6월 선정도서 - 빅데이터를 지탱하는 기술
선정계기 - 데이터가 쌓이고 흐르는 전체적인 구조를 깊이 있게 이해할 수 있고,
미래의 데이터엔지니어로써 해야하는 업무들의 전반적인 흐름을 파악할 수 있을 것 같아 선정(기대가 된다

목차
챕터4. 빅데이터의 축적
4-1. 벌크형과 스트리밍형 데이터의 수집
4-2. 메세지 배송의 트레이드 오프
4-3. 시계열데이터의 최적화
4-4. 비구조화 데이터의 분산 스토리지 (Dynamodb/Cassandra/MongoDB/ElasticSearch/Splunk)
데이터를 수집하고, 분산 스토리지에 저장하기까지 프로세스
데이터전송에 벌크형과 스트리밍형 도구가 사용된다.
어떻게 분산스토리지에 이 데이터들이 저장되는지 그 흐름.
객체스토리지
빅데이터는 확장성이 높은 분산스토리지에 저장된다.
대량으로 파일을 저장하기 위한 객체스토리지를 사용한다. (ex: 하둡이라면 HDFS, AWS라면 S3)
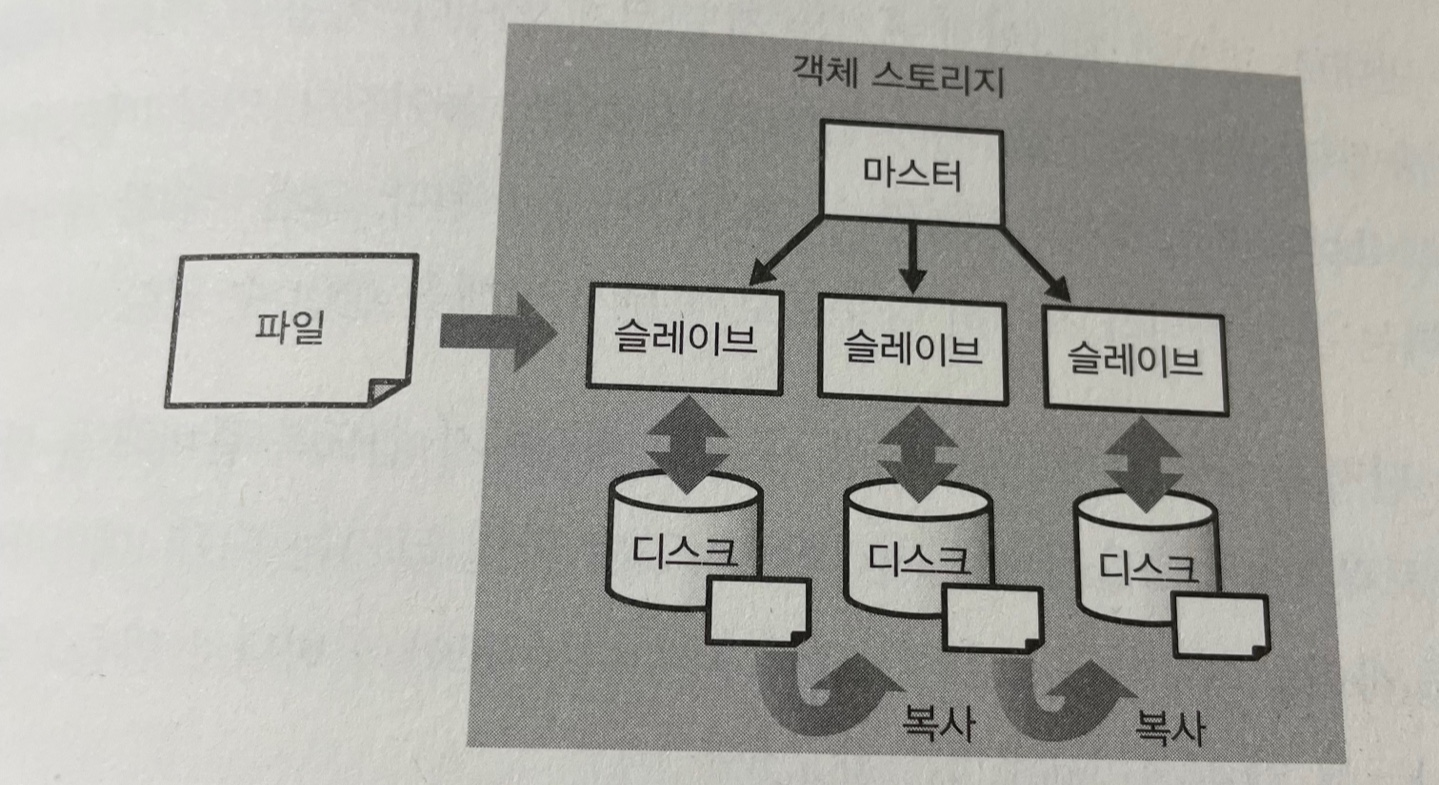
- 객체스토리지에서는 파일 읽고 쓰기를 '네트워크'를 거쳐 실행한다.
- 그 내부처리에 물리적인 서버, 하드디스크가 있는데 데이터들을 항상 여러디스크에 '복사'한다.
- 따라서 일부하드웨어가 고장나더라도 데이터가 손실되지 않는 '부하분산'이 가능하다
- 데이터의 양이 많을때 유용, 소량의 데이터일 경우 데이터양에 비해 통신오버헤드가 커서 비효율적일 수 있다.
객체스토리지에서 효율적으로 처리할 수 있는 크기는 대략 1메가바이트에서 1기가바이트 사이의 범위.
그것보다 작은 데이터는 모아서 하나로 만들고, 그것보다 큰 데이터는 복수로 나누는 것을 고려.
- 작은데이터를 수시로 객체스토리지에 기록하면? 작은파일이 대량생성 성능저하 -> 적당히 모아서 하나의 파일로
- 큰 데이터를 객체스토리지에 기록하면? 네트워크 전송시간이 걸려 오류 -> 적당히 나눠서 여러개의 파일로.
단지 수집만 하는 것이 아니라 나중에 처리하기 쉽도록 준비해야한다.
수집한 데이터를 가공하여 집계효율이 좋은 분산스토리지를 만드는 일련의 프로세스가 데이터 수집이다.
앞서 데이터를 전송하는 방식으로 벌크형과 스트리밍형을 간단하게 알아보았다. 이번엔 본격적 차이점 알아보기!
▼데이터수집/데이터전송(벌크형과 스트리밍형) /데이터처리/데이터가공 전체적인 파이프라인 흐름 개요▼
https://pearlluck.tistory.com/533
[책정리] 빅데이터를 지탱하는 기술 1-2. 빅데이터시대 데이터분석기반
6월 선정도서 - 빅데이터를 지탱하는 기술 선정계기 - 데이터가 쌓이고 흐르는 전체적인 구조를 깊이 있게 이해할 수 있고, 미래의 데이터엔지니어로써 해야하는 업무들의 전반적인 흐름을 파악
pearlluck.tistory.com
벌크형 데이터전송

