애증의 트리톤..!
성능 테스트까지 해보고 결국 무산되나 싶었지만.. LLM 모델 서빙도 할수 있대서 한번 테스트해봤다.
파이썬 백엔드를 사용해서 onnx, pytorch 모델을 서빙하기 위해 트리톤을 적용해봤다면,
이번에는 트리톤 인퍼런스 서버의 vLLM용 백엔드를 사용해서 어떻게 llm모델을 서빙할수 있을지 알아보려고 한다.
참고로 인프라는 사내 GPU환경에서 진행했고, 모델은 llm 샘플모델을 사용했다.
LLM을 실제 서비스에 활용하고 싶어요!

llm을 사용한 모델 연구를 한창하고 있다.
그러나 실제 서비스에 적용하기까지는 아직 시기상조다.
그 이유는 성능적인 측면 때문이다. (성능,성능, 그놈의 성능이 제일 문제다)
일반적인 개발환경에서 조차 응답을 받을때 여전히 수십초가 걸리며 꽤 많은 리소스가 필요한데,
실제 서비스에 적용하기 위한 과정에서는 어떻게 해야할지 감히 상상도 안된다.
그래서 LLM모델의 추론 속도를 높이기 위해 효율적으로 LLM을 서빙하는 기술이 화두에 올랐다.
그 중 하나로, vLLM과 트리톤 인퍼런스 서버(Triton Inference Server)가 있다.
이 글에서는 간단하게 vLLM과 트리톤 인퍼런스 서버를 소개하고,
vLLM 샘플모델을 트리톤 인퍼런스 서버에 올려서 서빙하는 과정까지 QuickStart로 진행해보려고 한다.
vLLM이란?
Versatile Large Language Model의 약자로,
추론(inference)과 서빙(serving)을 쉽고 빠르게 도와주는 라이브러리이다.
늘 주목받는 프레임워크가 강조하듯이 역시나 높은 성능과 효율적인 비용을 강조한다.
(사실 KV cache, page Attention처럼 두드러진 특징이 있지만.. 일단 요부분은 이번글에서 넘어갈게요)
개인적으로 가장 쉽게 접할수 있고 간단하게 사용할수 있다는게 큰 장점으로 느껴진다.
그래서 냅다 바로 사용해보기로 했다.
vLLM 설치
Python 환경에서 vllm 라이브러리를 pip으로 설치하기만 하면 된다.
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.12 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllm
다만 공식문서에 따르면 아직까지 Linux OS만 지원되는것 같고, python환경 버전에 대한 요구사항도 있다.
그리고 GPU환경을 요구하기에 나는 사내 GPU환경에서 설치해서 사용했다.

실제로 글을 작성하고 있는 현재(25년 1월)을 기준 Mac에서 설치했더니 경우 아래와 같은 이슈로 설치가 되지 않았다.
ERROR: No matching distribution found for torch==2.5.1

