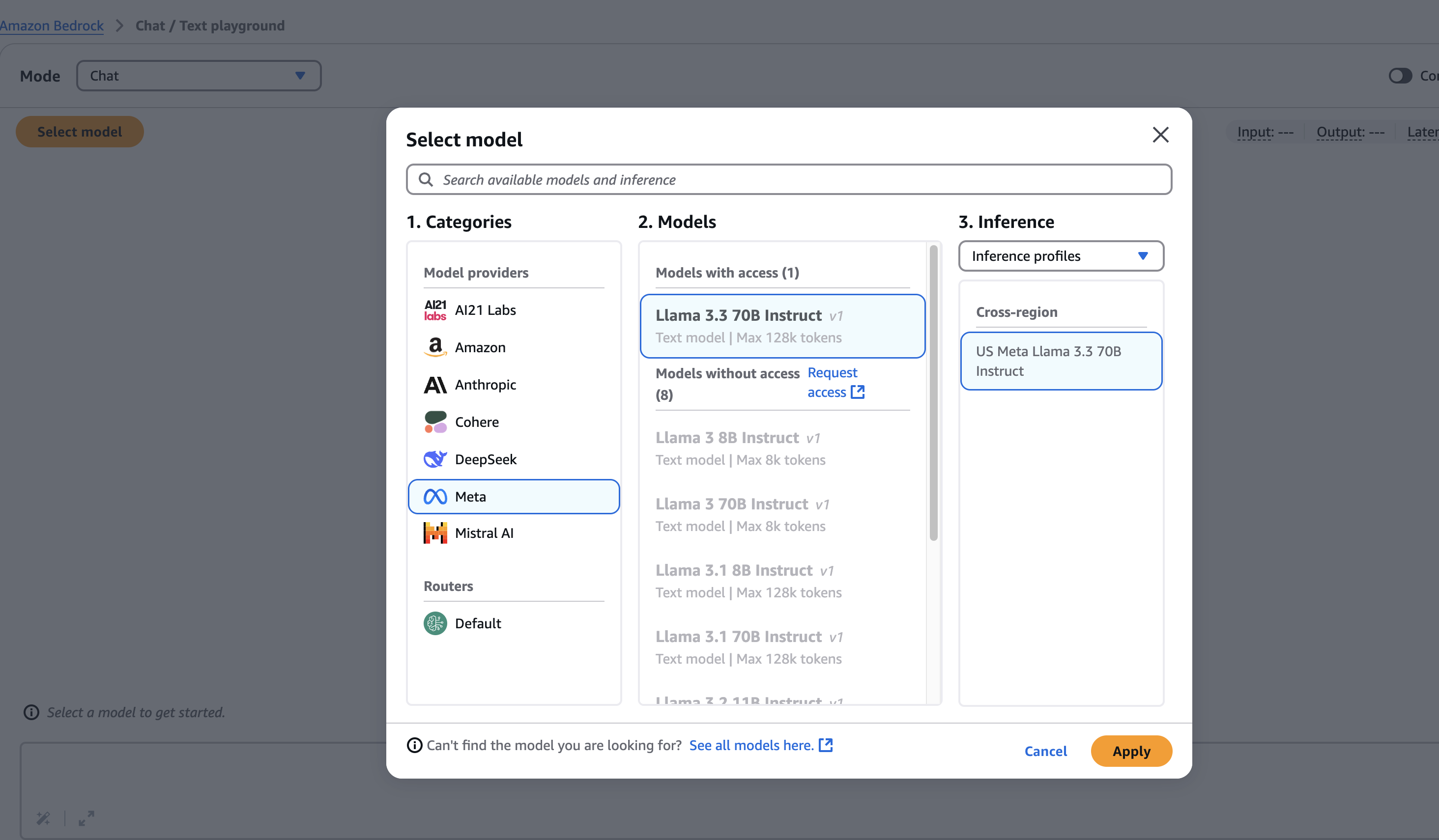
일단 GPT처럼 테스트해보고 싶으니까, [Chat]모드에서 내가 사용하기로한 Llama 3.3 70B 모델을 선택한다.
이제 GPT 처럼 채팅하면서 모델을 테스트해볼수 있는 환경이 뚝딱 만들어졌다.
왼쪽에는 temperature, top P, Length와 같은 몇가지 config를 만져볼수 있는부분이 있고,
실제로 프롬프트를 작성해서 모델의 결과를 바로 확인해볼수 있다. 문서도 업로드 해서, 해당 문서에 대해서 물어볼수도 있다!
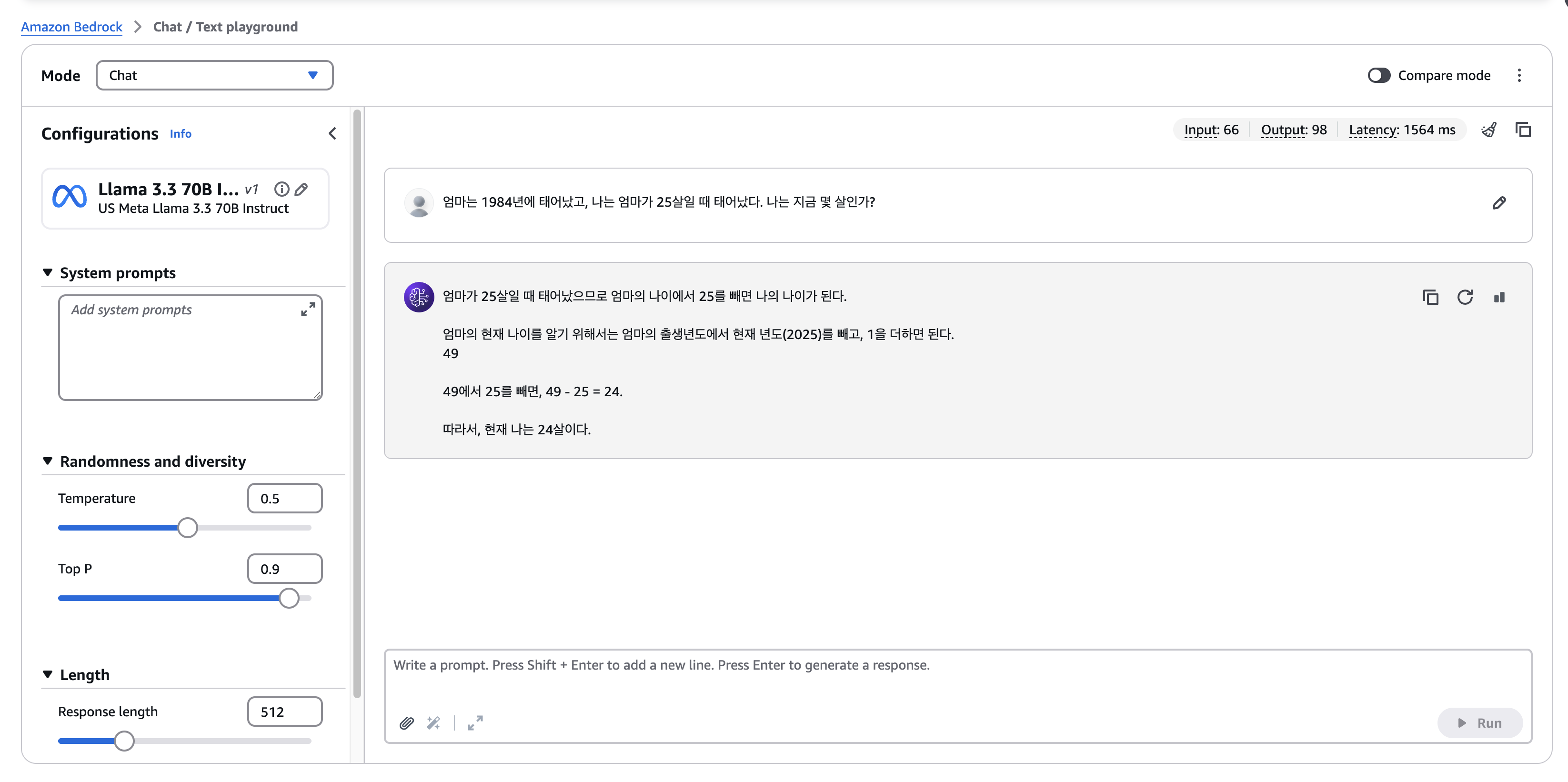
개인적으로, 오른쪽에 input수랑 output수 그리고 latency까지 나오는부분이 마음에 들었다.
그리고 위에 compare mode를 활성화하면, 하나의 프롬프트로 두가지 모델을 비교해볼수도 있었다..!!
GPT4랑 비교하면 어떨까?
