최근에 회사에서 elasticsearch를 써먹어보면서 성능튜닝을 몇가지 진행했다.
파라미터들을 조절하면서 결론적으로 뭐 이렇다는걸 대략적으로 보긴했지만 이런 의문이 들었다.
es 성능은 shard개수보다 replica개수에 영향을 준다
왜? why?
특히 es 성능은 shard개수보다 replica개수에 영향을 준다 라는 이야기를 들었는데,
사실 나는 아직 shard랑 replica개념도 안잡혀 있어서
그런데 왜 그런지, 도대체 내부에선 어떻게 동작하길래 그런 결론이 나왔는지
궁금증이 생겨서 조금더 깊게 알아보기로 했다!
내부구조
먼저 전체적인 es의 내부구조를 살펴보면 이렇다.
es가 '클러스터'를 구성한다고 하면 여러개의 '노드'들이 묶여서 있는 모습을 볼 수 있다.
그리고 각 노드에 데이터를 저장하는데 이를 '인덱스'라고 부르고, 각 인덱스에는 한개 혹은 여러개의 '샤드'로 구성된다.

개념정리
1. cluster(클러스터)
노드들의 묶음.
클러스터로 묶인 노드들은 노드간 데이터교환을 위해 http포트(9200-9299), tcp포트(9300-9399)를 열어둔다.
- 데이터교환 : 노드1로 입력된 데이터를 노드2에서 읽을 수도 있고, 그 반대도 가능하다.
하나의 물리서버에 여러개의 노드실행도 가능하지만, 하나의 물리서버에 하나의 노드실행을 권장한다.
물리적인 구성과 상관없이 여러노드가 하나의 클러스터로 묶이기 위해선 노드들끼리 클러스터명이 같아야한다.
같은 서버나 네트워크망 내부에 있다 하더라도, 클러스터명이 다르면 다른 클러스터로 실행이 되고, 각각 별개의 시스템으로 인식된다.
2. node(노드)
클러스터에 묶인 각각의 Elasticsearch를 시작하게 되면, 노드가 생성된다.
이 노드는 동일한 네트워크상에서 클러스터가 존재하는지 확인한다.
없으면 노드가 스스로 클러스터를 생성하고, 있으면 같은 이름을 가진 클러스터에 노드를 연결한다.
3. index(인덱스)
elasticsearch에서는 단일데이터 단위를 도큐먼트(document)라고 부른다.
그리고 이 도큐먼트를 모아놓은 집합을 인덱스(index)라고 부른다. 용어상 데이터 저장단위는 인디시즈(indices)라고 표현한다.
버전7이후부턴 인덱스의 개념을 '테이블'로 보면 된다.
RDB에서 데이터를 모아둔게 테이블인 것처럼, es에서도 데이터 즉 도큐먼트를 모아둔 테이블이 곧 인덱스가 되는 것이다.
그리고 인덱스는 기본적으로 샤드단위로 분리되고 각 노드에 데이터(도큐먼트)를 분산되어 저장한다.
즉 인덱싱을 할때 노드 내부에 논리적으로 데이터 저장공간(샤드)을 만들어 나누면 이제 동시에 여러 데이터를 분산해서 저장할 수 있다.
4. shard(샤드)
클러스터에 노드를 추가하면 샤드들이 각 노드로 분산되고, 디폴트로 1개의 복제본을 생성한다.
이때 청므에 생성된 샤드를 프라이머리 샤드(primary shard), 복제본(replica) 을 리플리카라고 부른다.
샤드는 일종의 파티션과 같은 의미로, 인덱스의 도큐먼트를 분산해서 저장하는 저장소라고 볼 수 있다.
그래서 샤드의 개수에 따라서 노드에 분산해서 저장소를 만들고, 거기에 도큐먼트들을 저장한다.
elasticsearch 7버전 이상부턴 디폴트가 1로 변경되었고, 이전버전 부터는 디폴트가 5개를 가진다.
샤드의 개수는 데이터의 크기가 크다면 디폴트로 유지하는것 권장하고, 응답속도에 맞게 갯수를 늘려야한다.
대신 샤드는 인덱스를 생성할 때만 설정할 수 있다.
샤드가 많을수록 좋은가? No!
쿼리를 수행하면 샤드의 개수만큼 cpu의 스레드 사용 하기때문에 샤드의 개수가 많아질수록 리소스를 많이 사용하는 것!
그래서 작은 데이터일때, 샤드2개랑 샤드1개의 검색속도가 비슷하다고 하면 샤드1개만 사용하는게 더 효율적이다
5. replica(복제본)
primary shard(샤드)의 복제본.
같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장이 된다.
replica(복제본)은 프라이머리 샤드의 개수만큼 생성되며, 인덱스 생성시에만 개수를 설정할 수 있다.
예를 들어, 노드의 개수4, 샤드의 개수 5, replica의 개수1 이라면 아래와 같이 샤드와 replica가 분산되서 저장된다.
