
[snowflake] Snowflake로 S3에 있는 데이터 COPY 해보기
우리는 redshift를 어떻게 쓰고 있는가?
aws 데이터웨어하우스로 두가지 목적으로 사용하고 있다.
첫번째는 DS의 데이터 분석 작업용, product info나 event log 등 분석하기 위한 테이블들을 저장한다.
두번째는 배치작업용, 실제 서비스화하려는 알고리즘들을 개발하기 위해 대용량 데이터를 처리하는 목적으로 사용한다.
redshift가 힘들어요
점점 데이터분석 작업 뿐만 아니라 배치작업들이 증가하고 있다. 특히나 대부분은 대용량 데이터를 처리하는 경우가 많다.
그런데 이걸 하나의 redshift에서 처리하다보니 redshift가 힘들어하는지 처리시간도 느려지고 물론 비용도 많이 나가고 있다.
그래서 일단은 최대한 여러가지 배치작업들을 동시에 처리하는걸 피하기 위해 배치 주기를 겹치지 않게 조정하고 있다.
하지만 언제까지 이렇게 할 수 없는격..ㅠㅠ 그래서 snwoflake 튜토리얼을 진행해봤다!
snowflake는 뭐가 다른가 ?
SaaS로 데이터웨어하우스를 제공해준다.
그러니까 AWS에서 ec2를 띄워서 가상의 컴퓨팅 서비스를 제공해주는것처럼
snowflake도 컴퓨팅 리소스를 사용해서 가상의 데이터웨어하우스 서비스를 제공해주는 것이다.
서비스로 제공되다보니까 컴퓨팅 리소스 스펙을 직접 조절할 수가 있다.
virtual warehourse는 데이터양에 따라서 다이나믹하게 사이즈를 키우거나 노드수를 추가해서 스펙을 조절할 수 있다.

snowflake 시작하기
아예 콘솔도 익숙하지 않고, 아무것도 모르는 상태로 일단 관리자 계정으로 접속을 했다.
다행히도 스노우플레이크 docs가 잘 나와 있어서 명령어랑 튜토리얼을 보고 따라했다.
그리고 대부분의 데이터베이스 세팅(user/db/schema)이랑 똑같았고, 쿼리도 거의 비슷했다.
1. user 및 role 생성
일단 관리자계정은 admin 권한이라 유저 및 role 생성이 가능했다.
그래서 내가 접속할 유저와 role을 만들고, 그 role안에 user 넣었다. (약간 aws IAM 느낌?)
snowflake는 이렇게 role의 권한관계를 한눈에 그래프로 보여주네..ㅎㅎ
2. 스키마,데이터베이스, 테이블 등 권한부여
직접 user가 아니라 role에게 권한을 부여한다 (이게 맞나?ㅎ)
처음에 권한을 다 주고, 해당 user로 접속했을때 데이터베이스들이 안보여서 뭔가?했는데 기본적으로 USAGE 부터 줘야 보이는거 같다!
그리고 아까 말했다시피 snowflake에서는 컴퓨팅환경을 할당해서 사용해서 warehouse 사용권한도 추가로 부여해줘야한다.
-- warehouse 사용권한부여
GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE [ROLE이름]
-- database 접근,사용권한부여
GRANT USAGE ON DATABASE [데이터베이스명] TO [ROLE이름] ;
-- schema 접근권한부여
GRANT USAGE ON SCHEMA [데이터베이스명].[스키마명] TO [ROLE이름];
-- stage 생성권한부여
GRANT CREATE STAGE ON SCHEMA [데이터베이스명].[스키마명] TO [ROLE이름];
-- table 생성권한부여
GRANT CREATE TABLE ON SCHEMA [데이터베이스명].[스키마명] TO [ROLE이름];
-- 모든 table에 대한 select, upload 권한부여(prod)
GRANT SELECT ON ALL TABLES IN SCHEMA [데이터베이스명].[스키마명]TO ROLE [ROLE이름];
-- S3 integraton 권한부여
GRANT USAGE ON INTEGRATION [Integration명] TO ROLE [ROLE이름]
-- role 권한확인
SHOW GRANTS TO ROLE [ROLE이름];
3. staging 생성
snowflake로 배치작업을 이관하기전에 우선 가장 기본적으로
s3에 있는 dataset을 snowflake로 가지고 오고, snowflake에서 처리하고, 다시 s3로 올리는 작업을 (이게 ETL인가?) 테스트해봤다.