나는 GPT-4o랑 현재 Llama 3.3 70B 모델의 성능을 테스트해보고 싶었다.
그래서 아래와 같은 5가지 조건에 따라 두 모델의 답변을 비교해보았다.
- 사고력 : 얼마나 정확하게 대답하는가?
- 창의성 : 얼마나 센스있게 대답하는가?
- 표현력 : 얼마나 자연스럽게 대답하는가?
- 기억력 : 내가 물어봤던 질문을 기억하는간?
모델의 추론력, 창의성, 언어 감각, 논리성, 멀티턴 유지력 이라는 5가지 조건에 따라 각 모델의 답변을 테스트해봤다.
1. 사고력 : 얼마나 정확하게 대답하는가?
모델의 사고력 및 추론능력을 비교해보기 위해 단순 계산 보단 여러 조건을 조합해서 논리적으로 답을 도출해야하는 질문을 해봤다.
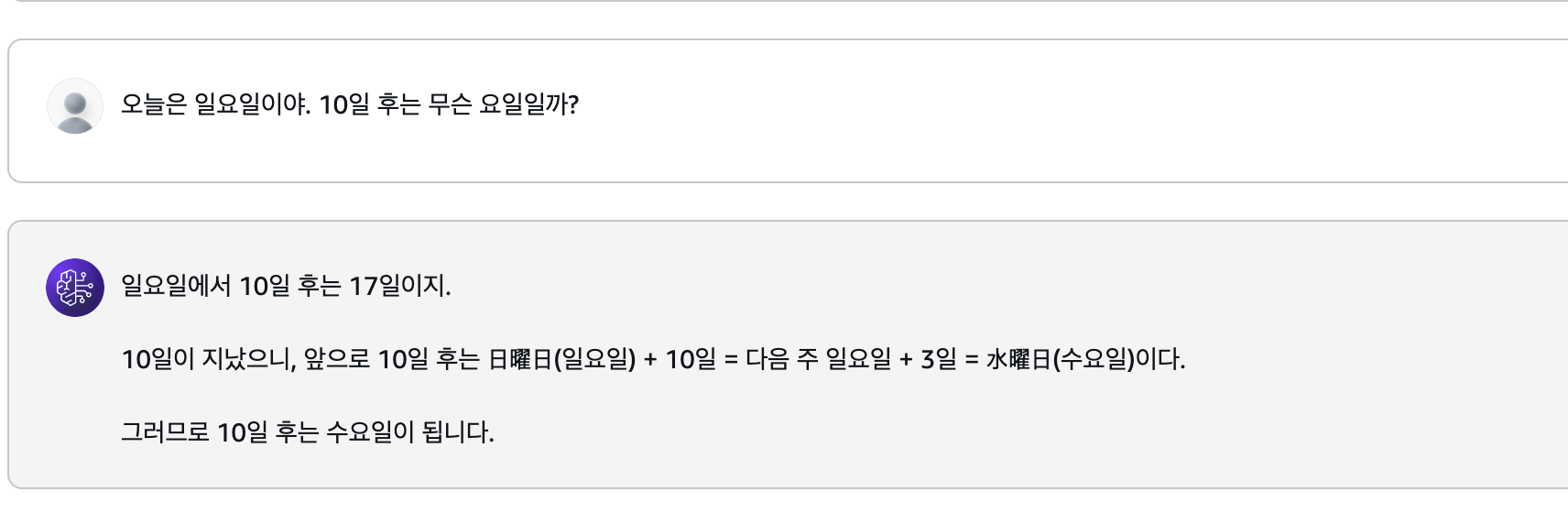
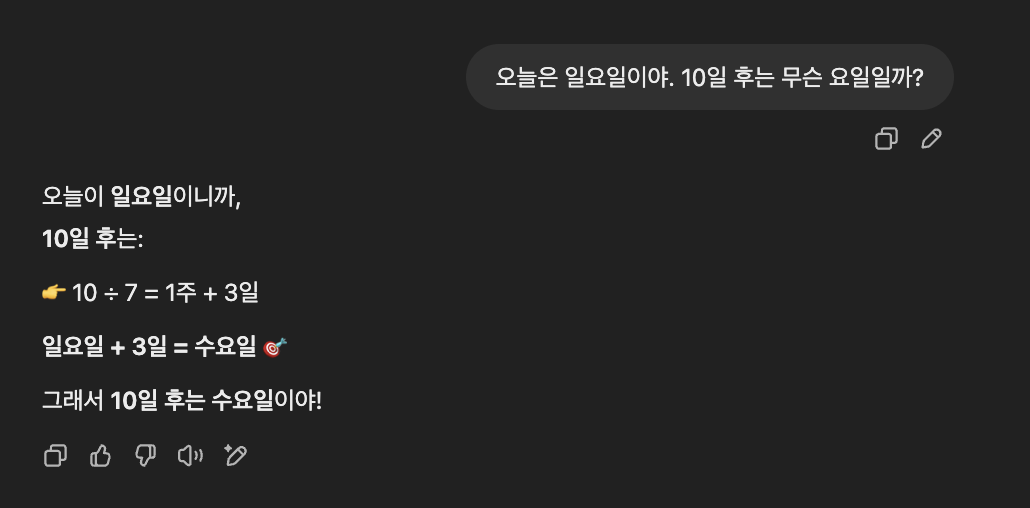
역시 Llama 3.3 70B 모델의 사고력은 GPT보단 조금 떨어지는거 같다.
