이번엔 파이썬의 한계점과 병렬처리를 통한 성능개선을 알아보고자 한다.
데이터엔지니어에게 필요한 덕?목 중에 하나가 성능을 고려해서 효율적으로 코드를 짜는거랄까..? (아찔훼)

지금 우리 회사에서는 spark 대신 파이썬의 pandas로 대부분의 데이터를 처리한다 (회사와서 spark 쓸 줄 알고 기대했는데)
하지만 점점 데이터의 크기가 커질수록 어느정도 한계를 느꼈고, 이를 개선할수 있는 병렬처리에 대해 찾다가 이글을 쓰게 되었다.
판다스 한계점: 속도도 느리고, 메모리도 많이 잡아먹네?!
판다스의 dataframe은 기본적으로 각각의 row 또는 columns을 순차적(sequential)으로 처리한다.
해당 작업이 완료될때까지 기다렸다가 하나하나씩 처리하는 방식이다.
그래서 데이터의 크기가 커질수록, 처리속도가 기하급수적으로 느려진다.
뿐만 아니라 천만 row를 처리하는데 10기가가 필요할 정도로 메모리 소모도 커진다.
반면 병렬적(parallel)으로 처리하면 순차처리의 한계를 어느정도 개선할 수 있다.
여러단계의 작업을 수행할때 각단계에서 이전작업이 완료되기를 기다리지 않고, 동시에 처리하는 방식이다.
각 단계가 독립적으로 수행되는 작업이면 병렬화가 쉽지만, 단계별로 데이터를 전달하는 동작이 많으면 병렬화가 어려울 수도 있다.
병렬처리를 구현하는 라이브러리가 여러가지가 있는데, 그 중에서 multiprocessing, ray, dask를 알아보도록 하자!
파이썬 표준 병렬처리 방식: multiprocessing
파이썬에서 기본으로 제공해주는 병렬처리 표준 라이브러리이다. (공식문서)
1.동작방식
여러개 프로세스가 동시에 파이썬 인터프리터를 구동하여 동작한다.
프로세스 스포닝(Process spawning)지원해서 부모 프로세스가 OS에 요청해서 자식 프로세스를 생성할 수 있는 것 이다.
각각 별도 코어에서 여러개 프로세스가 파이썬 인터프리터를 동시에 구동하여 병렬처리를 진행한다.
2.구현방식
몇가지 연산처리 함수가 있는데, 이걸 기반으로 코드를 뜯어 고쳐야한다
- pool : 할일을 바닥에 뿌려놓고 ‘알아서’ 분산처리하게 하는 방식
- process : 각 프로세스별로 할당량을 ‘명시적으로 정해두고’ 분산처리를 실행하는 방식
3.특징
- 직렬화 오버헤드 문제가 발생
데이터를 다른 프로세스에 전달할때 pickle을 사용해 직렬화(Serialize)를 하고,
데이터를 다시 받을때는 역직렬화가 필요해서 이때 굉장히 큰 오버헤드가 발생한다.
- 큰 메모리 사용량
각 프로세스마다 데이터 복사본을 만들어야해서 큰 메모리가 필요하다.
프로세스 풀을 안닫고 방치해두면 프로세스가 메모리에 계속 남는 메모리 누수 발생한다.
4.결론 : 코드수정에 드는 리소스가 큰데, 이에 비해 개선되는 성능은 글쎄..?
물론 기본적인 파이썬의 순차처리보다 속도는 빨라지긴 하지만, 메모리를 비롯한 성능개선의 여지가 여전히 남아있다.
성능 가성비 갑! 병렬처리 라이브러리 : ray(레이)
원래는 머신러닝을 위한 분산 머신러닝 라이브러리인데, 파이썬 분산처리에서도 사용한다.
1.동작방식
ray라이브러리의 목적은 분산애플리케이션을 위한 단순하고 범용적인 API를 제공하는 것이다.
그래서 단순히 '코어'를 분리하는 것을 넘어 여러 '머신'에서 작업을 분리하여 병렬처리를 진행한다.
2.구현방식
코드를 뜯어 고칠 필요가 없다!! 구현이 훨씬 간단하다.
병렬처리로 수정하고 싶은 기존함수에 @ray.remote 데코레이터를 추가하고, remote()로 해당 함수를 호출하기만 하면 된다.
데코레이터에 사용할 CPU 또는 GPU를 매개변수 옵션으로 지정할 수도 있고, 함수의 결과를 파이썬 객체로도 반환할 수 있다.