언제 사용하는가?
전통적인 데이터웨어하우스에서 벌크형 방식을 사용했다.
데이터베이스나 파일서버 또는 웹서비스 등에서 SQL, API 등의 방식으로 정리해 데이터를 추출하고 싶을때 사용
어떻게 데이터를 전송하는가?
데이터전송을 위한 ETL서버가 필요하다.
ETL서버에서 데이터웨어하우스를 위한 ETL도구와 벌크전송 오픈소스, 스크립트 등 사용해서 데이터를 전송한다.
한번에 얼만큼씩 데이터를 전송하면 되나?
벌크형의 도구로 파일사이즈를 적정화한다.
ETL프로세스는 하루마다 또는 1시간마다 정기적으로 실행하므로 그동안 축적된 데이터를 하나로 모아 전송한다.
너무 큰 데이터를 한번에 전송하면 디스크가 넘쳐나 오류가 발생하므로 너무 크면 데이터를 태스크를 분해해 전송한다.
벌크형 데이터전송의 장점은?
1) 데이터 전송의 신뢰성.
스트리밍형은 나중에 재실행하기 쉽지 않은 반면, 벌크형은 문제가 발생했을때 여러번 데이터 전송을 재실행할 수 있다.
2) 워크플로 관리도구와 궁합이 좋다.
스트리밍형은 실시간으로 계속 동작해서 워크플로로 관리하기 어려운 반면,
벌크형은 데이터가 누락되었는지, 실패되었는지, 재실행할것인지 등 워크플로우로 관리하기 쉽다.
스트리밍형 데이터 전송

언제 사용하는가?
계속해서 전송되어 오며 아직 어디에도 저장되지 않은 데이터를 추출하고 싶을때 사용
웹브라우저, 모바일앱, 각종 디바이스에서 생성되고 네트워크를 거쳐 전송되는 데이터를 수집하는 경우 사용
어떻게 데이터를 전송하는가? '메시지 배송'
다수의 클라이언트에서 계속해서 작은 데이터가 전송되는 메시지배송 방식
메시지 배송시스템은 데이터양에 비해 통신을 위한 오버헤드가 커서 높은 성능의 서버가 필요하다.
이때 클라이언트가 계속해서 보낸 메세지를 NoSQL에 저장할 수 있다.
또는 분산스토리지에 직접 쓰는것이 아니라 메세지큐와 메세지 브로커등의 중계시스템에 전송할 수 있다.
이경우 기록된 데이터를 일정한 간격으로 꺼내고 모아서 함께 분산스토리지에 저장한다.
예시1. 웹브라우저에서 메세지 배송