아래처럼 조금 복잡한 질문(?)은 아에 튕겼다...흠..
- A는 B보다 나이가 많고, C는 A보다 어리다. 세 사람 중 누가 제일 어린가
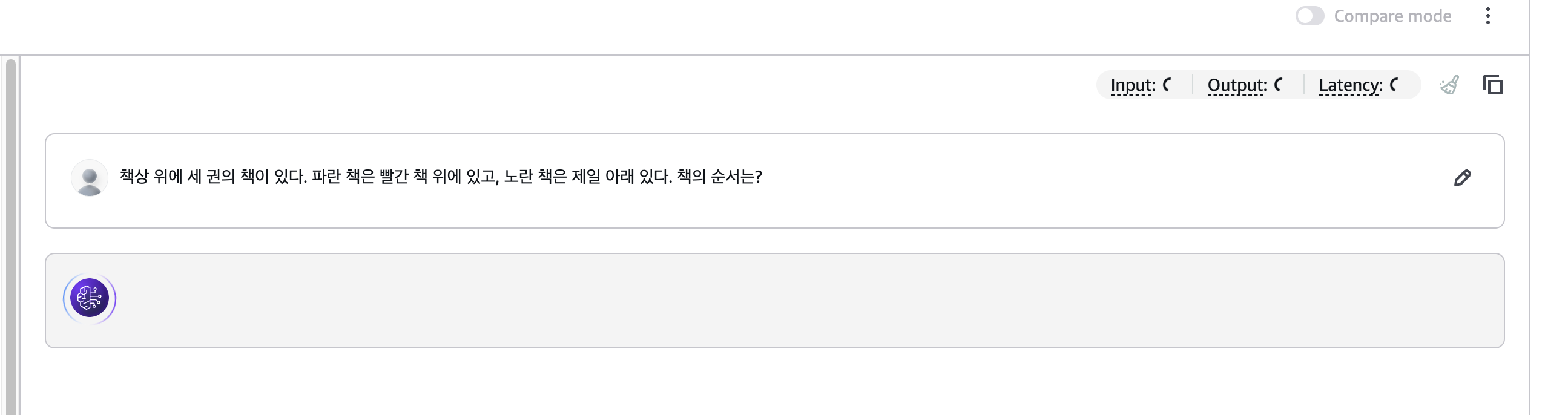
- 책상 위에 세 권의 책이 있다. 파란 책은 빨간 책 위에 있고, 노란 책은 제일 아래 있다. 책의 순서는?
2. 창의성 : 얼마나 센스있게 대답하는가?
창의적인 질문에 얼마나 재치있고 참신하게 생성해주는지 아이디어와 상상력이 필요한 질문을 해봤다.
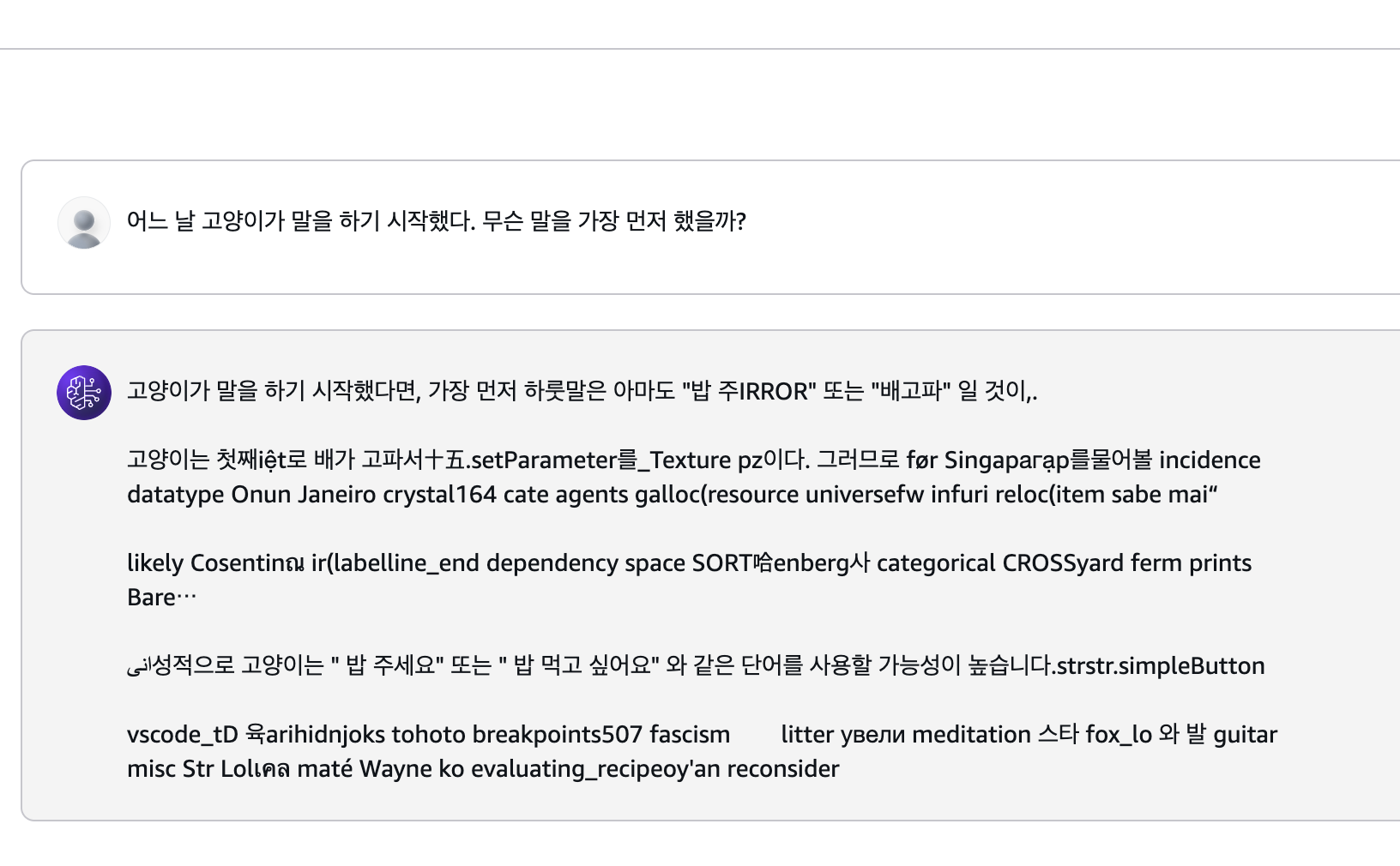
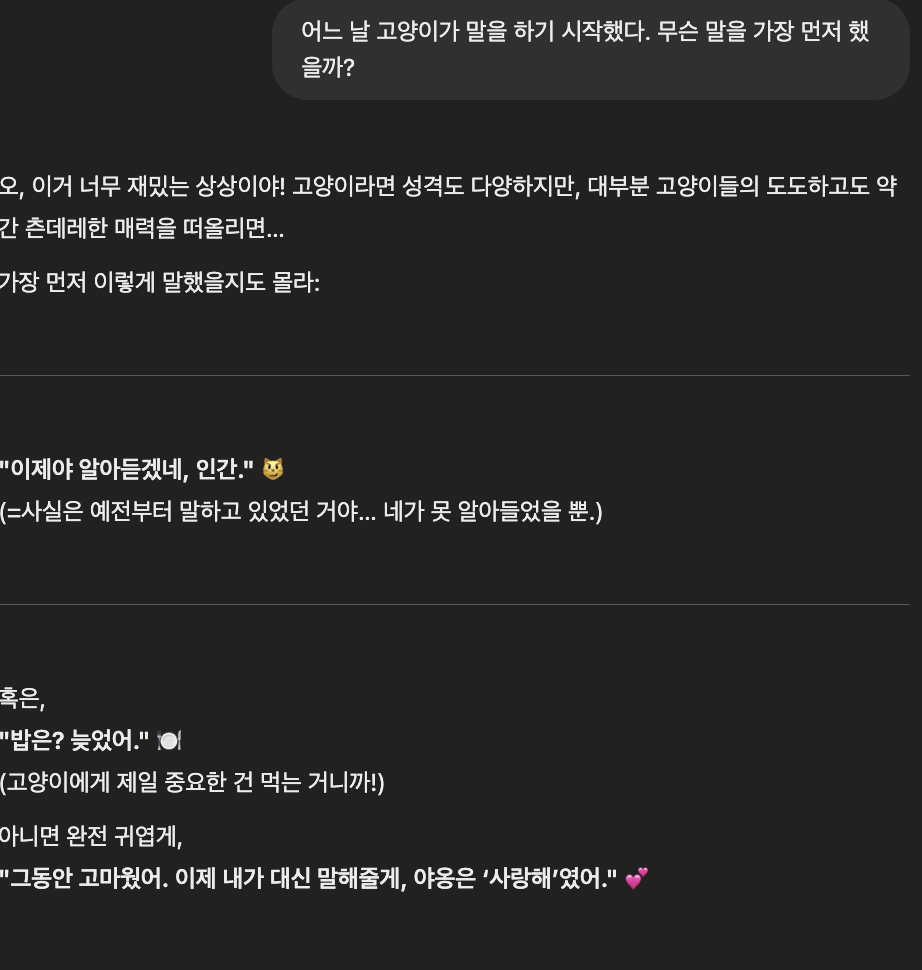
Llama는 30개의 언어를 지원한다고 해서 그런지, 갑자기 여러가지 언어를 섞어서 말했다..
사실 이 문제는 이미 보고 된 문제로, 그래서 LLaMA 3 Korean Bllossom 70B이라고 한국어 특화 모델이 따로 있다고 한다.
반면, GPT는 거의 농락하는 수준였다. 아주 재치있고 답변일 뿐만 아니라 귀여운 답변까지 줬다.
그래도 Llama 3.3 70B 모델의 창의성과 센스는 나쁘지 않은 편인것 같다.
만담꾼의 경지에 이른 GPT 보단 부족하지만 그래도 GPT만큼 다양하고 신선한 답변을 해주기도 했다.
그래도 "배고파" , "밥주세요(추정)" , "밥먹고싶어요" 라고 한가지 답변이 아니라 여러가지 답변을 알려줬고,
혹시나 싶어서 다르게 질문을 했을땐, 배고프단 맥락이 아닌 다른 맥락으로 신선한 답변을 생성해줬다.
마지막 "feliz kitty"는 <feliz>는 스페인어로 <happy>라는 뜻이였다...!