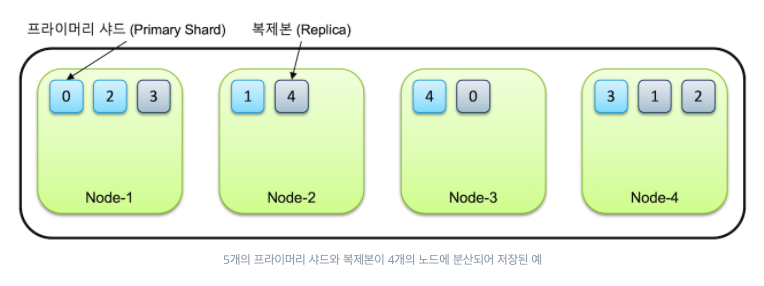
샤드와 replica는 각각 다른노드에 생성되고, 어차피 replica도 또다른 샤드이기 때문에 전체 샤드의 개수는 10개가 된다.
만약 노드의 개수가1개라면?
프라이머리 샤드만 존재하고 복제본은 생성되지 않는다.
그래서 아무리 작은 클러스터라도 데이터가용성과 무결성을 위해 최소 3개의 노드로 구성할것을 권장한다.
replica의 효과 : 가용성 증가
replica는 primary shard와 같은 노드에 존재할 수 없기 때문에
노드 하나가 죽으면, 다른 노드에 있는 복제본에서 데이터를 제공해서
결국 장애복구(fail-over)에 용이하다.
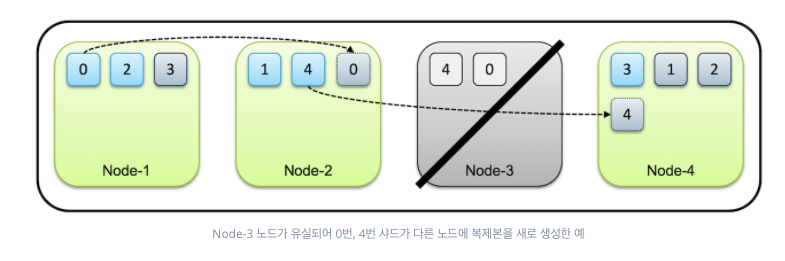
예를 들어, 아래 그림처럼 3번노드가 죽으면 primary shard 4번이랑 replica 0을 잃게 된다.
하지만 primary shard 4는 노드2에, replica 0은 노드2에 존재하기 때문에 데이터를 대체할 수 있다.
즉, elasticseaerch에서 노드가 죽어도 primary shard와 replica 덕분에 데이터를 잃어버리지 않고 데이터 가용성 및 무결성 보장!
출처
https://www.elastic.co/kr/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
How many shards should I have in my Elasticsearch cluster?
Elasticsearch는 다양한 유스케이스를 지원하는 매우 다재다능한 플랫폼이며, 데이터 구성 및 복제 전략에 따라 큰 유연성을 제공합니다. 그러나 이러한 유연성은 여러분 데이터의 효율적인 인덱스
www.elastic.co
https://esbook.kimjmin.net/03-cluster/3.2-index-and-shards
3.2 인덱스와 샤드 - Index & Shards - Elastic 가이드북
인덱스를 생성할 때 별도의 설정을 하지 않으면 7.0 버전부터는 디폴트로 1개의 샤드로 인덱스가 구성되며 6.x 이하 버전에서는 5개로 구성됩니다. 클러스터에 노드를 추가하게 되면 샤드들이 각
esbook.kimjmin.net
https://firework-ham.tistory.com/7
ElasticSearch(일라스틱서치)의 인덱스(index), 샤드(shard), Replica(복제본)에 대해 알아보자.
EasticSearch에 가장 기본이 된다고 생각하는 3가지에 대해서 한번 정리해보려고 합니다. 본 포스팅은 7.x 버전 이후의 EasticSearch를 기준으로 하고 있습니다. 읽기 쉽게 지금부터는 한글로 일라스틱
firework-ham.tistory.com
'🌿 Data Engineering > Study' 카테고리의 다른 글
| 디지털 기술이 사람들의 행동에 미치는 10가지 심리학적 현상 (1) | 2024.07.14 |
|---|---|
| [Elasticsearch] 동작원리, shard와 replica를 몇개로 설정해야하는가? (0) | 2021.12.23 |
| [Kafka] Docker로 Kafka구축하기 | 트위터API사용해서 실시간데이터 전송하기 (0) | 2021.08.11 |
| [Kafka] Docker로 Kafka 구축하기 | Python으로 Producer,Consumer 구현 (0) | 2021.08.11 |
| [Kafka] Docker로 Kafka 구축하기 | Producer에서 Consumer로 메세지 전송 (0) | 2021.08.10 |
| [ELK] Flask 웹로그 분석해보기2-Flask 로그남기기 (0) | 2021.07.09 |