1) 직접 메세지를 만드는 방식.
'웹서버' 안에서 메세지를 직접 만들어서 배송한다.
Logstash, Fluented 같은 서버상주용 로그수집 sw를 사용해 데이터를 축적해놓고 나중에 모아서 보낸다.
2) 자바스크립트 사용.(웹 이벤트 추척)
'웹브라우저'에서 자바스크립트를 사용하여 직접 메세지를 보낸다.
HTML페이지에 태그를 삽입하여 이벤트 데이터 수집 -> 액세스 분석서비스 및 데이터분석 서비스에 사용
수집된 이벤트 데이터는 다른서버로 전송하거나, 분산스토리지에 저장해서 다른데이터와 조합할 수도 있음
예시2. 모바일앱에서 메세지 배송
모바일앱도 웹브라우저와 마찬가지로 HTTP프로토콜을 사용.

1) MBaaS 이용
MBaaS(Mobile Backend as a Service) 라는 백엔드서비스 이용한다.
백엔드 데이터저장소에 저장한 데이터를 벌크형 도구를 사용해 꺼낸다.
2) SDK 이용
SDK(Software Developer Kit)를 이용하여 메세지를 보내는 방식
모바일에 특화된 액세스 해석서비스를 통해 이벤트 데이터 수집
수집된 이벤트 데이터는 일단 SDK의 내부에 축적되고, 온라인 상태가 되었을때 모아서 보낸다.
예시3. 디바이스로부터 메세지 배송(MQTT)
IoT 등 디바이스로부터 메세지전달은 아직 업계표준이란게 없다. 하나의 대표적인 예로 MQTT.

MQTT(MQ Telemetry Transport)
TCP/IP를 사용하여 데이터를 전송하는 프로토콜.
일반적으로 Pub/Sub형 메시지 배송구조를 갖는다. 전달 Publish와 구독 Subscription의 약자.
채팅시스템이나 메시징 앱 또는 푸시알림 등의 시스템에서 자주사용되는 기술.
MQTT의 원리
1. 토픽(Topic)을 만든다. 토픽은 메세지를 송수신하기 위한 대화방
2. 토픽을 구독한다. 구독하면 메세지가 도착한다.
3. 토픽에 메세지를 전달하는 프로그램을 작성한다. 전달하면 구독중인 모든 클라이언트에게 메세지가 보내진다.
이렇게 메세지교환을 중계하는 서버를 MQTT 브로커, 메세지를 수신하는 시스템을 MQTT 구독자 .
MQTT장점
HTTP는 통신오류에 따른 메세지 재전송이 여러번 발생하고,데이터가 중복될 가능성도 높아 이를 스스로 설계해야한다.
반면 MQTT는 네트워크에서 분리된 경우에도 나중에 재전송하는 구조가 프로토콜 수준에서 고려되고 있다.
메세지배송의 공통화
메세지 배송방식은 어디에서 데이터를 수집하느냐에 따라 다르다.
따라서 환경에 따라 공통되는 부분과 다른부분을 분리하여 생각해야한다.
클라이언트 : 메세지가 처음 생성되는 기기
프론트엔드 : 해당 메세지를 먼저 받는 서버. 통신프로토콜 구현, 데이터보호
메세지브로커 : 프론트엔드가 받은 메세지를 받음. // 데이터를 받는것까지만 전념. 이부분이 공통.
백엔드 : 분산스토리지에 데이터를 저장하고, 데이터를 받은 이후 문제해결 처리
'Book & Lesson' 카테고리의 다른 글
| [책정리] 빅데이터를 지탱하는 기술 4.4 비구조화 데이터 분산스토리지 (2) | 2021.06.27 |
|---|---|
| [책정리]빅데이터를 지탱하는기술 4.3 시계열데이터의 최적화 (0) | 2021.06.26 |
| [책정리] 빅데이터를 지탱하는기술 4.2 메세지 배송의 트레이드 오프 (0) | 2021.06.26 |
| [책정리] 빅데이터를 지탱하는 기술 3.3 데이터마트의 구축 (0) | 2021.06.23 |
| [책정리] 빅데이터를 지탱하는 기술 3.2쿼리 엔진 (0) | 2021.06.22 |
| [책정리]빅데이터를 지탱하는 기술 3.1 대규모 분산 처리의 프레임워크 (0) | 2021.06.22 |