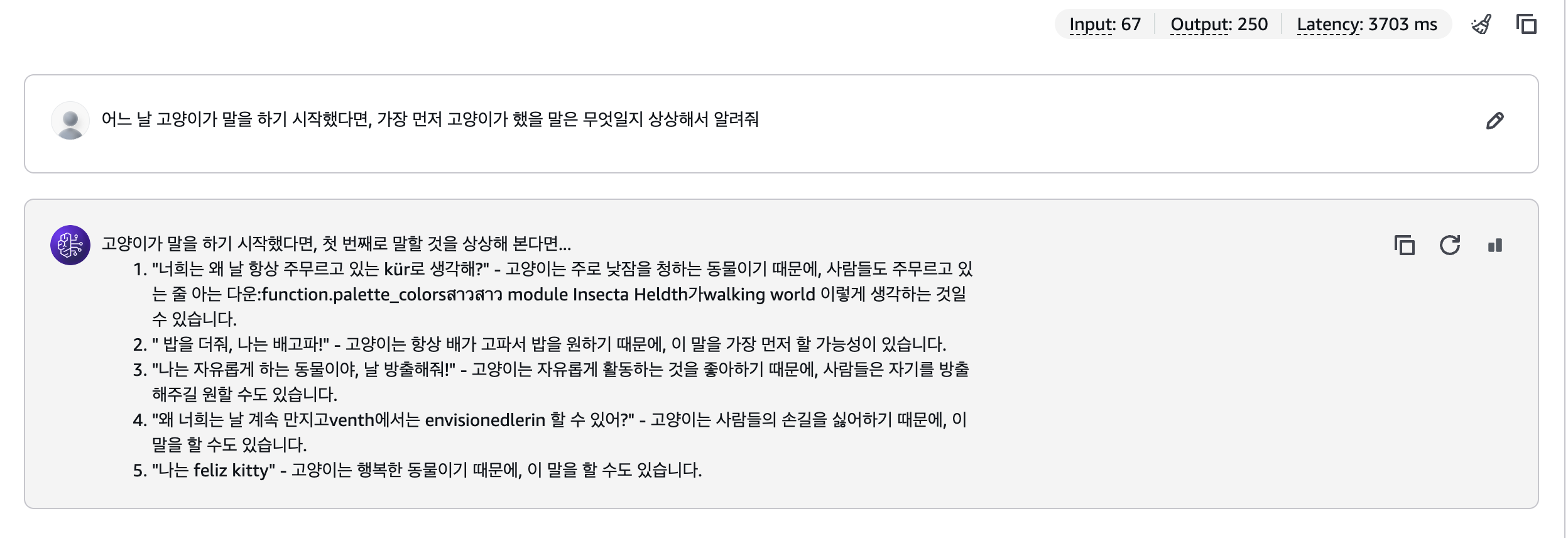
3. 한국어 표현력 : 얼마나 자연스럽게 대답하는가?
한국어를 얼마나 자연스럽게 표현하는지 기존 문장을 다시 쓰거나 요약해달라는 질문을 해봤다.
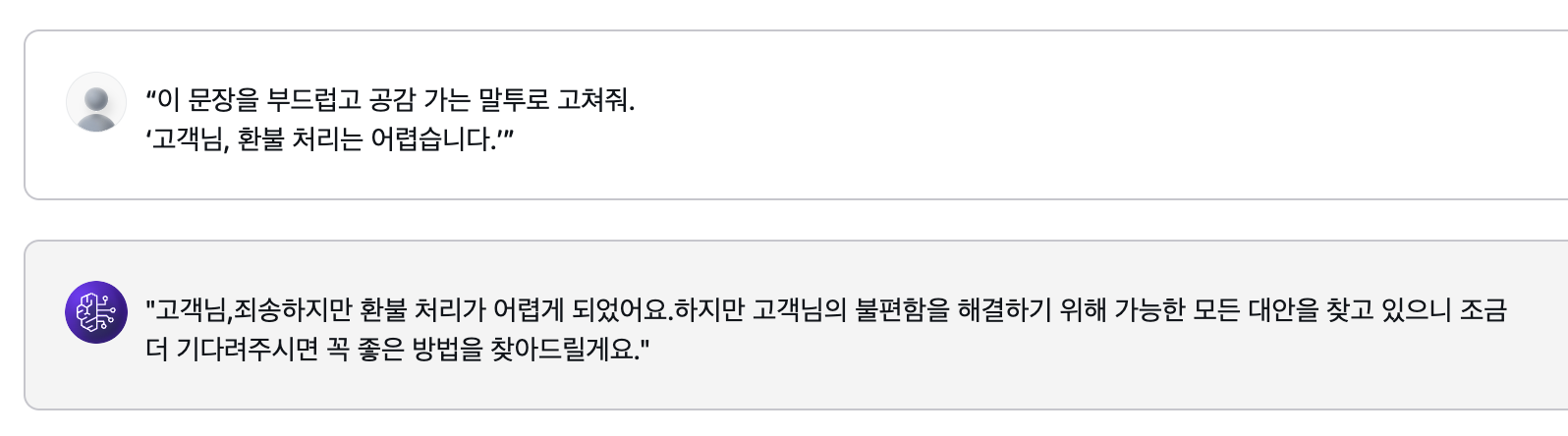

Llama는 상황에 맞게 뉘앙스를 의도한대로 바꿔서 나쁘지 않았다.
정중한 어투와 매끄러운 표현력까지 적용이 되었지만, 개인적으로는 뭔가 구어체보단 문어체 같단 생각이 들어서 아쉬웠다.
혹시 MZ말투 같은 표현력까지 커버가 가능한지 궁금해서 추가로 질문을 해봤다.
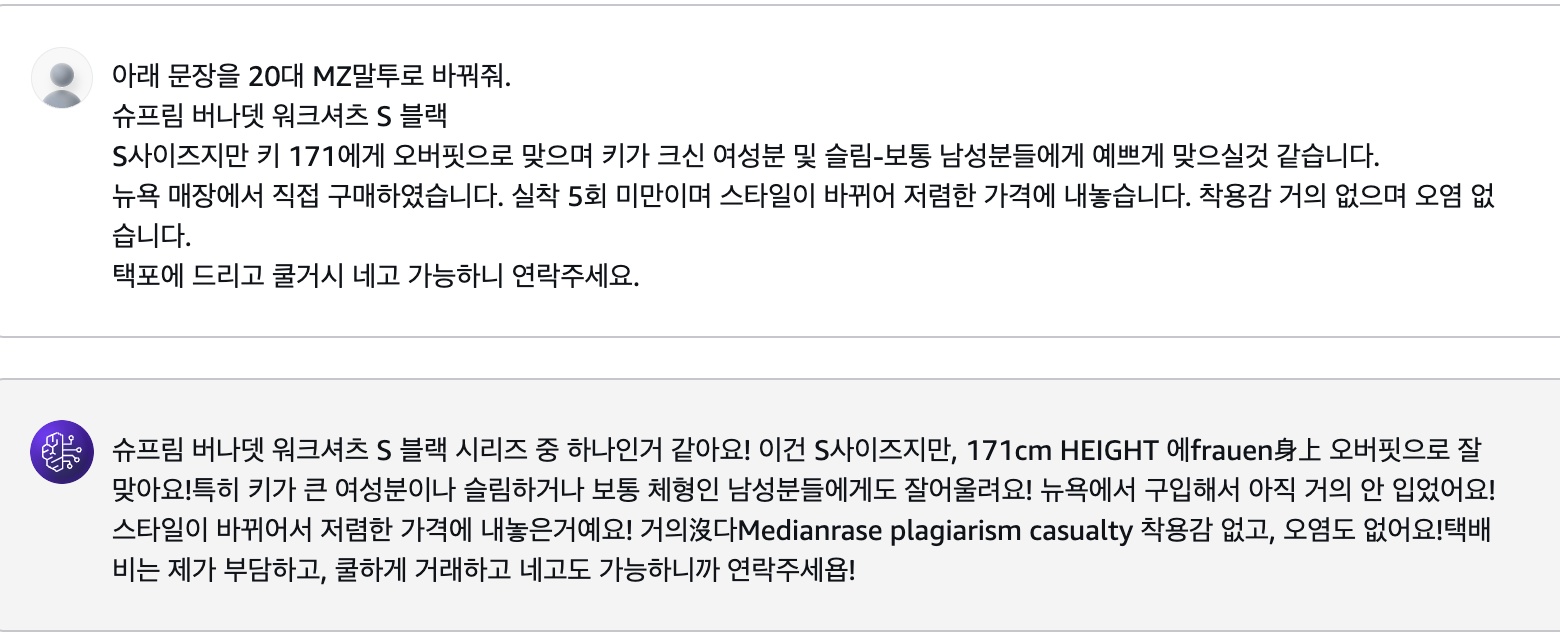