위 작업을 하기 위해서 snowflake는 staging이라는 오브젝트를 사용하는게 특징이다.
즉, 소스(s3같은 외부 스토리지)에서 데이터를 가지고 와서 잠시 저장해둘 위치라고 보면 된다!
데이터를 저장하는 가상의 위치인데, 뭔가 디렉토리 구조처럼 접근할 수 있어서 데이터들을 path형식으로 저장해두는게 아닐까 싶다.
staging을 통해서 데이터의 정확성과 일관성을 보장할 수 있다. source 에서 데이터를 로드하기전에 데이터를 변환한다거나, 오류검사, 품질검증을 staging에서 할 수 있어서 안정적으로 로드하고 처리할 수 있다.
https://docs.snowflake.com/en/sql-reference/sql/create-stage
CREATE STAGE | Snowflake Documentation
IAM user: IAM credentials are required. Temporary (aka “scoped”) credentials are generated by AWS Security Token Service (STS) and consist of three components: All three are required to access a private/protected bucket. After a designated period of ti
docs.snowflake.com
internal staging과 external staging이 있다.
internal staging는 로컬파일처럼 snowflake안에 있는 저장소로, file format이라고 파일을 직접 저장하고, load할수 있다.
external staging는 snowflake 밖에 저장되어 있는 저장소로 AWS, GCP, Azure 같은 클라우드 저장소에 저장하고, load할 수 있다.
테스트의 목적은 우선 s3에 있는 데이터과 transfer하는거라서 external staging을 사용한다.
대신 그러면 storage integration도 필요하다.
CREATE STAGE my_ext_stage
URL='s3://load/files/'
STORAGE_INTEGRATION = myint;
사실 그 이렇게 storage integratoin을 가지고 stage를 만들려고 보니까 assumrole 문제가 있었다..
아마도 IAM에서 snowflake에 해당하는 role에 내가 포함이 안되어 있는 상황인것 같다..
그래서 일단은 임시방편으로 aws scret key, access key를 직접 넣고 stag를 만들었다.
(public bucket이 아니라면 보안상 assume role로 처리하는게 맞을듯?)
DROP STAGE IF EXISTS bun_replica_user_stage;
CREATE OR REPLACE STAGE bun_replica_user_stage
URL = 's3://<s3버킷경로>/'
credentials =(aws_secret_key='<>' aws_key_id='<>');
그리고 s3경로의 끝은 / 로 끝나야한다던데..!
그래야 그 하위경로에 각각의 데이터가 들어가는거라 디텍토리처럼 접근이 가능하다.
SHOW STAGES //현재 스키마에 생성된 stage 목록확인
DESC STAGE [STAGE명] // stage세부정보 확인
list @[STAGE명] // stage 하위 데이터 목록확인
4. stroage integration 생성
테스트의 목적은 우선 s3에 있는 데이터과 transfer하는거라서 external staging을 사용한다.
그래서 아래처럼 stroage integration 를 생성할 수 있다.