vLLM Offline Batched Inference
공식문서에 있는 vLLM QuickStart대로 오프라인 배치추론을 실행해봤다.
여러 입력 프롬프트에 대해 텍스트를 생성할수 있는 것이다.
from vllm import LLM, SamplingParams
-- LLM : 오프라인 추론을 실행하는 주요 클래스
-- SamplingParams : 샘플링과정에서 사용되는 매개변수 지정
2-1. 샘플링 설정 및 입력 정의
프롬프트와 샘플링 매개변수를 정의.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
2-2.LLm엔진 초기화
vLLM엔진과 모델을 초기화. 예제 모델 사용.
llm = LLM(model="facebook/opt-125m")
2-3. 텍스트 생성
llm.generate 사용해서 프롬프트를 vLLM 대기열에 추가하고, outputs 생성.
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
2-4. 출력 예시
예제이지만 프롬프트에 따라 문장을 생성해준다.
Prompt: 'Hello, my name is',
Generated text: 'John Doe.'
Prompt: 'The president of the United States is',
Generated text: 'Joe Biden.'
(추가적으로 API 형태로 배포할수 있다고 하는데 이부분도 추후에 vLLM관련해서 따로 알아보려고 한다)
Triton Inference Server이란?
이전 글 참고. 모델의 효율적인 배포와 운영 지원하는 프레임워크라고 볼수 있다.
2024.07.19-Triton Inference Server 모델서빙1 - NVIDA Triton(트리톤)이란?
Triton Inference Server 모델서빙1 - NVIDA Triton(트리톤)이란?
최근 사내에 GPU를 도입하면서 다양한 ML 모델을 개발하고 있다. 반면 ML 모델 서빙 측면에서는 단순히 FastAPI를 사용하고 있다.알다시피 FastAPI는 파이썬 웹 프레임워크이기 때문에 사실상 모델 서
pearlluck.tistory.com
2024.08.03-Triton Inference Server 모델서빙2 - 직접 우리 모델을 서빙해보자!
Triton Inference Server 모델서빙2 - 직접 우리 모델을 서빙해보자!
https://pearlluck.tistory.com/821 Triton Inference Server 모델서빙1 - NVIDA Triton(트리톤)이란?최근 사내에 GPU를 도입하면서 다양한 ML 모델을 개발하고 있다. 반면 ML 모델 서빙 측면에서는 단순히 FastAPI를 사용
pearlluck.tistory.com
Triton 설치 - vLLM용 Backend
트리톤은 서빙하고자 하는 다양한 모델을 지원한다는 점이 큰 특징이다. 지원되는 모델 중 하나로 LLM이 있다.
onnx, pytorch같은 커스텀한 모델을 서빙하기 위해 Python Backend를 사용했다면,
이번에는 LLM 모델을 서빙하고자 vLLM용 트리톤 백엔드을 사용해볼 것이다.
이 백엔드를 사용한다면 트리톤서버을 통해 받은 요청이 수신되는 즉시 vLLM AsyncEngine에 배치가 된다.
1.설치
사전에 빌드된 도커 이미지 활용한다. 일단 냅다 GPU 서버에서 이미지를 땡겨왔다. (하고 보니 이미지가 22.1G였다;;)
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-vllm-python-py3
# docker pull nvcr.io/nvidia/tritonserver:24.11-vllm-python-py3
참고로 multi-GPU를 사용할수 있고, vLLM은 GPU메모리의 최대 90%를 사용한다.
gpu_memory_utilization 파라미터를 통해 메모리 사용량을 조절할수 있다.
2.실행
2-1. 샘플모델 다운로드
vllm_backend/samples/model_repository/vllm_model at main · triton-inference-server/vllm_backend
Contribute to triton-inference-server/vllm_backend development by creating an account on GitHub.
github.com
트리톤 인퍼런스 서버를 통해 모델을 배포하려면, 꼭 정해진 형식을 따라야한다.
그래서 꼭 / 1 이렇게 아래 모델을 넣고, config.pbtxt 파일이 존재해야한다.
나는 로컬(./vllm_models)에 같은 형식으로 파일을 만들어두었다.
2-2.샘플모델로 트리톤서버 띄우기
트리톤 컨테이너를 띄울 때 --model-repository 뒤에 로컬에 만든 모델레포를 지정해둔다.
docker run --gpus '"device=0"' --rm -p8000:8000 -p8001:8001 -p8002:8002
--shm-size=1G --ulimit memlock=-1 --ulimit stack=67108864
-v ${PWD}:/work -w /work
nvcr.io/nvidia/tritonserver:24.11-vllm-python-py3
tritonserver --model-repository=./vllm_model
트리톤 요청 받을 준비가 되었는지 확인.
요기 8000번 포트로 트리톤 서버에 request를 보내면 추로결과를 response 받을수 있다.

이렇게 모델이름, 버전, 상태가 나오면 재대로 모델이 로드가 된 것이다.
현재 sample이라는 모델이 버전1로 올라가 있고, READY 상태임을 확인할수 있다.