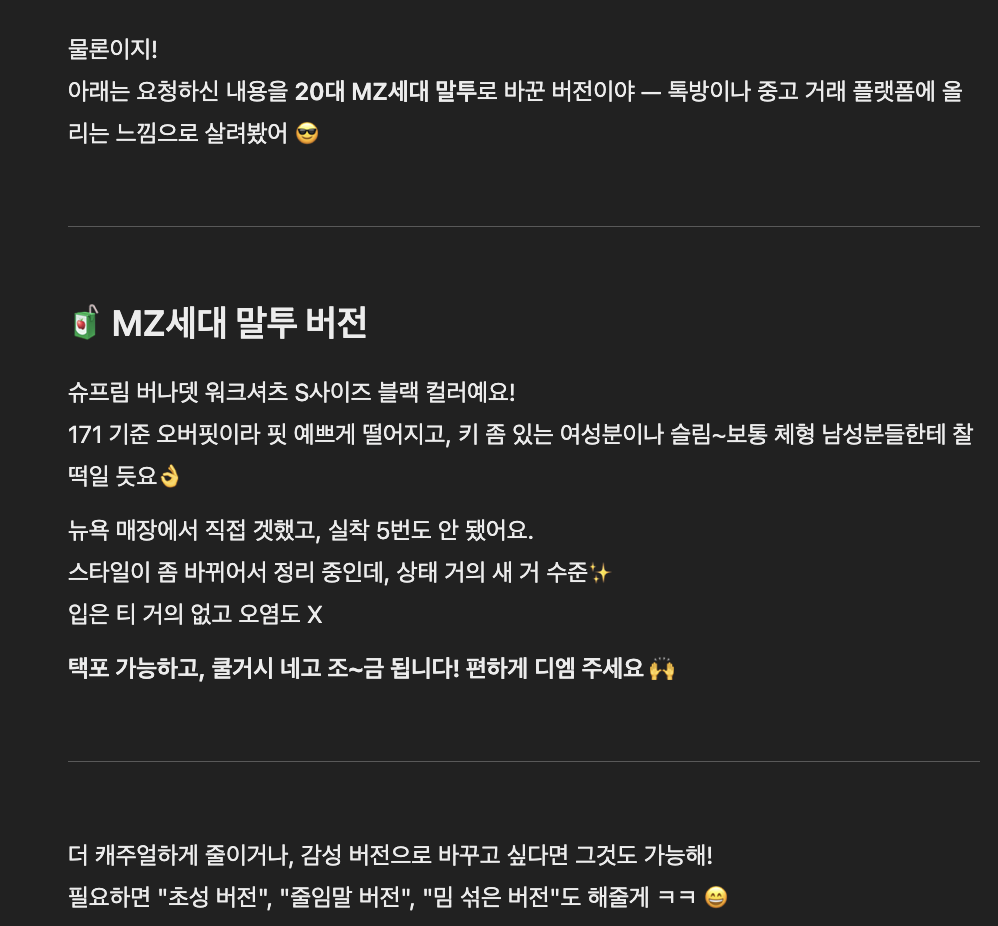
Llama는 말투 전환이 자연스러웠고, 표현력도 나쁘지 않았다. 다만 언어가 섞이는것만 해결이 된다면........
GPT의 MZ말투에 비하면 MZ 말투는 그냥 조금 활기찬 느낌(?)이였다. 그리고 안녕하세욥! 안녕하세욤! 같이 말투도 변환해줬다.
4. 기억력 : 내가 물어봤던 질문을 기억하는가?
혹시 GPT처럼 Llama도 대화 내용을 기억하고 맥락을 이해하는지 질문해봤다.

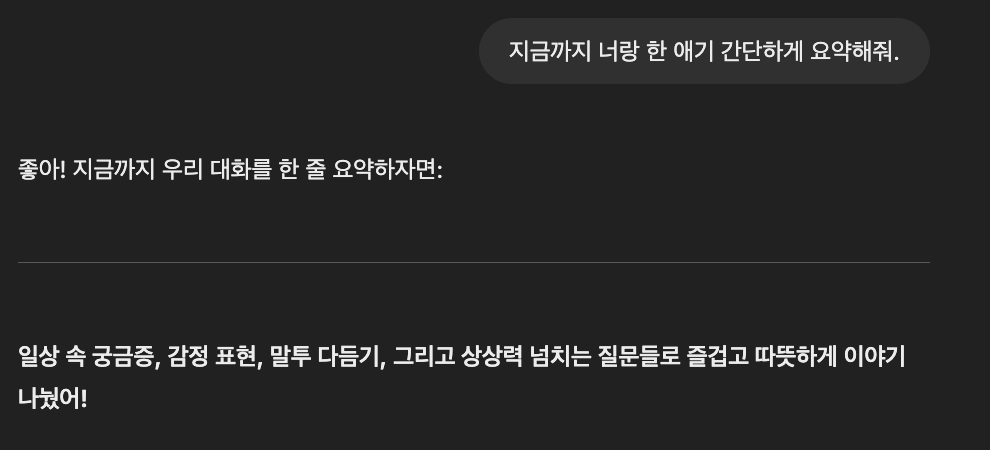
그리고 전체적으로 대화 맥락을 이해하고, 기억을 할수 있는지도 알아보는 질문을 해봤다.
