어떤 데이터를 수집할 것인가?
이에 대한 대답을 하기 위해서 어떤 정보를 나타낼것인지 어떤 데이터가 필요한지 정해야한다.
그래서 일단 가장 간단하게 '아티스트명'으로 검색한 '아티스트 정보'를 얻어보려고 한다.
이때 검색을 위해 search API를 쓰려고 한다.
>> API 레퍼런스 https://developer.spotify.com/documentation/web-api/reference/#endpoint-search
Aritist 정보
request형식을 살펴보면
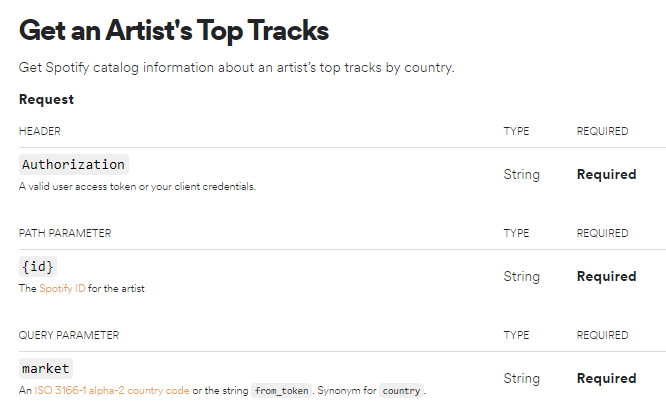
- header : token을 가진 auth
- 쿼리파라미터 : q와 type
이때 type에 해당하는 키워드는 앨범명, 아티스트명, 트랙명 등이 있다.
여러가지 타입으로 키워드가 일치하는 정보를 검색할 수 있는 것이다.
API테스트 >>https://developer.spotify.com/console/get-search-item/?q=tania+bowra&type=artist
respone 값을 살펴보면

얻을 수 있는 실질적인 정보는 items안에 들어있다.
참고로, limit을 1로 정했다. 그래서 items안에는 무조건 하나의 결과만 나온다.
그 이유는 limit이 없다면 BTS로 검색했을때 나오는 아티스트명 결과가 꽤 많다.
BTS멤버별로, 또는 BTS World 등 검색한 이름을 포함한 내용이 여러개 나와서 애매해진다.
그래서 무조건 상위에 검색된걸로 가져오기 위해 limit 1을 걸어두고, items 하나에 대해서 response 한다.
그리고 그 안에서 뽑아볼만한 key를 살펴보면
search_data = search('BTS',token)['artists']
for item in search_data['items']:
print(item.keys())
#dict_keys(['external_urls', 'followers', 'genres', 'href', 'id', 'images', 'name', 'popularity', 'type', 'uri'])
url, followers(팔로워), geners(장르), id(식별자), images(사진), name(이름),popularity(인기), type(타입)가 있다.
- url은 해당정보를 스포티파이 웹버전으로 볼 수 있는 주소이다. pk인 아티스트id를 포함한 주소이다.
- followers(팔로워)는 스포티파이 내부에서 측정하는 팔로워수로 total값을 저장하려고 한다. followers['total']
- genres(장르)는 여러개가 들어갈 수 있다 -> 별개의 테이블로 쪼갠다.
- 아이디는 id -> 아티스트의 PK가 될 것 같다.
- image(이미지)는 검색한 아티스트에 대한 대표이미지로 첫번째 값을 가져올려고 한다 : images[0]['url']
- name(이름)은 검색한 아티스트명으로 name
- popularity(인기)는 언젠가 인기척도?이런거로 구분할 수 있을테니 일단 저장한다
{
"artists":{
"href":"https://api.spotify.com/v1/search?query=BTS&type=artist&offset=0&limit=2",
"items":[
{
"external_urls":{
"spotify":"https://open.spotify.com/artist/3Nrfpe0tUJi4K4DXYWgMUX"
},
"followers":{
"href":"None",
"total":33445866
},
"genres":[
"k-pop",
"k-pop boy group"
],
"href":"https://api.spotify.com/v1/artists/3Nrfpe0tUJi4K4DXYWgMUX",
"id":"3Nrfpe0tUJi4K4DXYWgMUX",
"images":[
{
"height":640,
"url":"https://i.scdn.co/image/ab6761610000e5eb0dd1c51e1a96d5300f730db4",
"width":640
},
{
"height":320,
"url":"https://i.scdn.co/image/ab676161000051740dd1c51e1a96d5300f730db4",
"width":320
},
{
"height":160,
"url":"https://i.scdn.co/image/ab6761610000f1780dd1c51e1a96d5300f730db4",
"width":160
}
],
"name":"BTS",
"popularity":99,
"type":"artist",
"uri":"spotify:artist:3Nrfpe0tUJi4K4DXYWgMUX"
}
"limit":1,
"next":"https://api.spotify.com/v1/search?query=BTS&type=artist&offset=2&limit=2",
"offset":0,
"previous":"None",
"total":89
}
}
참고로 url 주소는 스포티파이 웹에서 볼 수 있는 정보이다.
url의 뒤에는 아티스트이 고유의 id가 있어서, 아티스트마다 페이지가 있는것 같다.