3.특징
- 직렬화 오버헤드 문제가 발생하지 않음
행(row)기반이 컬럼(columns) 기반의 인메모리(in-memory) 포맷인 Apache Arrow를 사용하여
직렬화된 데이터를 전달하기 때문에 오버헤드문제를 해결할 수 있다. - 처리속도가 빠르다
직렬화된 데이터를 인메모리 객체 저장소(in-memory object store)인 Plasma에 저장하기 때문에
데이터를 빠르게 공유할 수 있다. - 물리적 코어가 늘어날 수록 처리속도가 압도적으로 좋다.
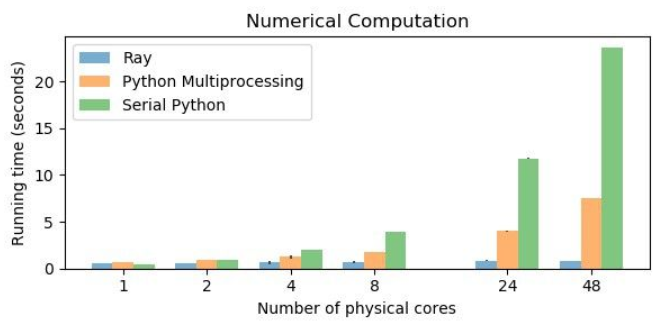
4.결론 : 코드수정에 드는 리소스가 적은거에 비해, 개선되는 성능(처리속도)이 좋다.
multiprocessing보다 구현이 간단하고, 직렬화 오버헤드 문제점도 개선할 수 있기 때문에 처리속도를 개선하기 위한 목적이라면 ray를 쓰는편이 나을 것 같다. 다만 메모리 측면의 개선은 아직 잘 모르겠다.
가상 메모리로 메모리 절약!병렬처리 라이브러리 : dask(다스크)
ray와 마찬가지로 파이썬 분산처리에서 많이 사용하는 라이브러리이다.(공식문서)
1. 동작방식
가상의 데이터프레임을 사용해 모든 데이터가 메모리상에 로드되지 않은 채 처리한다.
파티션을 나눠 메모리에 순차적으로 올리고 내리면서 연산을 하는 방식으로 동작한다.
2. 구현방식
numpy, array, list, dataframe 등 dask 자체적인 데이터구조를 사용한다.
3. 특징
- 메모리 효율이 좋다.
가상의 데이터프레임을 사용하여 가상메모리 영역에 저장하기 때문에 대용량 데이터라도 적은 메모리로 빠르게 읽어올 수 있다. - 중앙화 스케쥴러
ray는 분산형 스케쥴러로 각 머신이 자체 스케쥴러를 실행하는데,
dask는 중앙화 스케쥴러로 클러스터를 위한 모든 작업을 중앙에서 처리한다. - pandas보다 느리다던데..?
4.결론 : 코드수정에 드는 리소스는 어느정도 있지만, 개선되는 성능(메모리효율)이 좋다.
코드를 전부 뜯어 고치는게 아니라 데이터구조만 수정해서 메모리를 효율적으로 사용할 수 있다. 그래서 메모리가 중요한 개선 포인트라면 dask를 쓰는편이 나을 것 같다. 다만 처리속도 측면에선 더 느려질 수 있다.
다음글에서는 같은 데이터를 가지고, 각각 라이브러리별로 구현하여 실제로 어떻게 차이가 나는지 확인해보려고 한다!
참고
mutliprocessing
https://jonsyou.tistory.com/27
ray
https://zzsza.github.io/mlops/2021/01/03/python-ray/
https://velog.io/@otzslayer/Ray를-이용해-Python-병렬-처리-쉽게-하기
'Computer Science > Programming' 카테고리의 다른 글
| 🧐 파이썬 코드를 잘 짜는 법 : 의존성 주입(dependency injector) (0) | 2022.08.08 |
|---|---|
| 🧐 파이썬 코드를 잘 짜는 법 : 메모리 구조와 메모리 할당방식 이해 (0) | 2022.08.01 |
| [Git] 실무에서 은근히 유용한 git stash와 git squash (1) | 2022.07.10 |
| [Git] merge말고 rebase를 사용해야하는 이유, Rebase vs Merge (1) | 2022.05.29 |
| [Test] mypy로 python 타입 검사하기 (0) | 2022.03.24 |
| [Test] python 테스트코드의 필요성(feat.pytest) (0) | 2022.03.23 |