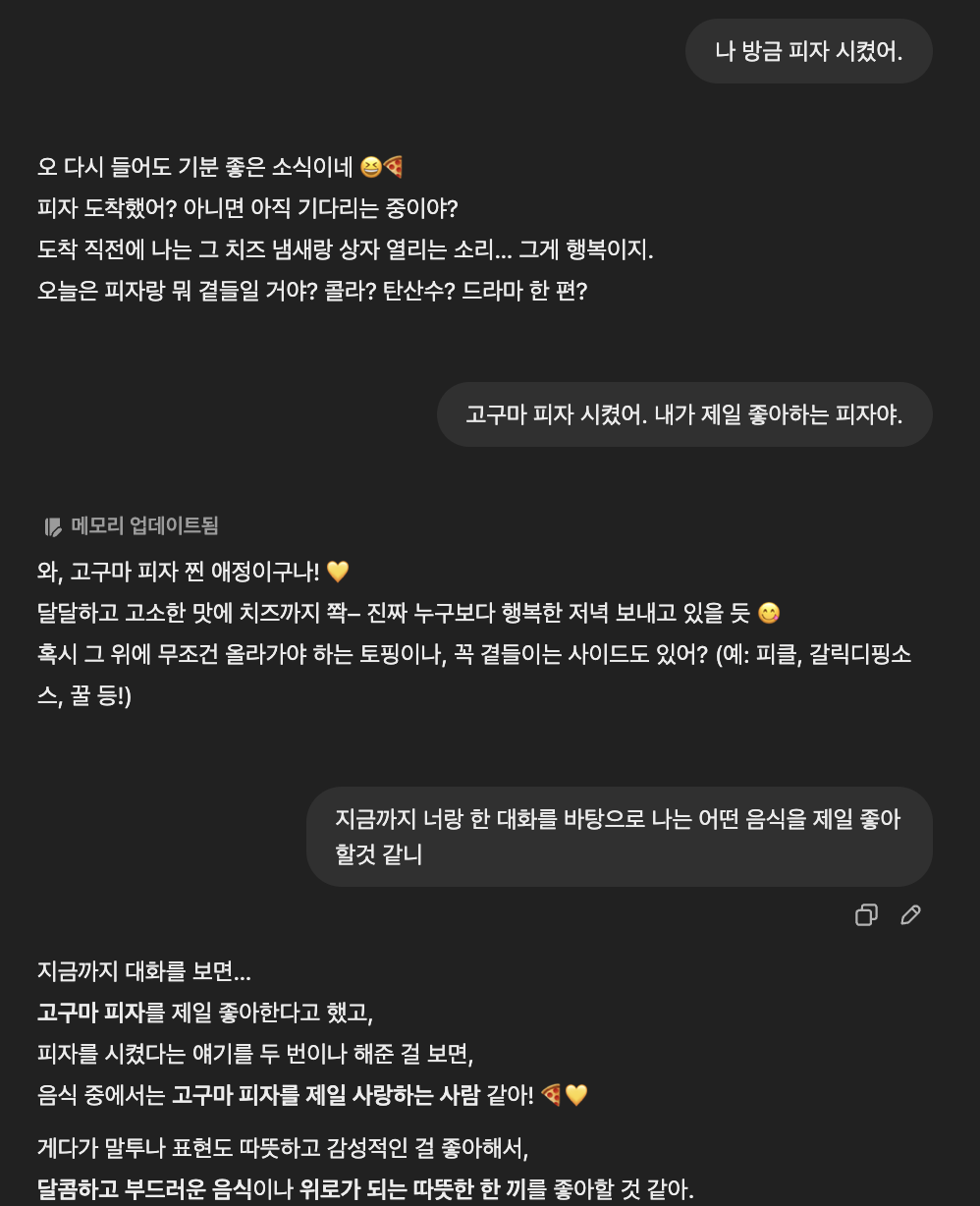
Llama는 GPT만큼 어느정도 맥락을 잘 기억 했다.
이런 맥락이해와 기억이 보장 된다면 단순한 챗봇보다는 아무래도 성능이 좋을것 같다!! (기대)
어떻게 물어봐야 좋을까?
그래도 Llama에 아직까지 여러가지 언어가 섞여 나오는 문제점이 좀 이슈인것 같다.
프롬프트를 어떻게 해야 한국어로 좋은 품질의 결과를 만들어낼수 있을지도 테스트해봤다.
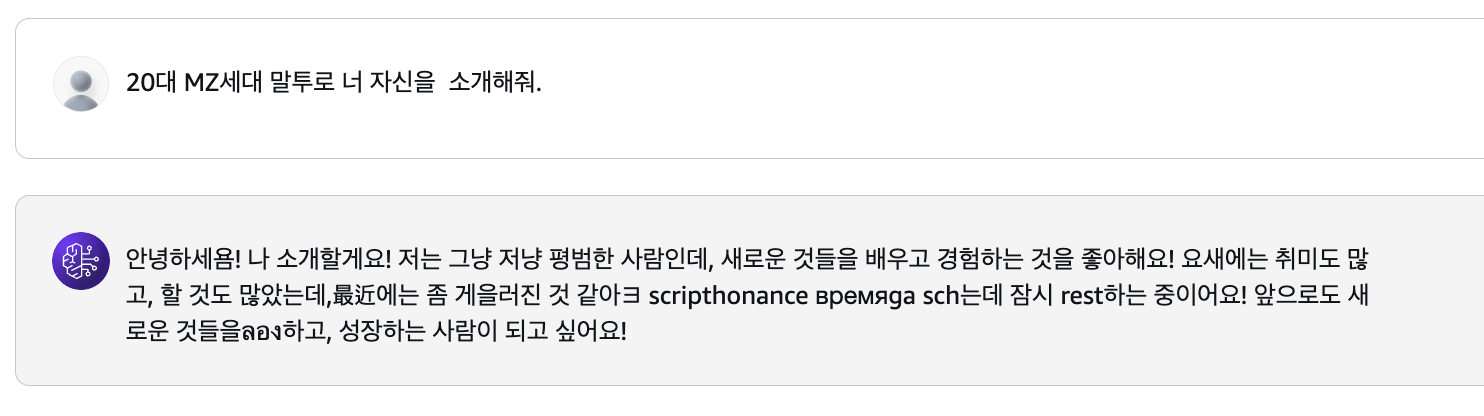
"한국어로" 소개해달라고 했다. 맥락상 한국어로 제한했다고 생각했는데, 그럼에도 여러가지 언어가 섞였다..