CREATE OR REPLACE STORAGE INTEGRATION [Integration명]
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
STORAGE_AWS_ROLE_ARN='arn:aws:iam::<accountID>:role/snowflake'
ENABLED = TRUE
STORAGE_ALLOWED_LOCATIONS = ('s3://<staging로 지정할 경로>/')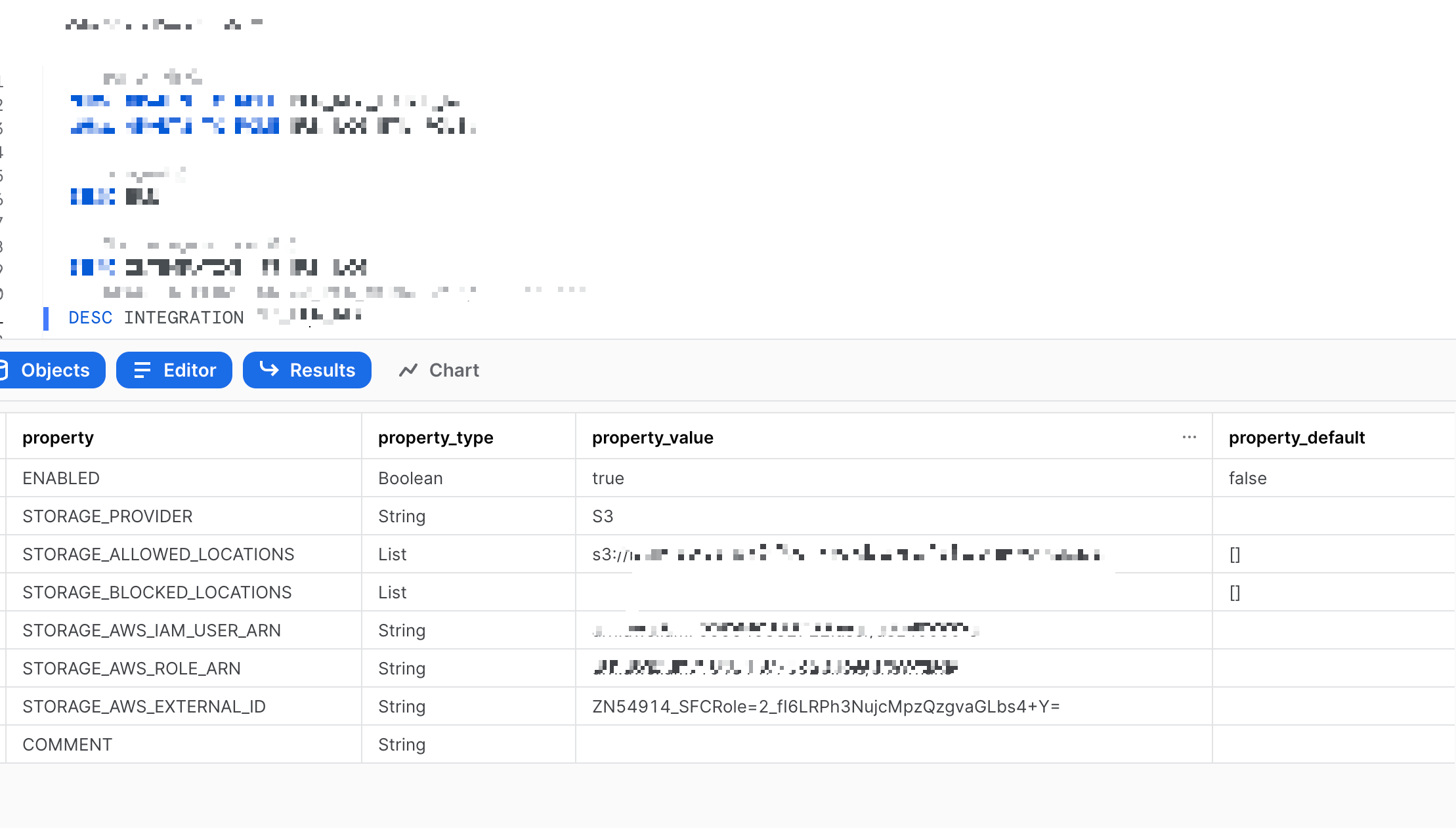
5.table생성
s3의 해당경로에 있는 데이터파일의 타입을 맞춰서 테이블을 생성할 DDL을 작성한다.