그리고 이렇게 GPU 0번 서버에 트리톤이 띄워져있다.
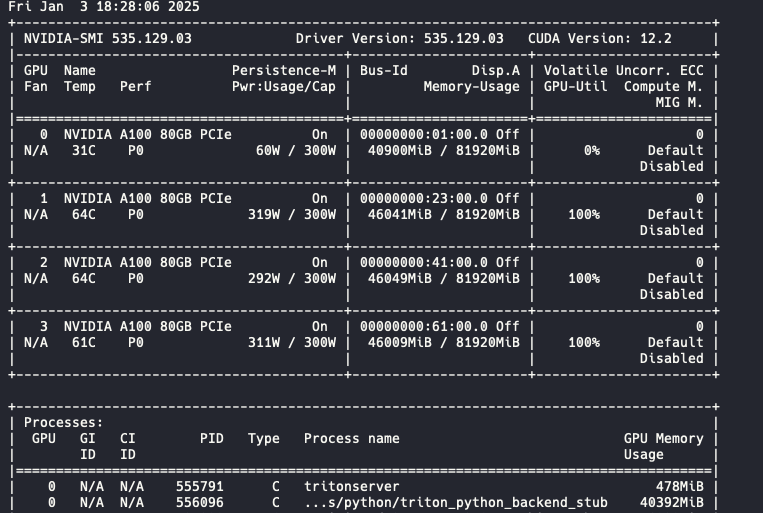
3.추론 요청보내기
지금 서버 내부에서 이렇게 상태확인을 해보면 200인거 확인.
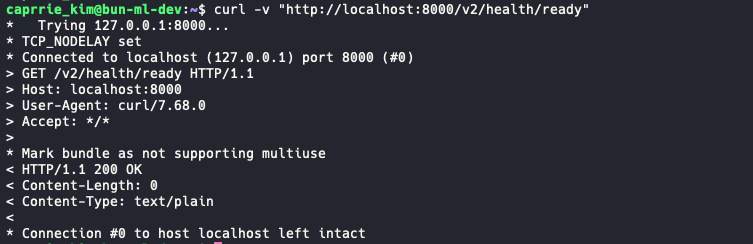
외부에서 GPU에 IP로 접근하고 싶은데 실패했다.왜지 이전에는 됐던거 같은데
어쩔수 없이 그대로 내부에서 요청을 보냈다.
localhost:8000/ v2/models/{model_name}/generate
위 주소로 현재 트리톤 서버에 올린 모델에 대한 추론결과를 response 받는것 같다.
원래는 /infer 이란 주소로 추론결과를 받을수 있는데, vllm 모델의 추론결과라 그런건지 endpoint가 generate이다.
이렇게 text Input 파라미터에 질문을 넣고, parameters에 몇가지 세부조정 값을 넣어서 요청을 보내면 된다.
curl -X POST localhost:8000/v2/models/sample/generate -d '{"text_input": "What is Triton Inference Server?", "parameters": {"stream": false, "temperature": 0}}’
4.추론 응답 확인
우선 parameters에 세부조정값은 기본값으로 넣고, 일단 기본적인 몇가지 샘플 질문을 넘겨 결과를 확인해봤다.
response 결과에는 model_name, model_version, text_output 값이 있는데, text_output에 질문결과를 확인할수 있다.


그리고 이때 이렇게 트리톤 서버에는 이렇게 로그가 남는다.
요청을 보낼때마다 아마 프로프트 처리량 관련해서 토큰당 얼마나 처리했는지에 대한 로그인것 같다.
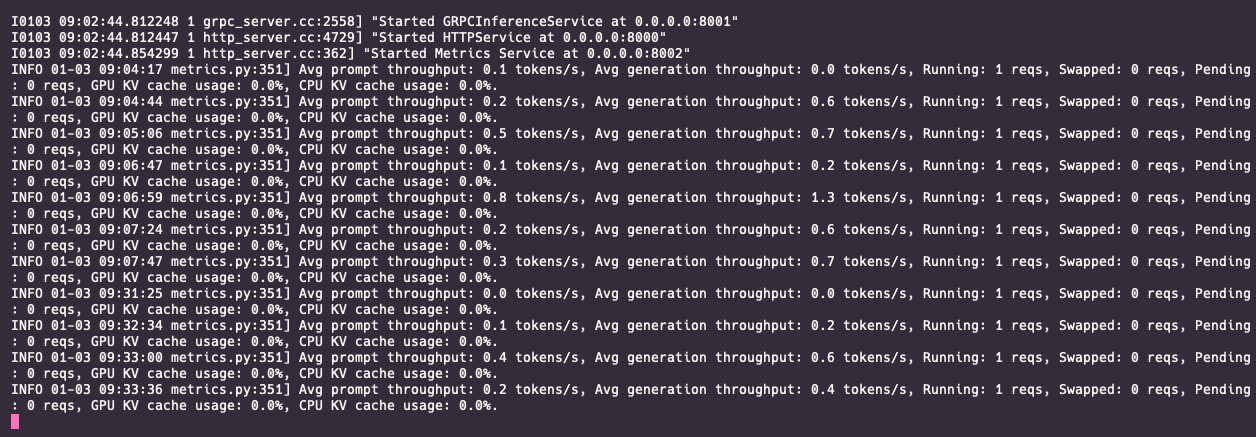
이렇게 vllm과 triton inference Server에 대해 알아보고 간단하게 QuickStart를 해봤다.
다음에는 우리가 개발한 vllm 모델을 트리톤서버 위에 올려 서빙할수 있도록 해보려고 한다!
데이터엔지니어로써 이제는 더이상 llm 서빙기술을 외면할수 없게 되었다...
피하려고 해도 피할수가 없다. 그러니 이제는 두팔 벌려 환영해보자!

'🌿 Data Engineering' 카테고리의 다른 글
| Triton Inference Server 모델서빙3 - 서비스 적용..은 다음에..해보자;; (2) | 2024.10.25 |
|---|---|
| pgVector 기반 VectorDB 구축 및 효율적인 리소스(메모리,스토리지) 사용 (6) | 2024.10.13 |