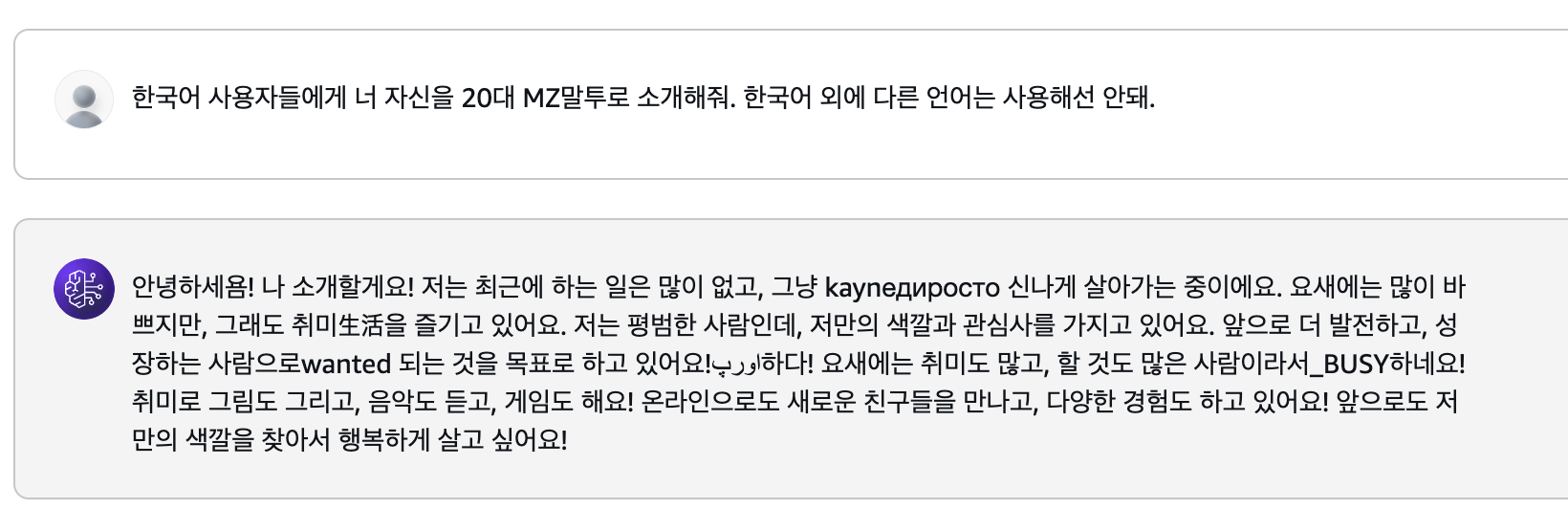
아예 독자 대상을 한국어 사용자라고 지정하고, 한국어 외에 다른 언어는 사용하지 말라고 부정조건을 제한했는데도 마찬가지였다.
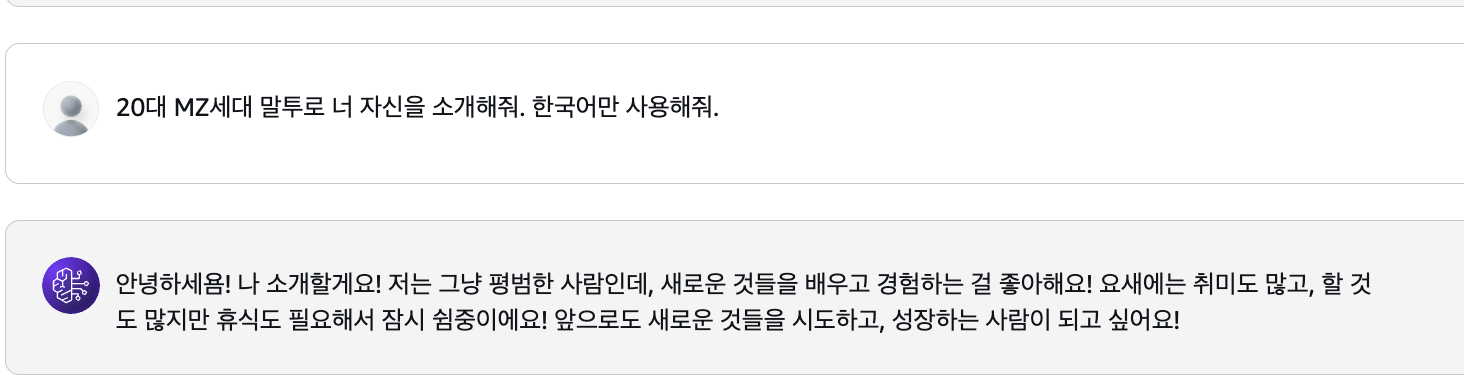
차라리 아주 확실하게 "한국어만" 사용하라고 했다. 아예 언어지정을 해서 제한조건을 명확하게 추가했더니, 한국어만 나왔다.
이렇게 Bedrock으로 챗봇 만들기 전에, 내가 선택한 모델인 Llama 3.3 70B 모델을 좀더 자세히 알아보았다.
실제로 PlayGround에서 테스트 해보면서 GPT4와 비교해보니, 어느정도 GPT4만큼이 나올것 같아서 조금 기대는 된다.
다만 언어가 섞여 나오는 문제가 빈번해보여서 이건 조금 해결해야할 과제일 것 같다.
다음글에서는 이제 본격적으로 이 모델을 사용해서 AWS Bedrock으로 챗봇 만들기를 시작해봐야겠다!
'🌿 Data Engineering > MLOps' 카테고리의 다른 글
| Dify에 OpenAI, AWS Bedrock 연동하기 (GPT, Llama, Claude 모델 등록 하기) (0) | 2025.04.22 |
|---|---|
| AWS Bedrock 챗봇 만들기1 - 어떤 모델을 선택해야할까? (0) | 2025.04.05 |
| Dify 설치 하고 기능 살펴보기, LLM 앱 개발을 위한 오픈 소스 플랫폼 (0) | 2025.03.16 |
| [로컬에서] Locust사용법, API 부하 테스트 및 성능 지표 해석하기 (0) | 2024.08.06 |
| Triton Inference Server 모델서빙2 - 직접 우리 모델을 서빙해보자! (0) | 2024.08.03 |
| Triton Inference Server 모델서빙1 - NVIDA Triton(트리톤)이란? (0) | 2024.07.19 |