CREATE TABLE test_shop (
uid VARCHAR
);
6. s3 -> staging -> table
그럼 이럻게 s3에 있는 데이터를 Snowflake로 저장해서 가지고 올 위치인 staging도 준비가 다 됐다.
이제 snowflake에 저장할 테이블도 준비가 되었으니까, 소스(s3)에서 타켓(snowflake table)로 데이터를 copy해온다.
그런데 이때 소스의 경로를 staging이 가리키고 있으니까,결국에 staging에서 table로 copy하는 명령인것처럼 보인다!
COPY INTO [테이블명] FROM @[스테이징명];
그리고 테이블을 select해보면 해당 데이터가 들어가있는걸 확인할 수 있다!
https://docs.snowflake.com/en/sql-reference/sql/copy-into-table
COPY INTO <table> | Snowflake Documentation
IAM user: Temporary IAM credentials are required. Temporary (aka “scoped”) credentials are generated by AWS Security Token Service (STS) and consist of three components: All three are required to access a private/protected bucket. After a designated pe
docs.snowflake.com
7. snowflake에서 데이터 조작
이렇게 테이블로 가지고 온 데이터들을 가지고 snowflake에서 처리할 수 있다.
이건 알고리즘마다, 쿼리마다 조금 다를수 있고, 시간이 얼마나 걸리는지 한번 redshift랑 비교해봐야할것 같다.
그런데 약간 자잘하게 코드 호환성이 지원되지 않는 부분이 있어서 redshift에서 처리하는 쿼리를 자잘하게 수정했다.
(참고로 chatGPT한테 redshift의 쿼리를 snowflake쿼리로 바꿔줘..도 해봤다...ㅎ)
- invalid identifier 'SYSDATE' : datadadd(day,-90,sysdate) → DATEADD(DAY, -90, SYSDATE())
- unexpected '~' : content_id ~ '^[[:digit:]]+$' →REGEXP_LIKE(content_id, '^[[:digit:]]+$')
- invalid identifier 'YEAR_MONTH_DAY_HOUR' : year_month_day_hour → year||month||day||hour
그런데 몇일째 어떤 데이터부분에서 Numeric value '"4582"' is not recognized 라는 타입에러 때문에 골머리를 앓고있다..
staging 덕분에 데이터 정확성이랑 일관성 보장해준다면서요..내가 staging을 잘 못쓰는거 같은데..ㅠㅠ 왜그럴까...
8. table -> staging -> s3
이렇게 snowflak에서 조작한 데이터를 이제 최종결과물로써 s3에 저장할 수 있다. 이때도 staging을 한번 타고간다.
COPY INTO @[staging이름] FROM [테이블명]
마찬가지로 table결과를 staging으로 올리고, staging이 s3경로를 가리키고 있으니까
결국에 table에서 staging으로 copy하는 명령인것처럼 보인다!
그리고 이렇게 해서 데이터를 s3에 올릴수 있따. 그런데 왜 계속 반복해서 여러개가 올라간걸까.......ㅠㅠ
아무튼간 이번에는 단순히 snowflake 튜토리얼?작업을 해봤다.
외부저장소를 만들고, staging이 s3를 바라보고 있게 만들어서, staging에 있는 데이터를 snowflake 테이블로 copy하는 작업.
반대로 snowflake에서 데이터를 조작하고, 테이블결과를 staging으로 올려서, 결국엔 s3에 unload하는 작업 .
결국 redshift로 하고 있는 몇가지 배치작업들을 snwoflake로 이관하고 배치를 돌려보면서
동시에 여러배치작업을 실행할 수 있을지, 처리시간도 줄어들지, 비용도 줄어들지 등등 얼마나 효과가 있을지 비교해봐야할것같다!