데이터를 어떻게 저장 할 것인가?
이걸 바탕으로 artist에 대한 데이터구조를 설계할 수 있다.
Artist 테이블
| 칼럼명 | JSON에서 값 | 데이터타입 |
| id | id | varchar(255) |
| name | name | varchar(255) |
| followers | followers['total'] | int(11) |
| popularity | popularity | int(11) |
| artist_url | external_urls['spotify'] | varchar(255) |
| image_url | images[0]['url'] | varchar(255) |
그리고 아까 따로 빼놓은 장르
장르는 여러가지가 들어갈 수 있어서 따로 테이블을 만들었다.
이때 아티스트 테이블이랑 장르테이블은 id를 가지고 join할 수 있게 된다.
Genres 테이블
| 칼럼명 | JSON에서 값 | 데이터타입 |
| artist_id | id | varchar(255) |
| genres | genres | varchar(255) |
그래서 한 아티스트에 장르의 개수만큼 데이터를 갖는다.
물론 json형식으로 바로 받아서 NoSQL을 사용해도 된다.
하지만 아티스트에 관련된 내용은 일대일 대응으로 결과를 받기로 결정해서 관계형데이터베이스로 구성했다.
어차피 음악이나 다른 정보들을 NoSQL로 구성하면 여러가지 DBMS도 써볼수 있고 좋을듯!
AWS RDS (MySQL)
위와 같이 설계한 테이블을 RDS에서 또는 로컬DB를 통해 생성하는 작업이 필요하다.
그리고 설게한 테이블에 API를 통해 수집한 데이터를 저장하는 작업도 필요하다.
왜 RDB로 저장하는가?
어떤 DB를 사용할 것인지에 대한 기준을 배울 수 있었다.
- 유저의 측면 : 누가 이 데이터를 사용할 것인가?
- 서비스의 측면 : 어떻게 데이터를 활용할 것인가?
위 두가지에 따라서 데이터를 어디에 저장하고, 어떻게 가공할 것인지가 결정될 수 있다.
물론 구현적인 이유도 있겠지만, 조금더 찾아보니 RDB로 저장하는게 유용한 기준이 있다.
아래의 이유로 데이터를 저장한 곳은 데이터웨어하우스의 특성을 가진다고 볼 수 있다.
- 데이터의 범위가 명확한 데이터를 저장할 경우
- 추후 데이터의 범위가 확장될 가능성이 적은 데이터를 저장할 경우
- 장기적으로 보존이 되어야하는 데이터를 저장할 경우
- 분석환경과 개발환경을 두 환경을 구현함에 있어서 가장 중요한 데이터를 저장할 경우
이를 고려했을떄 아티스트 response를 RDB로 저장한 이유는
가장 기본적이고 근본적인 데이터로 데이터의 범위가 확장될 가능성이 적다고 생각했기 떄문이다.
확장된다는 의미를 테이블의 속성을 변경한다고 이해했다.
그래서 테이블의 구성은 API결과에 따른 값이기 때문에 크게 변할리가 없다고 생각한다.
마찬가지로 데이터의 범위 또한 LIMIT 1로 하나의 결과값을 받기 때문에 어느정도 명확하다고 생각한다.
가장 기본이 되는 데이터이기에 장기적으로 보존이 되고, 가장 중요한 데이터라고 생각이 되서 RDB가 적합한듯하다.
아 그리고 아티스트에 대한 속성값이 생각보다 많은 만큼
아티스트에 대해서'만' 정보를 특별한 가공없이 추출을 할 수 있을 것 같다.
이럴 경우 간단한 분석목적을 가지고 있는 경우 데이터웨어하우스인 동시에 데이터마트의 성격도 가질수 있다고 한다.
출처
https://snepbnt.tistory.com/132?category=784758
'사이드 프로젝트 > 음악추천 챗봇 서비스' 카테고리의 다른 글
| 음악추천챗봇1. Serverless아키텍쳐 구성하기 (0) | 2021.06.07 |
|---|---|
| 음악추천챗봇0. 왜 Serverless아키텍쳐인가? Lambda의 장단점-동시성 (0) | 2021.06.05 |
| 음악추천챗봇3.2 데이터 수집 및 처리-Track정보 (0) | 2021.05.31 |
| 음악추천 챗봇2. 음악데이터 파악하기 | Spotify API 이해 (0) | 2021.05.27 |
| 음악추천챗봇1. 카카오챗봇 설정 | 카카오 i 오픈빌더 API 이해 (0) | 2021.05.27 |
| 음악추천 챗봇0. 서비스기획과 아키텍쳐 설계(Serverless) (0) | 2021.05.25 |



